Web Scraping – что это такое и зачем он нужен
Каталог товаров, спортивная статистика, цены на офферы… Что-то знакомое, правда? Эти и другие вещи собирают с помощью специальных софтов или вручную в документы. Там информация структурирована; нет необходимости разбираться что и где.
Если вас заинтересовал такой метод, подумайте о веб-скрейпинге.
Что такое веб-скрейпинг?
Web scraping – процесс сбора данных с помощью программы, то есть в автоматическом режиме. В русскоязычном пространстве этот процесс называют парсингом. А программу – парсером. Точно так же как за бугром говорят to scrape web page, у нас – парсить страницу. Так что если изучаете материал на английском, не переводите как “скрабить”, “скрабы” и так далее 🙂
Как работает веб-скрейпинг?
Запускаете программу и загружаете в нее адреса страниц. А еще наполняете софт ключевыми словами и фразами, блоками и числами, которые нужно собрать. Эта программка заходит на указанные сайты и копирует в файл все, что найдет. Это может быть файл CSV-формата или Excel-таблица.
Когда программа закончит работу, вы получите файл, в котором вся информация будет структурирована.
Для чего он нужен?
С помощью веб-скрейпинга собирают нужные данные. Например, у вас новостное агентство и вы хотите проанализировать тексты своих конкурентов на конкретную тематику. Какую лексику они используют? Как подают информацию? Конечно, найти такие статьи можно вручную, но проще настроить программу и поручить эту задачу ей.
Или так: вы любитель литературы и сейчас страшно хотите найти информацию о болгарских поэтах. На болгарском. В болгарском интернете информации о болгарской литературе в принципе мало, и поэтому штудировать каждый сайт – долго. В таком случае есть смысл обратиться к парсеру. Загоняете в программу ключевые слова и фразы, по которым она будет искать материал о поэтах, – и ждете, пока софт завершит работу.
То есть парсить информацию могут все, кто захочет. В основном этим занимаются те, кому нужно проанализировать контент конкурентов.
Зачем нужны прокси для веб-скрейпинга?
В web data scraping вы не обойдетесь без прокси. Есть две причины использовать промежуточные серверы.
Если обновляете страницу определенное количество раз, на ней срабатывает антифрод-система. Сайт начинает воспринимать ваши действия как DDoS-атаку. Итог – доступ к странице закрывается, вы не можете зайти на нее.
Парсер делает огромное количество запросов на сайт. Поэтому в любой момент его работу может остановить антифрод-система. Чтобы успешно собрать информацию, используйте даже несколько IP-адресов. Все зависит от того, какое количество запросов необходимо сделать.
Некоторые сайты защищаются от веб-скрейпинга как могут. А прокси помогают эту защиту обойти. Например, вы парсите информацию из буржевых сайтов, а у них стоит защита. Когда программа захочет скопировать содержимое страниц в таблицу, она сможет это сделать, но ресурс отдаст вам информацию на русском – не на английском.
Чтобы обойти такую антифрод-систему, используют прокси того же сервера, на котором расположен сайт. Например, парсить инфу с американского веб-ресурса нужно с американским IP.
Какие прокси использовать?
Покупайте платные прокси. Благодаря ним вы обойдете антифрод-системы сайтов. Бесплатные не дадут вам этого сделать: веб-ресурсы уже давно занесли бесплатные айпи в блэклисты. И если сделаете огромное количество запросов с публичного адреса, в какой-то момент произойдет следующее:
Во втором случае вы сможете спокойно скрайпить и дальше, но нужно будет при каждом новом обращении к странице вводить капчу.
Иногда достаточно одного запроса, чтобы сайт закрыл доступ или попросил ввести капчу. Так что вывод один: только платные промежуточные серверы.
Купить недорогие прокси для веб-скрейпинга вы можете на нашем сайте. Если не будет получаться настроить его или возникнут другие вопросы – пишите. Саппорт онлайн 24/7. Отвечает в течение 5 минут.
А сколько их должно быть?
