Окружение в тестировании что это
 В этой статье рассмотрены вопросы, относящиеся к тестовому окружению. Среда тестирования (разработки, превью и д.р.), это набор программных и аппаратных средств, с которыми мы работаем. В случае тестирования ПО, это как минимум сервер и\или рабочая станция с операционной системой, ну а в принципе это могут быть и совокупность программ, и сетевая инфраструктура (устройства и ПО), и инструменты работы с ПО, и наборы данных. Далее в статье рассмотрим какие бывают среды тестирования, как, кем и дл чего они используются.
В этой статье рассмотрены вопросы, относящиеся к тестовому окружению. Среда тестирования (разработки, превью и д.р.), это набор программных и аппаратных средств, с которыми мы работаем. В случае тестирования ПО, это как минимум сервер и\или рабочая станция с операционной системой, ну а в принципе это могут быть и совокупность программ, и сетевая инфраструктура (устройства и ПО), и инструменты работы с ПО, и наборы данных. Далее в статье рассмотрим какие бывают среды тестирования, как, кем и дл чего они используются.

Вопрос технической реализации среды, это скорее вопрос конкретного технического решения, реализации в том или ином проекте, команде или организации. У вас может быть собрана, например, сложная сетевая топология из роутеров, рабочих станций и серверов для эмуляции реальной сети, установлено специальное ПО для управления и мониторинга трафика, а также реализованы средства для установки обновлений ПО. В этом плане важным будет ваш опыт, опишите то решение, с которым довелось работать.
С точки зрения общих вопросов, касающихся работы со средой тестирования нужно понимать следующие моменты:
1. Обычно существует разделение сред на среду разработки, тестирования и продуктивную (рабочая, «боевая»). Но это минимальный набор сред. Кроме них, также могут выделять, например, превью, интеграционную среду. Кратко для чего нужна каждая среда:
2. Команда QA непосредственно работает со средой тестирования и интеграционной средой (часто она же превью среда).
3. Думаю, что схема Среды разработки и тестирования ПО сможет наглядно показать кто и на каких этапах работает с той или иной средой, а также кто эти среды поддерживает
Окружения развёртывания программного обеспечения

Только что опубликовал в русской википедии перевод статьи Deployment environment.
Публикую этот перевод здесь также. Замечания и комментарии приветствуются.
В развёртывании программного обеспечения, окружение или ярус является компьютерной системой в которой компьютерная программа или компонент программного обеспечения развёртывается и выполняется. В простом случае, такое развёртывание и немедленное выполнение программы на той же машине, может выполнятся в единственном окружении, однако при промышленной разработке используется разделение на development окружение (‘окружение разрабочика’) (где делаются исходные изменения) и production окружение (которое используют конечные пользователи); часто с промежуточными этапами (‘stages’) посередине. Этот структурированный процесс управления релизами может иметь фазы deployment (rollout, ‘развёртывание’, ‘выкатка’), testing (‘тестирование’), и rollback (‘откат’) в случае проблем.
Окружения могут существенно отличаться в размерах: deployment окружение это обычно рабочая станция отдельного разработчика, в то время как production окружение может быть сетью множества географически разнесённых машин в случае с дата-центров, или виртуальными машинами в случае с облачными решениями. Код, данные и конфигурация могут быть развёрнуты паралельно, и нет необходимости связи с соответствующим ярусом — например, pre-production код может подсоединяться к production БД.
Архитектуры
Архитектуры развёртывания существенно разнятся, но в целом, ярусы начинаются с develpment (DEV) и заканчиваются production (PROD). Распространённой 4-х ярусной архитектурой является каскад ярусов deployment, testing, model, production (DEV, TEST, MODL, PROD) c деплоем софта на каждом ярусе по очереди. Другое распространённое окружение это Quality Control (QC), для приёмочного тестирования; песочница или экспериментальное окружение (EXP), для экспериментов не предназначенных для передачи в продакшен; и Disaster Recovery (‘аварийное восстановление’), для предоставления возможности немедленного отката в случае проблемы с продакшеном. Другой распространённой архитектурой является deployment, testing, acceptance and production (DTAP).
Такая разбивка в частности подходит для серверных программ, когда сервера работают в удаленных дата-центрах; для кода который работает на конечных устройствах пользователя, например приложений (apps) или клиентов, последний ярус обозначают как окружение пользователя (USER) или локальное окружение (LOCAL).
