Определяем пол и возраст по фото

В практике внутреннего аудита встречаются задачи, при которых необходимо осуществить проверку по выявлению некорректного ввода данных о клиенте. Одной из таких проблем может быть несоответствие введенных данных и фото клиента, в момент оформления продукта.
К примеру, имеется следующая информация: пол, возраст и ссылка на фото. Для проверки соответствия воспользуемся библиотекой py-agender языка Python.
Работа библиотеки осуществляется в два этапа. На первом, opencv определяет расположение лица на фото. На втором, нейронная сеть архитектуры EfficientNetB3, которая обучена на наборе данных UTKFace DataSet, определяет пол и возраст обладателя лица на фото.
Для начала импортируем необходимые библиотеки:
Создадим объект детектора пола и возраста:
С помощью opencv загрузим фото:
Далее определим характеристики лица с помощью метода detect_genders_ages объекта agender:
где переменная face_info содержит следующую информацию:
Здесь параметры (‘left’, ‘top’, ‘right’, ‘bottom’, ‘width’, ‘height’) характеризуют расположение лица на фото. Параметр gender характеризует принадлежность к определенному полу, где 0 – соответствует мужчине, 1 – женщине. Т.е. после обработки изображений, по порогу 0.5 разделяем обработанную выборку на мужчин и женщин.

Алгоритм определил, что на данном изображении представлен мужчина (значение пола очень близко к нулю: 0.0075379927), а также, что на этом фото ему 41 с половинкой годика (41.5858), не знаю сколько Константину Хабенскому лет на этом фото, но думаю алгоритм близок к истине.
Хороший пример, четкое изображение и довольно впечатляющий результат. Однако, когда начинаешь применять алгоритм к реальным данным, все не так радужно, как хотелось бы. И дело здесь не сколько в алгоритме, а в качестве исходных данных.
В моем случае это был набор из 1542 изображений с разрешением 300х300. Для 64 изображений алгоритм не смог определить характеристики лица. Основная причина – плохая освещенность в момент фотофиксации (лиц почти не видно). Для 1478 изображений медианное значение ошибки определения возраста составило 4,96 года. На рисунке ниже представлено распределение ошибки:
Для 8.5% изображений (125 из 1478) алгоритм совершил ошибку в определении пола человека. Из них в 122 случаях алгоритм ошибочно принял женщину за мужчину. Повторюсь, не стоит винить алгоритм во всех случаях. В большинстве ошибочных примеров встречалось много лиц в очках, которые могут скрывать некоторые особенности лица. На рисунке ниже представлено распределение возраста для набора данных UTKFace DataSet:
Можно заметить, что большая часть набора данных содержит изображения людей c возрастом 20-40 лет. Несмотря на это алгоритм чаще всего ошибался именно для указанного интервала, т.е скорее всего ошибки связаны с особенностью набора данных, для которого был применен алгоритм. На рисунке ниже представлено распределение возраста людей, на которых алгоритм ошибся:
Py-Agender – интересный инструмент, который может помочь автоматизировать ряд рутинных задач или по крайней мере уменьшить размер выборки для ручного анализа. В статье представлена оценка для специфичного набора данных, возможно в вашем случае алгоритм сработает более результативно.
Нейросети для предсказания возраста и пола

Получение информации о возрасте и гендерной принадлежности человека происходит исключительно по фотографии его лица. Исходя из этого можно разделить нашу задачу на два основных этапа:
Импортируем необходимые библиотеки
Ниже представлен код для проверки работы алгоритмов
Проведем серию экспериментов для проверки качество работы алгоритмов.
— одиночная фотография человека
— Несколько людей на фотографии
— Несколько людей на фотографии, в случае когда взгляд устремлен не в кадр
— Несколько людей на фотографии, когда часть их лица скрыта, например, масками
Можно сделать вывод, что в идеальных условиях(высокая четкость фотографии, лицо направлено строго в кадр) оба алгоритма работают без нареканий, но при малейшем отклонении от этих условий, каскады Хаара начинают сбоить. Поэтому выбор остановился на использовании модели MTCNN.
Теперь, когда разобрались с выбором метода обнаружения лиц на фотографии перейдем непосредственно к самой задаче. Для определения возраста и пола использовались две разные модели, обученные на огромном количестве данных. Обе модели были обучены Леви и Хасснером, первая их работа вышла в 2015 году под названием «Age and Gender Classification Using Convolutional Neural Networks». В своей работе они продемонстрировали, что при обучении с использованием глубоких сверточных нейронных сетей (CNN) можно добиться значительного повышения производительности при выполнении задач предсказывания возраста и пола.
Для определения гендерной принадлежности была взята модель с репозитория, посвященному статье «Understanding and Comparing Deep Neural Networks for Age and Gender Classification».Скачать модели можно по ссылке 1 (*.caffemodel) и по ссылке 2 (*.prototxt). Модель использует архитектуру сети GoogleNet и была предобучена на ImageNet dataset.
Как можно было заметить, каждая модель представлена двумя файлами, это значит что она была обучена с помощью Caffe (фреймворк глубокого машинного обучения нацеленный на простое использование, высокую скорость и модульность).Файл с расширением prototxt отвечает за архитектуру сети, а файл с расширением caffemodel за веса модели.
Ниже кратко представлен основной код, в качестве аргумента в модель передаем определённое выше лицо.
Результаты полученные в ходе отработки алгоритма
Определяем возраст и пол человека используя нейронную сеть

У нас была задача отсортировать профили людей по возрасту и полу. Нам нужно было сегментировать базу потенциальных клиентов для запуска тестовых рекламных компаний, для каждой рекламной компании мы подбирали индивидуальные видео которые лучше всего подошли бы людям определенного возраста и пола.
Если вам интересны такие темы и вы хотите и дальше видеть новые публикации и развитие данного модуля, то просим вас поставить нам звездочку ⭐ на Github!

После анализа доступных библиотек, мы нашли интересный репозиторий на Github: https://github.com/davisking/dlib-models
Автор Davis E. King @davisking, он же создатель замечательной библиотеки dlib, предоставил уже натренированную модель на несколько тысяч лиц людей. Но, вот беда… код написан на C++ а рабочей альтернативы на Python мы не нашли.
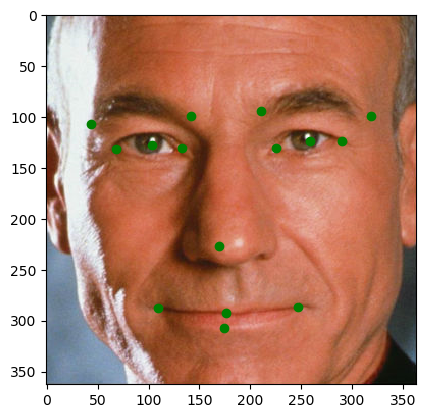
Модель для определения формы лица (shape_predictor_5_face_landmarks.dat)
Это 5-точечная модель, которая определяет уголки глаз и дно носа. Она обучена на наборе данных из 5-точечных ориентиров от 7198 лиц людей. Автор @davisking создал этот набор данных, загружая изображения из Интернета и комментируя их с помощью инструмента imglab от dlib.