Точно сказать, сколько использовать прокси для веб-скрейпинга, нельзя. У каждого сайта свои требования, а у каждого парсера в зависимости от задачи будет свое количество запросов.
300-600 запросов в час с одного айпи-адреса – вот примерные лимиты сайтов. Будет хорошо, если отыщете ограничение для ресурсов с помощью тестов. Если у вас нет такой возможности – берите среднее арифметическое: 450 запросов в час с одного IP.
К каким программам обратиться?
Инструментов для парсинга много. Они написаны на разных языках программирования: Ruby, PHP, Python. Есть программы с открытым кодом, где пользователи вносят изменения в алгоритм, если нужно.
Для вас – самые популярные программы для веб-скрейпинга:
Найдите подходящий софт для себя. А еще лучше – попробуйте несколько и выберите из них лучший.
А это законно?
Если боитесь собирать данные с сайтов, не стоит. Парсинг – это законно. Все, что находится в открытом доступе, можно собирать.
Например, вы можете спокойно спарсить электронные почты и номера телефонов. Это личная информация, но если пользователь сам публикует ее, претензий уже не может быть.
Заключение
Благодаря веб-скрапингу пользователи собирают каталоги товаров, цены на эти товары, спортивную статистику, даже целые тексты. Парсинг без блокировки – это реально: достаточно просто закупиться IP-адресами и менять их.
15 топовых веб скрапинг решений 2021 года
Веб скрапинг позволяет компаниям автоматизировать процессы сбора веб данных с помощью ботов или автоматизированных скриптов, называемых веб-сканерами и загружать эти данные в формате Excel, CSV или XML для последующей аналитики.
Представляем вашему вниманию список топ 15 инструментов для парсинга 2021 года.
Scraper API
Scraper API позволяет получить содержимое HTML с любой страницы с помощью вызова API. С Scraper API можно с легкостью работать с браузерами и прокси-серверами и обходить проверочные код CAPTCHA. Единственное на что необходимо сосредоточиться это превращение веб-сайтов в ценную информацию. С этим иснтрументом практически невозможно быть заблокированным, так как он меняет IP-адреса при каждом запросе, автоматически повторяет неудачные попытки и решает капчу за вас.
Octoparse
Octoparse это бесплатный инструмент предназначенный для веб скрапинга. Он позволяет извлекать данные с интернета без строчки кода и превращать веб-страницы в структурированные данные всего за один клик. Благодаря автоматической ротации IP-адресов для предотвращения блокировки и возможности планирования последующего скрапинга этот инструмент является одним из самых эффективных.
DataOx
DataOx— настоящий эксперт в области скрапинга веб-страниц. Инструменты предлогаемые компанией DataOx обеспечивают крупномасштабные сборы данных и предоставляют комплексные решения адаптированные к потребностям клиентов. Этой компании могут доверять как стартапы, создающие продукты на основе данных, так и большие предприятия, которые предпочитают поручать сбор собственных данных профессионалам.
ScrapingBot
Scraping-Bot.io предлагает мощный API для извлечения HTML-содержимого. Компания предлагает API-интерфейсы для сбора данных в области розничной торговли (описание продукта, цена, валюта, отзыв) и недвижимости (цена покупки или аренды, площадь, местоположение). Доступные тарифные планы, JS-рендеринг, парсинг с веб-сайтов на Angular JS, Ajax, JS, React JS, а также возможность геотаргетинга делают этот продукт незаменимым помощником для сбора данных.
Wintr
Wintr это API для парсинга веб-страниц, использующий вращающиеся резидентные прокси, позволяющий извлекать и анализировать любые данные доступные в сети. Простой в использовании и полностью настраиваемый Wintr включает множество инструментов для сбора данных даже с самых сложных веб-сайтов. Например, можно легко извлечь содержимое с общедоступной веб-страницы с помощью ротационного IP-адреса или автоматизировать аутентификацию с помощью Javascript рендеринга, а затем извлечь личные данные с помощью файлов cookie и постоянного IP-адреса.