Точные определения и границы между окружениями варьируется — test может рассматриваться как часть dev, приёмка может рассматриваться как часть test, часть stage, или быть отдельной и так далее. Основные ярусы обрабатываются в определённом порядке, с новыми релизами при развёртывании (rolled out или pushed) на каждом. Ярусы experimental и recovery, если представлены, являются внешними к этому процессу — experimental релизы являются конечными, в то время как recovery являются обычно старыми или дублирующими версиями production, развёрнутыми после production. В случае проблем, в последнем случае можно сделать roll back к старому релизу, и большинство просто выкатывают старый релиз таким же способом как новый. Последний шаг, деплой в production («pushing to prod») самый чувствительный, т.к. здесь любые проблемы напрямую влияют на пользователя. По этой причине это часто управляется по разному, но как минимум мониторится более тщательно, и в некоторых случаях имеется фаза отката или простого переключения. Лучше всего избегать названия вроде Quality Assurance (QA); QA не означает тестирование софта. Тестирование важно, но это отличается от QA.
Иногда развёртывание выполняется вне обычного процесса, главным образом для предоставления срочных или небольших изменений, без необходимости полного релиза. Это может быть один патч, большой service pack или небольшой hotfix.
Окружения могут быть очень разных размеров: разработка обычно идёт на индивидуальных машинах разработчиков (хотя это могут быть тысячи разработчиков), в то время как продакшеном могут быть тысячи географически распределённых машин; тестирование и QC может быть маленьгим и большим, зависеть от предоставленных ресурсов, а staging может варьироваться от единичной машины (подобно canary) до точных дубликатов продакшена.
Окружения
Local
Development/Thunk
Сервер разработки выступающий как песочница где разработчик может выполнить unit-тестирование
Integration
Основа для построения CI, или для тестирования сайд-эффектов разработчиком
Testing/Test/QC/Internal Acceptance
Окружение в котором выполняется тестирование интерфейса. Команда контроля качества проверяет что новый код не будет иметь влияния на существующую функциональность системы после деплоя нового кода в тестовое окружение.
Staging/Stage/Model/Pre-production/External-Client Acceptance/Demo
Production/Live
Серверы конечных пользователей/клиентов
Окружение разработчика
Окружение разработчика (dev) является окружением в котором софт разрабатывается, это часто просто компьютер разработчика. Это отличается от конечной целевой среды некоторыми вещами — цель может не быть стационарным компьютером (это может быть смартфон, встроенная система, самоуправляемый транспорт датацентра и т.д.), и даже если это стационарный компьютер, окружение разработчика будет включать инструменты разработчика например компилятор, IDE, различные или дополнительные версии библиотек и вспомогательного софта, и т.д., что не представлено в пользовательском окружении.
В контексте управления ревизиями, особенно при участии множества разработчиков, проводятся более тонкие различия: разработчик имеет рабочую копию исходного текста на своей машине, и изменения вносятся в репозиторий, будучи закомиченными либо в «стволе», либо в ветке, в зависимости от методологии разработки. Окружение на отдельной рабочей станции, на которой изменения отработаны и опробованы, может называться локальным окружением или песочницей. Сборка копии исходного кода репозитория в чистом окружении является отдельным этапом интеграции (интеграция разрозненных изменений), и это окружение может называться интеграционным окружением или окружением разработчика; при непрерывной интеграции это делается часто, так же часто, как и для каждой ревизии. Понятие уровня исходного кода звучащее как «фиксация (коммит) изменения в репозитории» с последующей сборкой «ствола» или ветки — соответствует переходу от локального (индивидуального окружения разработчика) к интеграции (чистой сборке); плохой релиз на этом этапе означает, что изменение сломало сборку, а откат релиза соответствует либо откату всех сделанных изменений, либо отмене только ломающего изменения, если это возможно.
Тестовое окружение
Цель тестового окружения состоит в том, чтобы позволить людям, проводящим тестирование, пропускать новый и измененный код либо через автоматизированные проверки, либо через неавтоматизированные методы. После того, как разработчик пропускает новый код и конфигурации через модульное тестирование в среде разработки, код переносится в одну или несколько тестовых сред. После неудачи теста тестовая среда может удалить ошибочный код из тестовых платформ, связаться с ответственным разработчиком и предоставить детальные журналы тестирования и результаты. Если все тесты пройдут, тестовая среда или фреймворк непрерывной интеграции, контролирующий тесты, может автоматически перенести код в следующую среду развертывания.
Различные типы тестирования предполагают различные типы тестовых сред, некоторые или все из которых могут быть виртуализированы для обеспечения быстрого параллельного тестирования. Например, автоматизированные тесты пользовательского интерфейса могут выполняться на нескольких виртуальных операционных системах и дисплеях (реальных или виртуальных). Для проведения тестов производительности может потребоваться нормализованная базовая конфигурация аппаратного обеспечения, чтобы результаты тестов производительности можно было сравнивать с течением времени. Тестирование на доступность или устойчивость может основываться на симуляторах отказов в виртуальных аппаратных средствах и виртуальных сетях.