Модель для предсказывания возраста (dnn_age_predictor_v1.dat)
Первоначальный источник для создания модели пришел из документа Z. Qawaqneh: «Глубокая сверточная нейронная сеть для оценки возраста на основе модели VGG-Face». Тем не менее, наши исследования привели нас к значительным улучшениям в CNN модели, что позволило нам оценить возраст человека, превосходящего существующие результаты, с точки зрения точности результата.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Таким образом, эта модель является определителем возраста, использующим архитектуру ResNet-10, и обучается с использованием частного набора данных из примерно 110 тыс. различных изображений людей с комментарием в виде их возраста.

Эта модель прогнозирования возраста предоставляется компанией Cydral Technology бесплатно и распространяется по лицензии Creative Commons Zero v1.0 Universal.

Модель для определения пола человека по лицу (dnn_gender_classifier_v1.dat)
Эта модель является гендерным классификатором, обученным с использованием частного набора данных из примерно 200 000 различных изображений лиц, и она была сгенерирована в соответствии с определением сети и настройками, заданными в «Минималистической модели на основе CNN для прогнозирования пола по изображениям лиц«. Даже если набор данных, использованный для обучения, отличается от того, который использовался Г. Антиповым, результаты классификации по оценке LFW в целом схожи (± 97,3%).
Эта гендерная модель предоставляется бесплатно компанией Cydral Technology и распространяется по лицензии Creative Commons Zero v1.0 Universal.
Перенос C++ кода на Python
Изначально, @davisking предоставил два C++ файла которые показывали как работать с натренированными им моделями:
Они выводили результат сразу в консоль, но вот использовать код в рабочем проекте даже на C++ было крайне неудобно. Используя pybind11 мы имеем возможность применить код на C++ в нашем коде на Python. Мы не будем акцентироваться долго на pybind11, но если вы хотите ознакомиться с ним, то рекомендуем статью: Создаем С++ Python расширения с помощью pybind11
Как мы научили нейронку распознавать пол и возраст

Директор по науке Neuromation
Cергей Николенко, директор по науке Neuromation, и Рауф Курбанов, старший научный сотрудник компании, рассказывают, как шла разработка технологии и почему это не так просто, как кажется на первый взгляд.
В феврале у нас вышла первая версия платформы, на которой мы используем вычислительные мощности от майнеров криптовалют для обучения моделей искусственного интеллекта. Пока доступна только альфа-версия платформы, но уже сейчас на ней есть много интересных моделей. В этой статье мы расскажем об одной такой модели, которая уже доступна на платформе: это самая простая нейронная архитектура из всех демо-моделей, но даже в этой сети найдётся немало трюков, о которых стоит поговорить подробнее. Итак, вперёд!
Интуитивно? Не думаю.
Исследователи искусственного интеллекта склонны подвергать сомнению природу интуитивного. Как только вы зададитесь вопросом, как компьютер может повторить то, что кажется простым для людей, вы заметите: то, что кажется «интуитивно понятным» для нас, может быть очень сложно формализовать. Наше визуальное восприятие человеческого возраста и пола — хороший пример такого тонкого качества.
Элиезер Юдковский — один из важнейших современных авторов для нас, AI-гиков. Юдковский известен как исследователь безопасности сильного искусственного интеллекта и автор самого популярного фанфика к «Гарри Поттеру», «Гарри Поттер и методы рационального мышления». Любопытно, что именно в Гарри Поттере появляется прекрасный пример для нашего тезиса, артефакт, который кажется интуитивно понятным:

Альбус Дамблдор провёл «Линию Возраста» вокруг «Кубка огня», чтобы к нему не смог приблизиться никто младше семнадцати лет. Магия Линии Возраста была настолько сильной, что даже зелье старения не могло обмануть её. Даже Юдковский не особенно вникал в механику Линии Возраста в свойственной ему дотошной манере, но сегодня мы попробуем, а заодно ещё и решим задачу определения пола по фотографии. Как обычно в компьютерном зрении, мы начнём со сверточных нейронных сетей.
Свёрточные нейронные сети
Нейронная сеть — это метод машинного обучения, который в некотором очень абстрактном смысле пытается моделировать то, как мозг обрабатывает информацию. Нейронная сеть состоит из простых обучаемых элементов — искусственных нейронов, или перцептронов. Во время обучения нейроны обучаются преобразовывать входные сигналы (скажем, изображение кошки) в соответствующие выходные сигналы (например, метку «кошка»), тем самым обучаясь автоматически распознавать и тех кошек, которых раньше никогда не видели.
В настоящее время практически всё компьютерное зрение основано на свёрточных нейронных сетях (convolutional neural networks, CNN). CNN — это многослойные (глубокие) нейронные сети, в которых каждый нейрон «видит» только очень маленькое «окно» выходов предыдущего уровня. Постепенно, слой за слоем, локальные функции становятся глобальными, и нейроны высоких уровней уже способны «видеть» большую часть исходного изображения. Вот как это работает в очень простой свёрточной архитектуре (см. этот пост, который мы всецело рекомендуем прочитать полностью):
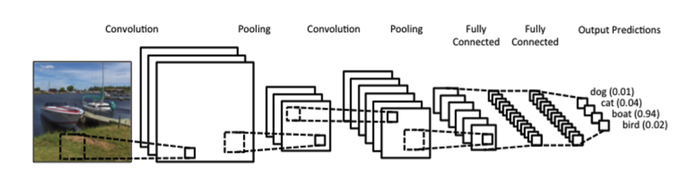
В конце концов, после нескольких (иногда нескольких сотен) слоёв мы получаем глобальные функции, которые «смотрят» на всё исходное изображение, и теперь их можно комбинировать относительно просто, чтобы получить метки классов (например понять, является ли изображение собакой, кошкой, самосвалом или Гарри Поттером).
С технической точки зрения свёрточная нейронная сеть представляет собой нейронную сеть со свёрточными слоями, а свёрточный слой представляет собой преобразование, которое применяет определённое ядро (фильтр) к небольшому окну вокруг каждой точки входа.
Рассмотрим простой пример фильтра: обнаружение краёв в изображениях. В этом случае вход для такого фильтра — это изображение, где каждый пиксель определяется тремя числами: интенсивностью красного, зелёного и синего цветов. Мы строим специальное ядро, которое будет применяться к каждому пикселю изображения; выход представляет собой новый «образ», который показывает результаты этого ядра. В принципе, ядро здесь представляет собой небольшую матрицу. Вот как это работает:
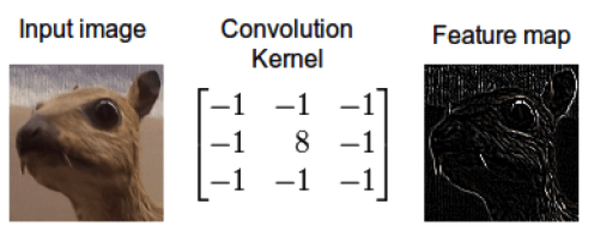
Ядро скользит по каждому пикселю изображения, а выходное значение увеличивается всякий раз, когда есть край, резкая смена цветов. На рисунке выше мы видим, как после умножения этой маленькой матрицы на каждое окно 3×3 в изображении мы получаем очень хороший результат обнаружения краёв.
Если идея фильтров и ядер стала немного понятной, свёрточные слои в нейронных сетях тоже легко объяснить. Свёрточный слой — это по сути свёртка, как в примере обнаружения края выше, но теперь мы не задаём матрицу сами, а настраиваем, «натаскиваем» её в процессе обучения сети. Нам больше не нужно изобретать эти маленькие матрицы, потому что сети могут автоматически подбирать матрицы, которые извлекают признаки, важные для конкретной задачи.
Этапы работы модели
Оценка пола и возраста звучит как самая классическая задача машинного обучения: бинарная классификация для полов (боюсь углубляться в дискуссии на эту тему, но да, наши модели живут в бинарном мире) и регрессия для возраста. Но прежде чем мы сможем решить эти задачи, нам нужно найти лица на фотографии! Классификация не будет работать на картинке в целом, потому что на фотографии может быть, например, сразу несколько лиц. А значит, проблема оценки возраста и пола обычно разбивается на два этапа: сначала поиск лиц на фотографии, а затем оценка пола и возраста для каждого из них:

В модели, которую можно найти на нашей NeuroPlatform, эти шаги выполняются независимо, поэтому давайте и обсудим их по отдельности.
Поиск лиц
Поиск лица на фотографии — классическая задача в компьютерном зрении. Её решали вполне успешно ещё до революции глубокого обучения, в начале 2000-х годов, так называемым алгоритмом Виола-Джонса. Это было одно из самых известных применений каскадов Хаара в качестве признаков; но эти дни давно прошли.
Сегодня распознавание лиц не рассматривается как отдельная задача, требующая индивидуального подхода. Оно точно так же решается свёрточными нейронными сетями. Уже давно стало ясно, что CNN хорошо подходят для обнаружения объектов вообще, и поэтому современное решение классической задачи тоже, скорее всего, будет основано на CNN; так и получается.
Но в реальных проектах по машинному обучению надо учитывать и другие свойства модели, помимо качества результатов; было бы хорошо, чтобы модель была достаточно простой, а вывод в модели — достаточно быстрым.
Если более простой подход работает достаточно хорошо, возможно, не стоит вводить очень сложные модели, чтобы выиграть несколько процентных пунктов (напомните мне потом рассказать вам о результатах конкурса рекомендательных систем Netflix Prize Challenge). Поэтому в демо на NeuroPlatform мы используем более классический подход к обнаружению лиц, а свёрточные сети работают только для основной задачи распознавания возраста и пола. Но и в классическом компьютерном зрении есть о чём рассказать.
Наша модель обнаружения лица использует метод опорных векторов (SVM, классический метод машинного обучения; пожалуй, поля этой статьи слишком узки, так что просто оставим ссылку), который запускается на HOG + SIFT представлении изображения. Представления HOG и SIFT — это тщательно вручную подобранные функции, ставшие результатом многолетнего опыта в создании систем распознавания образов. Оказалось, что это представление хорошо работает с ядерными методами, в том числе и с методом опорных векторов.
Оценка возраста
Итак, предположим, что лицо мы на картинке нашли. Чтобы оценить возраст, мы применяем глубокую свёрточную нейронную сеть к этому самому лицу. Метод в нашем демо использует архитектуру так называемых «широких остаточных сетей» (Wide Residual Networks, WRN), одну из последних разработок в области распознавания образов, которая достигает лучших результатов быстрее, чем другие ведущие архитектуры. Давайте посмотрим, что такое остаточные сети и почему они так хорошо работают.
Проект ImageNet представляет собой большую базу данных изображений, предназначенную для использования в моделях компьютерного зрения. Революция глубокого обучения в приложении к компьютерному зрению началась в 2010 году именно с резкого продвижения в решении ImageNet Challenge. Результаты на ImageNet были признаны не только в академическом сообществе, но и на практике, а ImageNet стал и до сих пор остаётся самым популярным датасетом общего назначения в компьютерном зрении. Не вдаваясь в подробности, давайте просто посмотрим на график, сравнивающий победителей нескольких последних лет:
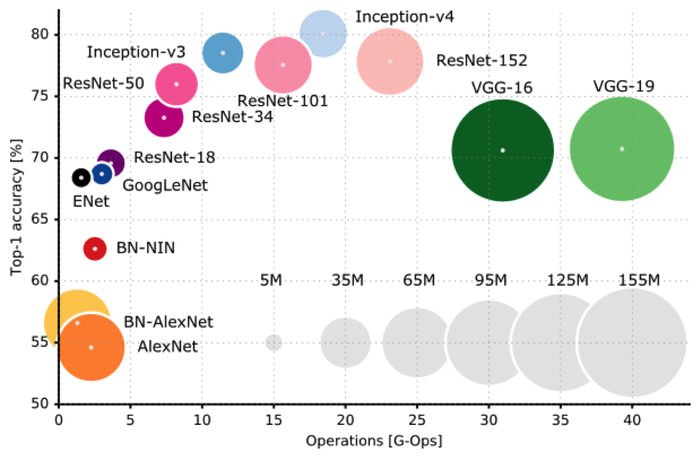
На графике горизонтальная ось показывает, насколько вычислительно сложна модель, круг указывает число параметров, а по вертикали показан собственно результат. Как видно, архитектуры ResNet (это и есть остаточные сети, residual networks) показывают отличные результаты, но при этом ещё и очень эффективны. В чём же их секрет?
Известно, что более глубокие нейронные сети теоретически могут работать лучше, чем более мелкие модели, они более выразительны. Но оптимизация в глубоких моделях — большая проблема: более глубокие модели труднее оптимизировать из-за особенностей того, как градиенты распространяются от верхних слоёв к нижним (надеюсь, в один прекрасный день мы подробно объясним всё это). Остаточные соединения — отличное решение этой проблемы: они добавляют «обходные» соединения, и поток градиента теперь способен «пропускать» лишние слои во время обратного распространения ошибки, что приводит к гораздо более быстрой сходимости и более качественному обучению:
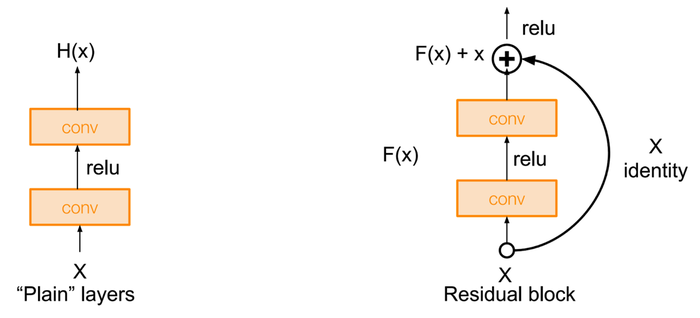