Import.io
Webhose.io
Webhose.io это расширенный API сервис для извлечения веб данных в реальном времени. Это инструмент очень часто изпользуют для извлечения исторических данных, мониторинга СМИ, бизнес-аналитики, финансового анализа, а также для академических исследований.
ParseHub
Mozenda
Mozenda это корпоративное программное обеспечение разработанное для всех видов задач по извлечению данных. Этой компании доверяют тысячи предприятий и более 30% компаний из списка Global Fortune 500. Это один из лучших инструментов для парсинга веб-страниц, который поможет за считанные минуты создать скрапер агента. Mozenda также предлагает функции Job Sequencer and Request Blocking для сбора веб-данных в реальном времени и лучший сервис для работы с клиентами.
Diffbot
Diffbot автоматизирует извлечение веб-данных с помощью искусственного интеллекта и позволяет легко получать различные данные с любого сайта. Вам не нужно платить за дорогостоящий парсинг веб-страниц или делать это в ручную.
Этот инструмент поможет увеличить объем скрапинга до 10 000 доменов, а функция Knowledge Graph предоставит точные, полные и подробные данные с любого интернет источника.
Luminati
Luminati предлагает инструмент для сбора данных нового поколения, который позволяет получать автоматизированный и настраиваемый поток данных с помощью одной простой панели управления. Необходимо только отправить запрос, а всем остальным: IP-адресами, заголовками, файлами cookie, капча будет управлять система. С Luminati вы получите структурированные данные с любого веб-сайта, от тенденций в электронной коммерции и данных с социальных сетей до исследований рынка и конкурентной разведки.
FMiner
FMiner это программное обеспечение для парсинга веб-страниц, извлечения веб-данных, веб-сканирования и поддержки веб-макросов для Windows и Mac OS X. Этот простой в использовании инструмент извлечения данных сочетает в себе лучшие в своем классе функции от простых задач до комплексных проектов по извлечению данных, требующими ввода форм, списков прокси-серверов, обработки Ajax и многоуровневого сканирования веб страниц.
Outwit
Data streamer
Data Streamer помогает получать контент из социальных сетей. Это один из лучших веб-парсеров, который позволяет извлекать важные метаданные с помощью NLP. Встроенный полнотекстовый поиск на базе Kibana и Elasticsearch и простая в использовании и всеобъемлющая консоль администратора обеспечивает эффективный сбор необходимой информации.
Скрапинг современных веб-сайтов без headless-браузеров

Многие разработчики считают скрапинг сложной, медленной и неудобной для масштабирования задачей, особенно при работе с headless-браузерами. По моему опыту, можно заниматься скрапингом современных веб-сайтов даже не пользуясь безголовыми браузерами. Это очень простой, быстрый и хорошо масштабируемый процесс.
Для его демонстрации вместо Selenium, Puppeteer или любого другого решения на основе безголовых браузеров мы просто используем запросы на Python. Я объясню, как можно скрапить информацию из публичных API, которые потребляет на фронтэнде большинство современных веб-сайтов.
На традиционных веб-страницах наша задача заключается в парсинге HTML и извлечении нужной информации. На современных веб-сайтах фронтэнд скорее всего не будет содержать особо много HTML, потому что данные получаются асинхронно после первого запроса. Поэтому большинство людей использует безголовые браузеры — они способны выполнять JavaScript, делать дальнейшие запросы, после чего можно распарсить всю страницу целиком.
Но существует и другой способ, которым можно довольно часто пользоваться.
Скрапинг публичных API
Давайте разберёмся, как можно использовать API, которые веб-сайты применяют для загрузки данных. Я буду скрапить обзоры продукта на Amazon и покажу, как вам сделать то же самое. Если вы повторите описанный мной процесс, то удивитесь, насколько просто его подготовить.
Наша задача — извлечь все обзоры конкретного продукта. Чтобы повторять за туториалом, нажмите сюда или найдите любой другой продукт.