Тесты могут быть последовательными (один за другим) или параллельными (для некоторых или всех сразу), в зависимости от сложности тестовой среды. Важной целью agile и других высокопроизводительных практик разработки программного обеспечения является сокращение времени от разработки или предоставления программного обеспечения до его поставки в продакшен. Высокоавтоматизированные и распараллеленные тестовые среды вносят важный вклад в быструю разработку программного обеспечения.
Staging
Stage или stage-окружение — это среда для тестирования, которая в точности похожа на продакшен-окружение. Она стремится как можно точнее отразить реальное продакшен-окружение и может подключаться к другим продакшен-сервисам и данным, таким как базы данных. Например, серверы будут работать на удаленных машинах, а не локально (как на рабочей станции разработчика во время разработки, или на одной тестовой машине во время тестирования), чтобы проверить влияние сети на систему.
Основное назначение stage-окружения заключается в тестировании всех сценариев установки/конфигурации/перемещения скриптов и процедур, прежде чем они будут применены в продакшен-окружении. Это гарантирует, что все существенные и незначительные обновления продакшен-окружения будут завершены качественно, без ошибок и в минимальные сроки.
Другим важным использованием stage-окружения является тестирование производительности, в частности нагрузочное тестирование, так как это часто чувствительно для окружения.
Stage-окружение также используется некоторыми организациями для предварительного просмотра новых функций и их отбора заказчиками или для утверждения интеграции с работающими версиями внешних зависимостей.
Продакшен-окружение
Продакшен-окружение также известно как live (в частности в применении к серверам) так как это окружение, с которым непосредственно взаимодействуют пользователи.
Развертывание в производственной среде является наиболее чувствительным шагом; это может осуществляться путем непосредственного развертывания нового кода (перезаписывания старого кода, так что только одна копия представлена в один момент времени), или путем развертывания изменения конфигурации. Это может принимать различные формы: параллельное развертывание новой версии кода и переключение на неё с изменением конфигурации; развертывание новой версии кода рядом со старым с соответствующим «флагом нового функционала», и последующее переключение на новую версию с изменением конфигурации, которая выполнит переключение этого «флага»; или развертывание отдельных серверов (один выполняет старый код, другой — новый) с перенаправлением трафика со старого на новый с изменением конфигурации на уровне маршрутизации трафика. Всё это, в свою очередь, может быть применено одновременно или выборочно, и на разных этапах.
Развертывание новой версии обычно требует перезапуска, если только нет возможности горячего переключения, и поэтому требует либо прерывания обслуживания (обычно это пользовательское ПО, когда приложения должны быть перезагружены), либо дублирования — постепенного перезапуска экземпляров «за спиной» у балансировщика нагрузки, либо заблаговременного запуска новых серверов с последующим простым перенаправлением трафика на новые сервера.
При выкатке нового релиза в продакшен, вместо немедленного развертывания для всех экземпляров или пользователей, его можно сначала развернуть на одном экземпляре или для части пользователей, а затем уже либо развернуть для всех экземпляров, либо поэтапно по фазам, чтобы оперативно отлавливать возникающие проблемы. Это похоже на staging, за исключением того, что делается в продакшене, и по аналогии с добычей угля называется canary release. Это добавляет сложности если несколько релизов запускаются одновременно, и, поэтому их обычно стараются делать быстро, чтобы избежать проблем совместимости.
Готовим тестовое окружение, или сколько тестовых инстансов вам нужно
Сколько в вашем проекте тестовых стендов — 5, 10 или больше 10? Навскидку, нужны стенды для каждой команды разработки, стенды для QA под каждый проект, менеджерам проектов тоже нужны стенды, а еще CI — трудно это все точно разграничить и не вызвать конфликтные ситуации. Одним словом, почему бы нам не делать тестовый стенд ровно тогда, когда он нужен? Нужен сейчас тестовый стенд — мы его сделали, не нужен — мы его удалили.
Именно такой подход предложил Александр Дубровин (adbrvn) на Highload++ 2017 в своем докладе, расшифровку которого вы найдете под катом.
О спикере: Александр Дубровин работает в Superjob. Известно, что проекты этой компании высоконагруженные. Но сегодня мы не будем говорить о том, сколько пользователей посещают портал, и сколько данных хранится на серверах, а затронем другие показатели.