А WRN, широкие остаточные сети, делают следующий шаг: их авторы тщательно изучили соотношение между шириной и глубиной нейросетевой архитектуры и подобрали максимально эффективную архитектуру с самой быстрой сходимостью.
Определение пола и возраста по фото
Проект был выполнен для компании Deep.Social
Введение
Для рекламодателей, использующих influencer marketing, важно понимать, у какого блогера аудитория наиболее соответствует рекламируемым товарам и услугам. Довольно бессмысленно рекламировать деловые костюмы девочкам-подросткам, так же как и продвигать женскую косметику среди аудитории мужчин за 30.
Но сам Instagram не предоставляет никакой соцдем информации по аудитории блогера, поэтому рекламодателям приходится работать с блогерами исключительно на основе своих предположений о составе их аудитории. Единственный способ подтвердить эти предположения – просмотреть выборку из фолловеров интересующего блогера и оценить на глаз их возраст и пол. Это долгая, неинтересная, и немасштабируемая работа, к тому же не совсем объективная, т.к. разные люди оценят возраст по разному.
Но почему бы не поручить эту работу машине? Современные технологии Computer Vision уже достаточно развиты, чтобы справиться с этой задачей без участия человека.
Постановка задачи
На входе есть аватары Instagram пользователей. Необходимо понять, есть ли на аватаре люди, и сколько их. Если изображён один человек, предсказать его возраст и пол. При этом масштаб изображения может быть разным: на аватаре может быть портрет или даже часть лица, может быть человек в полный рост, может быть что-то промежуточное. Фото может быть цветным, чёрно-белым, тонированным, пропущенным через искажающие фильтры, с дорисованными частями и т.п.
Естественным образом задача разделяется на две основные части:
Обнаружение людей
Пол и возраст определяется прежде всего по лицу, поэтому обнаружением человека считается наличие лица в кадре. Нога, рука или спина, хотя и говорят о наличии человека на фото, для решаемой задачи не подходят. Безусловно, можно обучить computer vision модель, которая будет отличать мужскую ногу от женской, но на покрытие всех таких ситуаций ушло бы слишком много ресурсов, при сравнительно небольшой отдаче – всё таки лица изображены на аватарах гораздо чаще, чем ноги.
Обнаружение лиц на фото это известная и хорошо проработанная задача computer vision, поэтому здесь работа свелась к поиску подходящей модели и адаптации её под требования проекта. Основными требованиями были приемлемая скорость работы (аудитория блогеров это сотни миллионов пользователей) и наличие уже обученного и готового к использованию варианта (чтобы не тратить время на разметку данных и обучение).
Одним из дополнительных пожеланий было совмещение моделью двух функций: собственно нахождения лиц на фото, и определения опорных точек (face landmarks). Опорные точки это обычно центры глаз, кончик носа, углы губ и другие топологические точки, положение которых на лице может быть однозначно определено. Зачем они нужны?
Свёрточные сети (convolutional networks), используемые в моделях компьютерного зрения, обладают свойством трансляционной инвариантности (translational invariance), но не обладают (или обладают в ограниченном объеме) свойствами масштабной инвариантности (scale invariance) и инвариантности к повороту (rotation invariance). Это означает, что если изображение одного и того же лица смещается на фото в разные положения, то с точки зрения нейросети это будет то же самое лицо (трансляционная инвариантность). Но если лицо поворачивается или изменяется его масштаб, для нейросети это будут разные лица. Поэтому, чтобы облегчить задачу для нейросети, лучше приводить все лица к единому масштабу и единому вертикальному положению, а для этого нужна привязка к надёжным опорным точкам (например, считать стандартным размером лица расстояние в 100 пикселей между горизонталью глаз и горизонталью губ, и приводить все лица к этому масштабу) 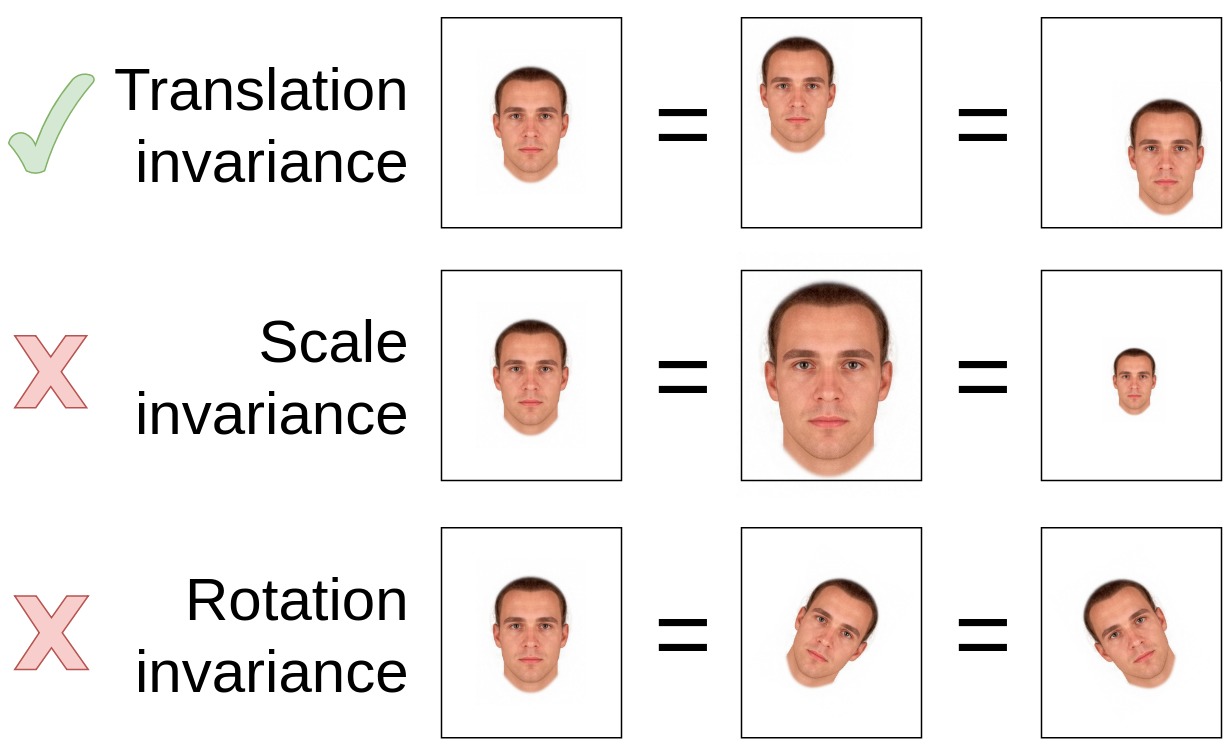
Инвариантность для свёрточных сетей
С учетом перечисленных требований, задача свелась к выбору из двух моделей: MTCNN [1] и детектора из библиотеки dlib: CNN Face detector + 5-point landmark detector.
MTCNN vs dlib
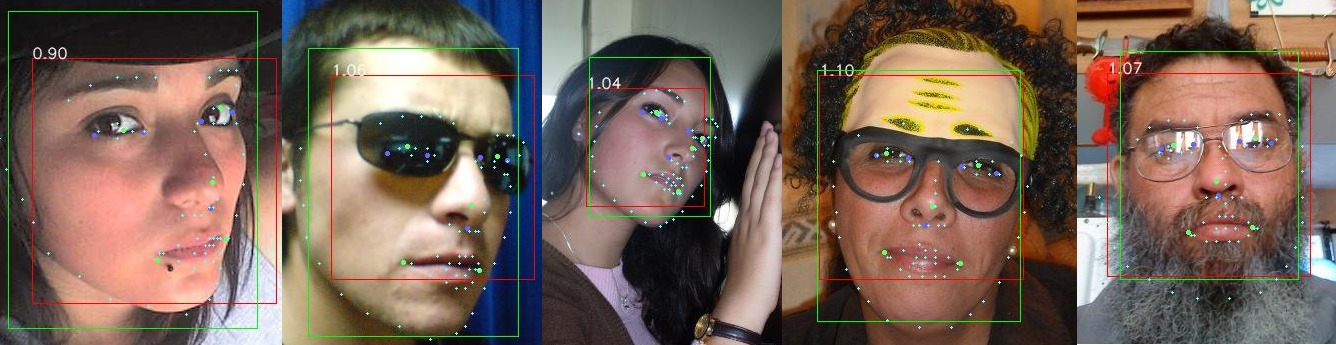
Примеры определения границ лица и опорных точек библиотеками MTCNN (зелёный прямоугольник, зелёные точки), dlib (красный прямоугольник, фиолетовые точки), face-alignment (белые миниатюрные точки)