Наша задача — извлечь как можно больше информации. Помните, когда занимаетесь скрапингом данных, жадность наказуема. Если не извлечь какую-то информацию, то придётся выполнять весь процесс заново, просто чтобы добавить ещё немного данных. И поскольку самой тяжёлой частью скрапинга являются HTTP-запросы, обработка не должна занимать много времени, однако необходимо постараться минимизировать количество запросов.
Перейдя на страницу продукта и нажав на «ratings», а затем выбрав «See all reviews», мы увидим следующее:
Это отдельные обзоры. Наша задача — извлечь информацию с этой страницы без использования безголового браузера для рендеринга страницы.
Процесс прост — для него потребуются браузерные инструменты разработчика. Нужно заставить сайт обновить обзоры, чтобы найти возвращающий их запрос. Большинство браузеров после открытия инструментов разработчика отслеживает сетевые запросы, поэтому откройте их перед выполнением обновления.
В данном случае я изменил сортировку с «Top Reviews» на «Most Recent». Взглянув на вкладку Network, я вижу только один новый запрос, то есть обзоры получаются из этого запроса.
Поскольку на страницах выполняется отслеживание и аналитика, иногда при каждом нажатии мышью будет создаваться несколько событий, но если просмотреть их, то вы сможете найти запрос, получающий нужную информацию.
Следующим шагом будет переход на вкладку Response, чтобы понять, в каком формате принимаются обзоры.
Часто запросы бывают в читаемом формате JSON, который можно легко преобразовывать и хранить.
В других случаях, например, в нашем, всё чуть сложнее, но задача всё равно решаема.
Этот формат непохож на HTML, JavaScript или JSON, но обладает очень понятным шаблоном. Позже я покажу, как мы можем использовать код на Python для его парсинга, несмотря на странность этого формата.
После первоначальной подготовки настала пора перейти к коду. Вы можете запросто писать код для запросов на любимом языке программирования.
Для экономии времени я люблю использовать удобный конвертер cURL. Сначала я копирую запрос как cURL, дважды щёлкнув на него и выбрав «Copy as cURL» (см. скриншот выше). Затем я вставляю его в конвертер, чтобы получить код на Python.
Примечание 1: Существует множество способов выполнения этого процесса, я просто считаю данный способ наиболее простым. Если вы просто создаёте запрос с использованными заголовками и атрибутами, то это вполне нормально.
Примечание 2: Когда я хочу поэкспериментировать с запросами, я импортирую команду cURL внутрь Postman, чтобы можно было поиграться с запросами и понять, как работает конечная точка. Но в этом руководстве я буду выполнять всё в коде.
В данных post мы передаём большинство параметров в неизменном виде. Вот одни из самых важных параметров:
Чтобы понять, что делает каждый параметр в недокументированном API, нужно вызвать обновления страницы и понаблюдать за изменениями каждого из параметров.
Важное примечание о pageSize : этот параметр позволяет нам снизить количество запросов, необходимых для получения нужной информации. Однако обычно никакой API не позволяет вводить произвольный размер страницы. Поэтому я начал с 10 и добрался до 20, после чего количество результатов перестало увеличиваться. То есть максимальный размер страницы равен 20, его мы и используем.
Примечание: При использовании нестандартных размеров страниц вы упрощаете веб-сайту задачу вашей блокировки, поэтому будьте аккуратнее.
Следующий шаг — понять, как работает пагинация и циклическая передача запросов. Существует три основных способа обработки пагинации:
Для этого нам нужно добраться до последней страницы и посмотреть, что произойдёт. В нашем случае простым индикатором последней страницы является отключенная кнопка «Next Page», как видно на показанном ниже скриншоте. Мы запомним это, чтобы прерывать цикл при написании кода.
Теперь давайте пройдём по всем страницам и соберём информацию. Кроме того, я покажу, как парсить фрагменты HTML при помощи Beautiful Soup 4.