Забегая вперед, скажем, что, на самом деле, Superjob не знают, сколько у них тестовых стендов. Но обо всем по порядку. Начнем с небольшой истории.
Немного истории
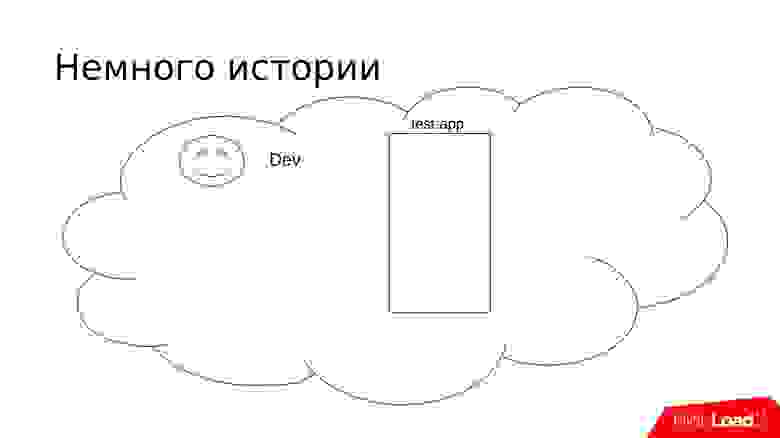
Представим себе небольшой проект S. В нем есть команда разработчиков, которым надо где-то тестировать свой код. Чтобы организовать тестирование, мы поставим тестовую машину, сделаем ее похожей на продакшен, накатим туда код, запустим и разработчики смогут там что-то тестировать.
В какой-то момент команда начинает расти, и необходим штат тестировщиков. Появляются QA-специалисты, и им тоже нужно где-то тестировать.
Можно использовать простой подход — выделить какой-то участок для тестировщиков, накатить туда такую же копию, и вот они уже могут тестировать. Все замечательно и хорошо!
Проект продолжает расти, и появляется дополнительная команда разработки. Им также требуется где-то что-то тестировать. Подход уже знаком — мы отделяем еще одну часть тестового сервера.
Но на самом деле команды тоже растут — по одному тестовому стенду им становится мало. Задач они тоже делают больше, поэтому тестировщикам нужно много тестировать.
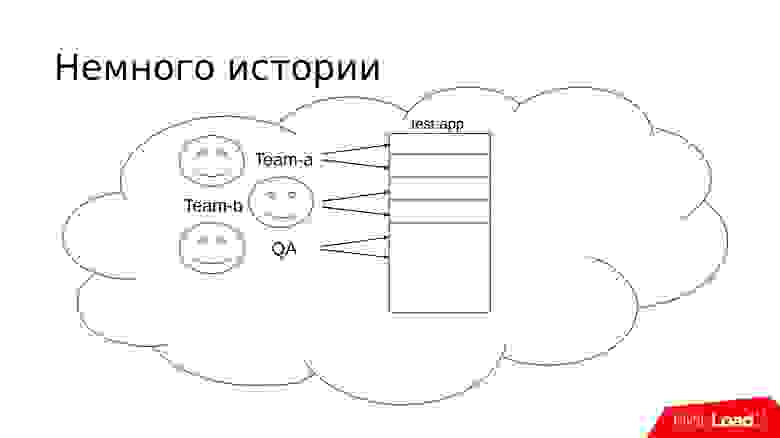
Примерно в такой стадии можно начать замечать интересные истории. Допустим, есть тестировщик Вася, который хочет протестировать какую-то задачу. Он выбирает тестовый стенд, раскатывает туда код и начинает тестировать. Кликает, кликает и понимает, что что-то не то, что-то не работает, и вообще задача не сделана.
В JIRA начинают падать тикеты, возле Васи начинают собираться разработчики со словами: «Да как же так? Все же сделано!» и кто-то наконец спрашивает: «А у тебя какая ветка на тест раскатана?» Вася смотрит — не та. Ветка быстро исправляется, тикеты в JIRA закрываются, все хорошо. Вася продолжает тестировать, у него все работает.
Но в это время в другом конце комнаты разработчик Вова думает: «Странно, а почему у меня не работает?» Но он быстро понимает, что ветка не та. Раскатывает ту, что нужно, и проблемы снова у Васи.
За пару итераций они понимают, что они просто тестируют на одном тестовом стенде и мешают друг другу. В результате время потрачено впустую, Вася и Вова недовольны.
Другая история. Разработчик Коля знает про Васины проблемы, заранее приходит к нему и спрашивает, какой тестовый стенд сейчас свободен. Вася указывает свободный, и все хорошо. Через пару дней они встречаются снова, и Вася спрашивает у Коли: «Ты нам тестовый стенд вернешь? Ты его занимал на часок, а уже 2 дня прошло».