Архитектура MTCNN
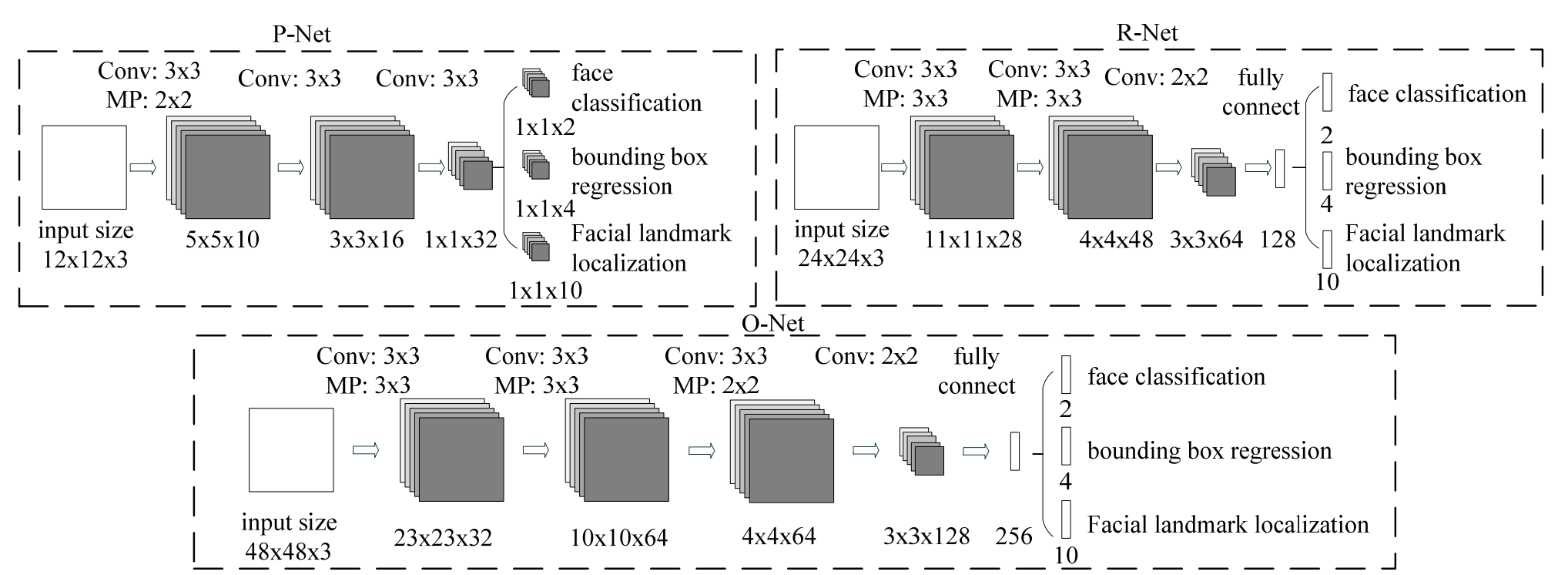
MTCNN состоит из трех CNN-“стадий” P-Net, R-Net и O-Net, каждая из которых уточняет результаты предыдущей ступени, и предварительной стадии построения “пирамиды изображений”. Пирамида представляет из себя просто набор уменьшенных копий входного изображения. MTCNN заранее не знает, в каком масштабе будут лица на фото, а свёрточные сети, как уже говорилось выше, не инвариантны к масштабированию. Поэтому приходится готовить несколько версий входного изображения в разных масштабах, и искать лица на каждой версии.
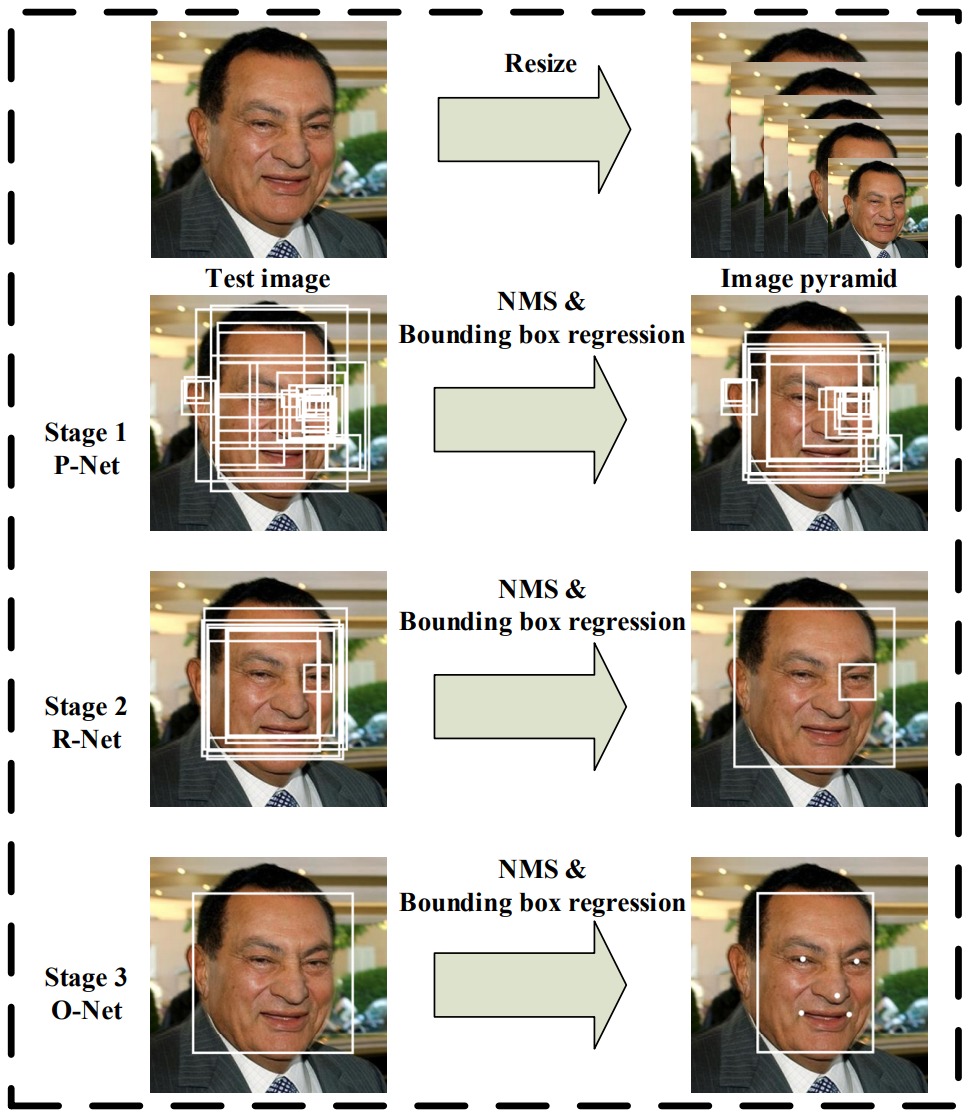
Стадии работы MTCNN
Трёхстадийная архитектура позволяет MTCNN работать быстро, т.к. всю черновую работу делает простая первая ступень, а следующие занимаются только уточнением результатов. Как показали замеры, основное время уходит на построение пирамиды изображений, а не на собственно работу свёрточных сетей. Переход на более быстрые алгоритмы уменьшения изображений позволяет ещё в разы поднять производительность.
Нормализация лиц
Перед тем, как отдавать найденные лица в детектор пола/возраста, их необходимо нормализовать, т.е. привести лица разного масштаба, по разному повёрнутые и наклонённые, к одному стандартному виду “как на паспорт”.
Существует довольно много методик нормализации, от продвинутых, натягивающих лицо как скин на 3D модель и манипулирующих этой моделью в пространстве, чтобы она смотрела прямо в объектив и заполняла весь кадр, находясь в его центре, до простых, ограничивающихся приведением лиц к близкому масштабу. Какую из них выбрать?
Я исходил из принципа минимального вмешательства: нормализация должна выдавать только естественную форму лица, которая встречается в природе. Если нормализация изменяет пропорции раздельно по осям X и Y, изменяет параллельность линий, или тем более натягивает лицо на 3D сетку, то она может принести больше вреда, чем пользы. Это подтверждают исследования [3] результатами которых я активно пользовался при работе над этим проектом.
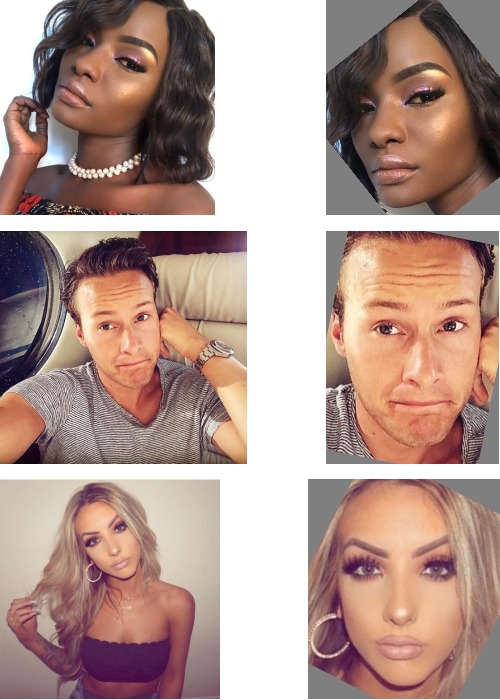
Примеры нормализации лиц, слева исходное фото, справа результат.
Определение пола и возраста
Выбор модели
Модель для определения пола и возраста подбиралась из примерно тех же критериев, что и модель для обнаружения лиц:
NASNet-A-Mobile-224, сконструированный с помощью “искусственного интеллекта”, содержит примерно в 5 раз параметров, чем ResNet-50. Но на практике он обучался не в 5 раз быстрее, а даже медленнее, чем ResNet-50.
Аналогично mobilenet-1.0-224, несмотря на то, что содержит в разы меньше параметров, чем ResNet-50, на практике обучался со скоростью, сопоставимой с ResNet-50, показывая при этом худшие результаты предсказаний. Видимо, эта архитектура имеет смысл именно для мобильных устройств, а не для стационарных GPU.
В итоге победил ResNet-50, как архитектура, оптимальным образом использующая стационарный GPU (обучение шло на видеокартах GTX 1080TI).
Архитектура
Обучающая выборка
В идеале обучающая выборка должна быть из того же распределения, что и данные, на которых потом модель будет делать предсказания. Это означает ручную разметку фотографий из Instagram, т.к. достоверную информацию о возрасте владельцев аккаунтов взять негде.
Ручная разметка пола это в принципе посильная задача, а вот с возрастом всё не так просто. Люди определяют возраст на глаз крайне субъективно, это означает большую дисперсию и затруднительность контроля результатов. Для того, чтобы получить от работников надёжный результат, обычно одна и та же задача даётся трём-пяти людям, и за верный результат принимается большинство голосов. Работник, часто дающий ошибочные результаты, заменяется. Для возраста такая схема работать не будет, т.к. чтобы получить надёжную картину максимума распределения возрастов для каждого фото и отсеять выбросы, пришлось бы давать оценить каждое фото 10-20 людям, что было бы слишком затратно.
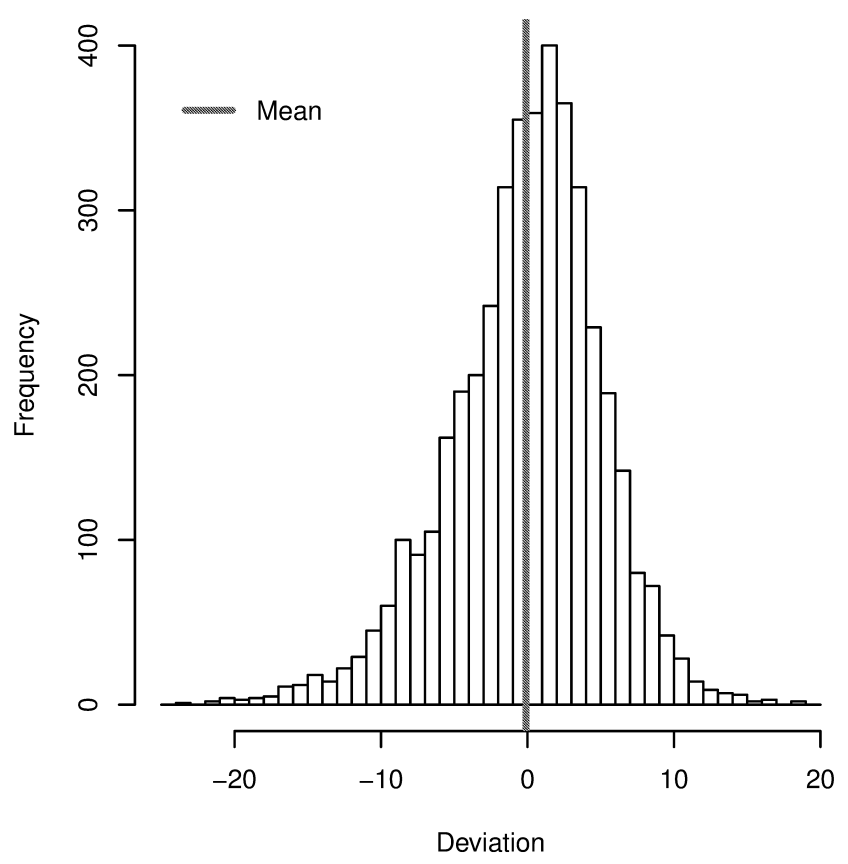 10 оценкам от разных людей) и реальным возрастом. Источник: AgeGuess database, J. A. Barthold Jones et al, 2018, arXiv:1803.10063″ width=»400″/>
10 оценкам от разных людей) и реальным возрастом. Источник: AgeGuess database, J. A. Barthold Jones et al, 2018, arXiv:1803.10063″ width=»400″/>