Давайте разобьём этот код на части и посмотрим, что он делает:
Затем мы одну за другой обработаем каждую строку. Некоторые строки относятся к верхней и нижней частям страницы и не содержат обзоров, поэтому можно их спокойно пропустить. В конце нам нужно извлечь нужную информацию из самих обзоров:
Теперь настало время объяснить, как можно парсить тексты из HTML, для чего потребуется знание селекторов CSS и простейшей обработки.
Я не буду вдаваться в подробности, моя задача — объяснить процесс, а не конкретную реализацию с Beautiful Soup или Python. Этот процесс можно повторить на любом языке программирования.
Текущая версия кода обходит страницы и извлекает звёзды, имя профиля, дату и комментарий из каждого обзора. Каждый обзор хранится в списке, который можно сохранить или подвергнуть дальнейшей обработке. Поскольку скрапинг запросто в любой момент может прерваться, важно часто сохранять данные и обеспечить удобный перезапуск скраперов с места, где произошёл сбой.
Если бы это был реальный пример для работы, то нужно было бы добавить довольно много других аспектов:
Не забывайте скрапить с уважением — добавляйте задержки между запросами и минимально используйте параллельные запросы к одному домену. Цель веб-скрапинга — доступ к информации и её анализ, чтобы создать на её основе что-то полезное, а не вызвать проблемы и торможение серверов.
На правах рекламы
Серверы для парсинга или любых других задач на базе новейших процессоров AMD EPYC. Создавайте собственную конфигурацию виртуального сервера в пару кликов.
Безопасный веб-скрейпинг: как извлекать данные с сайтов, чтобы вас не заблокировали
Авторизуйтесь
Безопасный веб-скрейпинг: как извлекать данные с сайтов, чтобы вас не заблокировали
Автор — Мария Багулина
Чтобы получить данные с сайтов, используется готовый API, однако он не всегда доступен. Тогда приходится использовать «парсер» веб-страницы — в автоматическом или полуавтоматическом режиме распознавать код и получать данные из необходимых полей. Обходом множества страниц и сайтов занимается ПО, которое обычно называется «краулер».
Процесс сбора данных с сайтов краулером называется веб-скрейпингом.
Большинство популярных сайтов активно защищают свои ресурсы от скрейпинга используя распознавание IP-адреса, проверку заголовков HTTP-запросов, CAPTCHA и другие способы. Но скрейперы не отстают от них и придумывают новые стратегии обхода. Вот несколько советов, как скрейпить без блокировок.
Задайте случайные интервалы между запросами
Ни один реальный человек не станет отправлять запросы на сайт каждую секунду в течение 24 часов — такой сбор информации очень легко обнаружить. Используйте случайные задержки (например около 2–10 секунд), чтобы избежать блокировки. И не отправляйте запросы слишком часто, иначе сканирование сайта будет походить на сетевую атаку.
Особо щепетильным стоит проверить файл robots.txt (как правило, находится на http:// /robots.txt). Иногда там можно найти параметр Crawl-delay, который говорит, сколько секунд нужно подождать между запросами, чтобы не вредить работе сервера.
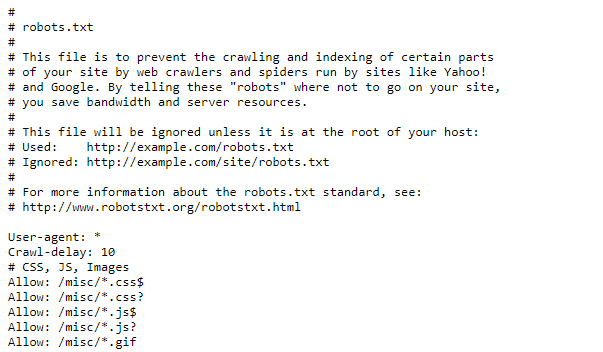
Установите адекватный User Agent
User Agent — HTTP-заголовок, который сообщает посещаемому веб-сайту информацию о вашем браузере. Если не настроить User Agent, вашего краулера будет очень легко обнаружить. Кроме того, сайты иногда блокируют запросы пользовательских агентов от неизвестных браузеров. Поэтому не забудьте установить один из популярных пользовательских агентов (например из этого списка).