Распределение разницы между средним оценочным возрастом (по > 10 оценкам от разных людей) и реальным возрастом. Источник: AgeGuess database, J. A. Barthold Jones et al, 2018, arXiv:1803.10063
Оценка возраста людьми может сильно расходиться с реальным возрастом, см. приведённый рисунок. Кроме того, оценка возраста зависит еще и от национальности и культурного контекста оценщика, т.е. пришлось бы набирать распределённую по разным точкам мира команду.
Поэтому были рассмотрены другие источники. Стандартный dataset, используемый в академических кругах для подобных задач, это IMDB-WIKI [8]
Однако, качество разметки этого dataset-а, особенно в данных из IMDB, крайне низкое, и неприемлемо для проекта, который будет использоваться в production.
В результате самым продуктивным оказался самостоятельный автоматизированный сбор данных из социальных сетей и Интернет-сайтов, с последующей модерацией. Но найти хорошие источники размеченных фотографий для возрастов [11] Максимальный и минимальный learning rate подбирался с помощью техники LR range test [12]
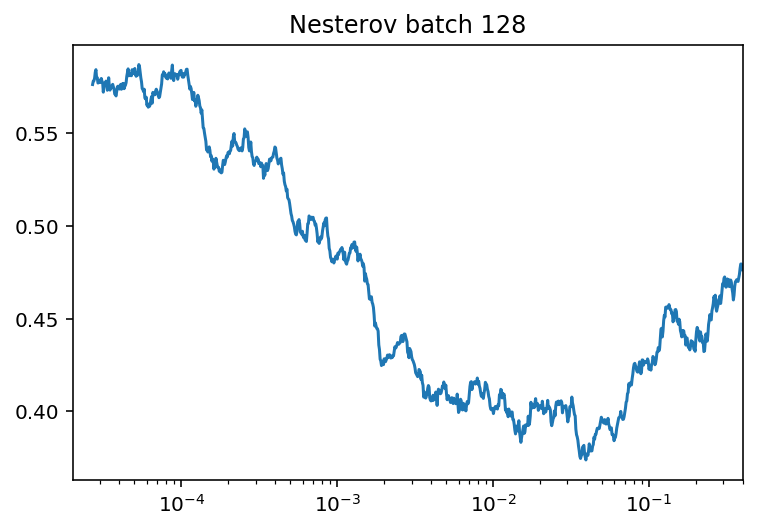
Один полный прогон обучения занимал около пяти дней.
Результаты
Для возраста точность оценивалась по ошибке MAPE (Mean absolute percentage error), показывающей отклонение в процентах определенного моделью возраста от реального.
Собственный dataset
Распределение возрастов соответствует естественному распределению в социальных сетях, откуда были собраны данные.
| Service | Gender accuracy, % | Age MAPE, % |
|---|---|---|
| Ours | 99.3 | 14.4 |
| Face++ | 92.2 | 59.3 |
| Clarifai | 84.8 | 47.7 |
| Azure | 96.9 | 34.2 |
| AWS Rekognition | 91.1 | 38.1 |
IMDB-Wiki
Из IMDB-WIKI были отброшены данные IMDB, как содержащие огромное количество неточностей, в данных WIKI был дополнительно вручную исправлен пол там, где были явные ошибки. Для тестов были взяты фото людей в диапазоне возрастов 13-44 года (актуальный диапазон для Instagram). Также были отброшены фотографии, сделанные до 2005 года, т.к. стилистика этих фото (косметика, причёски) отличается от современной, и фото такой давности редко встречаются в соцсетях.
| Service | Gender accuracy, % | Age MAPE, % |
|---|---|---|
| Ours | 98.7 | 14.9 |
| Face++ | 92.6 | 36.6 |
| Clarifai | 91.9 | 35.9 |
| Azure | 89.4 | 24.6 |
| AWS Rekognition | 94.0 | 43.8 |
Adience
Возраст в Adience указан в виде диапазона а не точного значения, поэтому для него использовались другие метрики точности:
Если бы целью было показать хороший результат именно на Adience, надо было бы обучить модель на выборке с равномерным сэмплированием по всем возрастам.
На что смотрит модель?
Было бы интересно понять, какие области лица играют главную роль при определении пола/возраста. Большинство традиционных методы выявления областей внимания для этой модели, к сожалению, не выдают наглядных результатов, т.к. в результате нормализации лицо занимает практически весь кадр, и вся его площадь является активной областью. Самые наглядная визуализация получилась при использовании библиотеки SHAP [13] (метод DeepExplainer) 
Активные зоны, влияющие на определение пола на мужском и женском лицах
Из собственного практического опыта работы с этой моделью – она смотрит примерно на те же признаки, что и человек, никакого сверхзнания у неё нет. Если показать модели фото мальчика, хорошо загримированного под девочку, модель выдаст ответ “девочка”, и наоборот. Трансгендеры и лица, не до конца определившиеся с выбором визуального пола, вызовут у модели затруднения при определении биологическго пола, такие же, как и у людей.
Эволюция в результате обучения
Ещё один вопрос, на который было интересно ответить – насколько модель далеко ушла в своей эволюции от изначальной модели, обученной на изображениях ImageNet? Поскольку выразить “далеко” или “не очень” в виде числовой оценки затруднительно, лучше получить ответ в виде визуализации. Я использовал визуализацию каналов ResNet с помощью библиотеки Lucid. Суть этой визуализации в том, что с помощью оптимизации подбирается такое входное изображение, которое максимизирует ответ от канала. Содержимое этого изображения будет указывать, на какие паттерны во входном изображении реагирует данный канал.

Визуализация паттернов в первом блоке ResNet, 6-й канал
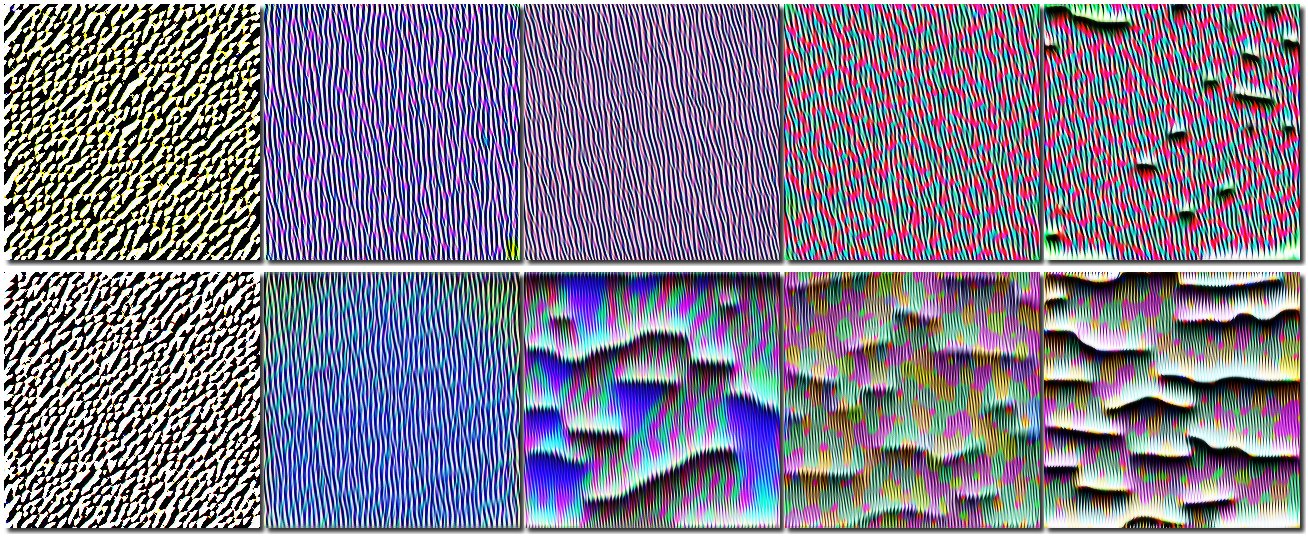
Визуализация паттернов в первом блоке ResNet, 7-й канал
В первом блоке обрабатываются самые простые паттерны. Видно что паттерны для исходной и нашей модели не сильно отличаются. Тем не менее уже заметно, что паттерны для ImageNet (нижние ряды) имеют более сложную структуру.