Опытные скрейперы могут попробовать установить свой агент на Googlebot User Agent — поисковый робот Google. Большинство веб-сайтов, очевидно, хотят попасть в выдачу Google и пропускают Googlebot.
Хорошей практикой будет также чередование разных User Agent.
Используйте прокси
Вряд ли настоящий пользователь сможет запрашивать 20 страниц в секунду на одном и том же сайте. Чтобы «обмануть» веб-сервер, заставьте его думать, что все эти запросы приходят из разных мест. Другими словами, используйте прокси.
Тут есть множество вариантов, например сервисы SmartProxy, Luminati Network, Blazing SEO. Бесплатные прокси не всегда подойдут для таких целей: они часто медленные и ненадёжные. Также можно создать свою прокси-сеть на сервере, например с помощью Scrapoxy — API с открытым исходным кодом.
Добавьте referer
Referer — заголовок HTTP-запроса, который даёт понять, с какого сайта вы пришли. Неплохой вариант — сделать так, чтобы он показывал, будто вы перешли из Google:
Стоит менять referer для веб-сайтов в разных странах: например для России использовать https://www.google.ru/, а не https://www.google.com/. Вместо Google можно подставить адреса соцсетей: Youtube, Facebook, ВКонтакте. Referer поможет сделать так, чтобы запросы выглядели как трафик с того сайта, откуда обычно приходит больше всего посетителей.
Используйте headless-браузер
Особо хитроумные сайты могут отслеживать веб-шрифты, расширения, файлы cookie, цифровые отпечатки (фингерпринты). Иногда они даже встраивают JavaScript-код, открывающий страницу только после его запуска — так зачастую можно определить, поступает ли запрос из браузера. Для обхода таких ресурсов вам потребуется headless-браузер. Он эмулирует поведение настоящего браузера и поддерживает программное управление. Чаще всего для этих целей выбирают Chrome Headless.
Если ресурс отслеживает цифровой отпечаток браузера, то даже многократная смена IP и очистка cookie не всегда помогают, так как вас всё равно могут узнать по фингерпринту. За частую смену IP при одном и том же отпечатке вполне могут заблокировать, и одна из задач Chrome Headless — не допустить этого.
Самый простой способ работать с Chrome Headless — использовать фреймворк, который объединяет все его функции в удобный API. Наиболее известные решения можно найти тут. Но некоторые веб-ресурсы пытаются отслеживать и их: идёт постоянная гонка между сайтами, пытающимися обнаружить headless-браузеры, и headless-браузерами, которые выдают себя за настоящие.
Подключите программу для решения CAPTCHA
Существуют веб-сайты, которые систематически просят вас подтвердить, что вы не робот, с помощью капч. Обычно капчи отображаются только для подозрительных IP-адресов, и с этим помогут прокси. В остальных же случаях используйте автоматический решатель CAPTCHA — скажем, 2Captcha или AntiCaptcha.
Распознаватели чаще всего платные, потому что капчи вручную решают реальные люди. Поэтому стоит понять, оправдают ли затраты поставленную цель.
Избегайте honeypot-ловушек
«Honeypot» — это фальшивая ссылка, которая невидима для обычного пользователя, но присутствует в HTML-коде. Как только вы начнёте анализировать сайт, honeypot может перенаправить вас на пустые и бесполезные страницы-приманки. Поэтому всегда проверяйте, установлены ли для ссылки CSS-свойства «display: none», «visibility: hidden» или «color: #fff;» (в последнем случае нужно учитывать цвет фона сайта).
Если вы последуете хотя бы одному совету из этой статьи, ваши шансы быть заблокированным уменьшатся во много раз. Но для верности лучше комбинировать несколько приёмов и всегда следить, чтобы краулер не слишком нагружал чужие веб-серверы.
Парсинг данных: лучшие сервисы для веб-скрапинга
Часто у вебмастера, маркетолога или SEO-специалиста возникает необходимость извлечь данные со страниц сайтов и отобразить их в удобном виде для дальнейшей обработки. В этой статье мы разберемся, что такое скрапинг данных, и расскажем про семь сервисов для веб-скрапинга, которые не требуют знания кода.