Визуализация паттернов во втором блоке ResNet, 5-й канал
Во втором блоке паттерны усложнились, но всё еще похожи друг на друга. Заметно, что в паттернах ImageNet больше цветовое разнообразие, а паттерны нашей модели окрашены в цвета, близкие к телесным.

Визуализация паттернов во третьем блоке ResNet, 4-й канал

Визуализация паттернов во третьем блоке ResNet, 8-й канал
В третьем блоке паттерны продолжают усложняться, и схожесть между ними остаётся только на самом общем уровне. Паттерны ImageNet имеют гораздо более проработанную структуру, которая начинает соответствовать объектам из реального мира.

Визуализация паттернов в четвёртом блоке ResNet, 4-й канал
В последнем блоке паттерны окончательно перестали был похожими друг на друга. В паттернах нашей модели видна структура, соответствующая человеческим губам. в паттерах Imagenet – что то растительное.
Видно, что эволюция в верхних слоях зашла довольно далеко, при этом паттерны нашей модели в целом проще исходных, т.е. произошла некоторая деградация. Возможно, что ResNet-50 избыточен для данной задачи, и можно было использовать более простую сеть.
Интерактивное демо
В статье не публикуются образцы предсказаний модели, т.к. любые предсказания можно сгенерировать самостоятельно, с помощью интерактивного демо, находящегося по адресу https://ag-demo.suilin.ru/.
В демо можно загружать любые фото, где есть лицо одного человека. Поддерживается работа как с компьютеров, так и со смартфонов (можно определять пол и возраст для селфи).
Резюме
Задача распознавания пола и возраста в промышленных масштабах оказалась вполне решаемой. При этом модель угадывает возраст примерно на уровне человека, часто даже точнее.