Что такое скрапинг данных?
Веб-скрапинг (Web Scraping) — это способ извлечения данных с сайта или приложения (в понятном человеку виде) и сохранение их в таблицу или файл.
К категории полезных данных могут относиться:
Это легальная техника, но иногда способы использования этих данных могут быть незаконными. Например, в октябре 2020 года Facebook подал жалобу в федеральный суд США против двух компаний, обвиняемых в использовании двух вредоносных расширений для браузера Chrome. Эти расширения позволяют выполнять скрапинг данных без авторизации в Facebook, Instagram, Twitter, LinkedIn, YouTube и Amazon.
Оба расширения собирали публичные и непубличные данные пользователей. Компании же продавали эти данные, которые после использовались для маркетинговой разведки — это нелегально.
Как используют полученные данные
У веб-скрапинга/парсинга очень широкий спектр применений. Например:
1. Отслеживание цен
Собирая информацию о товарах и их ценах, например, на Amazon или других платформах, вы сможете корректировать цены, чтобы опередить конкурентов.
2. Рыночная и конкурентная разведка
Если вы хотите поработать на новом рынке, то сначала нужно оценить свои шансы, а принять взвешенное решение поможет как раз сбор и анализ данных.
3. Модернизация сайтов
Когда компании переносят устаревшие сайты на современные платформы, они используют скрапинг сайта для быстрой и легкой выгрузки данных.
4. Мониторинг новостей
Скрапинг новостных сайтов и блогов позволяет отслеживать интересующие темы и экономит ваше время.
5. Анализ эффективности контента
Блогеры и контентмейкеры используют скрапинг для извлечения статистики о своих постах, видео, твитах в таблицу. Например, в этом видео автор статьи получает данные из его профиля на сайте Medium, используя веб-скрапер:
Данные в таком формате:
Сервисы для веб-скрапинга
Скрапинг требует правильного парсинга исходного кода страницы, рендеринга JavaScript, преобразования данных в читаемый вид и, по необходимости, фильтрации… Звучит суперсложно, правда? Но не волнуйтесь — есть множество готовых решений и сервисов, которые упрощают процесс скрапинга.
Вот 7 лучших инструментов для парсинга сайтов, которые хорошо справляются с этой задачей.
1. Octoparse
Octoparse — это простой в использовании скрапер для программистов и не только.
Особенности:
2. ScrapingBee
Сервис ScrapingBee Api использует «безлоговый браузер» и смену прокси. Также имеет API для скрапинга результатов поиска Google.
Безлоговый браузер (headless-браузер) — это инструмент разработчика, с помощью которого можно тестировать код, проверять качество и соответствие верстке.
Особенности:
3. ScrapingBot
ScrapingBot предоставляет несколько API: API для сырого HTML, API для сайтов розничной торговли, API для скрапинга сайтов недвижимости.
Особенности:
4. Scrapestack
Scrapestack — это REST API для скрапинга веб-сайтов в реальном времени. Он позволяет собирать данные с сайтов за миллисекунды, используя миллионы прокси и обходя капчу.
Особенности:
5. Scraper API
Scraper API работает с прокси, браузерами и капчей. Его легко интегрировать — нужно только отправить GET запрос к API с вашим API ключом и URL.
Особенности:
6. ParseHub
ParseHub — ещё один сервис для веб-скрапинга, не требующий навыков программирования.
Особенности:
7. Xtract.io
Xtract.io — это гибкая платформа, использующая технологии AI, ML и NLP.
Её можно настроить для скрапинга и структурирования данных сайтов, постов в соцсетях, PDF-файлов, текстовых документов и электронной почты.
Цена: есть демо-версия
Особенности:
Независимо от того, чем вы занимаетесь, парсинг веб-страниц может помочь вашему бизнесу. Например, собирать информацию о своих клиентах, конкурентах и прорабатывать маркетинговую стратегию.