И снова проблема — либо разработчику искать другой стенд, либо все будут бодро ждать, пока он закончит тестирование.
На самом деле на схеме выше отображено не все. Здесь не хватает менеджеров. Иногда менеджеры хотят смотреть еще не протестированный сырой код. Подход стандартный — мы снова выделяем уголок тестового сервера и делаем еще тестовые стенды.
Плавно развивая такую схему, мы получаем бесконтрольное изменение тестовых стендов. Схема плоха тем, что мы действительно не контролируем такие стенды — мы не знаем:
В этот момент мы задумались — что же делать? Зачем нам столько тестовых стендов? Почему бы нам не делать тестовый стенд ровно тогда, когда он нужен? Нужен сейчас тестовый стенд — мы его сделали, не нужен — мы его удалили.
Следующий шаг в этой идее — делать тестовый стенд под каждую ветку кода.
Вроде идея хорошая, но есть технические нюансы. Нам нужны стенды:
Суровая реальность
Еще есть суровая реальность, в которой у нас:
Сказано — сделано!
Docker/docker-compose
Во-первых, мы говорили о том, что тестовые стенды должны быть изолированными и максимально похожими. В наше время это позволяет реализовать docker. Он даст возможность запускать контейнеры. Очевидно, что одним контейнером мы не обойдемся, более того, нам надо запускать кучу похожих стеков. Поэтому нужен docker-compose.
Замечательно — мы будем использовать docker — это стильно, модно, молодежно.
Распиливаем монолит выделяем сервисы
Docker пропогандирует микросервисный подход и здесь мы встаем перед проблемой, потому что у нас монолит.
Вы когда-нибудь пробовали оценить, сколько стоит распилить монолит по микросервисам? Очевидно, что эта цифра измеряется в человеко-годах.
В какой-то момент мы посмотрели на компонентную схему нашей системы и увидели, что здесь у нас есть load-balancing, здесь — приложение на php, здесь — node.js-приложение. Почему бы нам не запускать именно это, как сервис. Давайте найдем то, что мы можем запускать в docker-контейнерах.
Настраиваем сеть
Дальше нам необходимо каким-то образом достучаться до нашего тестового стенда. Естественно, нам необходимо вытащить 80-ый порт наружу, чтобы браузер мог открыть наш тестовый стенд, но если такие стенды будут запускаться в рамках одной машины, нам нужно выдавать IP.
В документации имеется целый огромный раздел про настройку сетей.
Docker умеет использовать различные типы сетей. В нашем случае очень помогла сеть типа macvlan. Это технология, которая позволяет на одном физическом сетевом интерфейсе реализовывать пачку виртуальных сетевых интерфейсов. При этом docker сам будет управлять этими интерфейсами: создавать, добавлять на машину и получать уже внешние, по отношению к хост-машине, IP-адреса.
Таким образом мы можем запустить пачку контейнеров, дать фронт-контейнеру (балансеру) возможность получить внешний IP-адрес и открыть на нем 80-ый порт. Мы уже можем постучаться туда при помощи браузера.
Поднимаем DNS и API
Мы помним, что у нас есть доменные зоны и куча поддоменов. Таким образом, обратиться к тестовому стенду мы можем только по домену 2-го уровня. Здесь есть как колоссальный плюс, так и колоссальный минус:
Минус обходится на самом деле просто. Если нам приходится перекрывать домены, мы просто добавляем префикс и таким образом ограничиваем набор перекрываемых доменов — с этим уже можно мириться.
В нашем случае мы выбрали префикс sj. Получается, нам приходится перекрывать домены только с префиксом sj — таких явно немного.
Еще одна часть DNS — это API. Как уже говорилось, необходимо поднимать тестовые стенды быстро. Поэтому нам нужен DNS-сервер, который позволяет быстро добавлять и быстро убирать запись по API в автоматическом режиме.
Решение — PowerDNS. Этот сервер позволяет достаточно быстро и просто прикрутить к нему API и при помощи скриптов добавлять и удалять тестовые стенды.
Замечательно! Мы подняли и настроили DNS, научили наши контейнеры в него прописывать свои IP, но чего-то не хватает.
Делаем SSL-CA
Мы живем в XXI веке. Очевидно, что весь интернет — SSL и тестовые стенды должны поддерживать SSL. Достаточно много багов специфичны для SSL, и mixed content — только вершина айсберга.
Итого, нам нужен способ быстро получить сертификат и быстро его применить на поднимающийся тестовый стенд. В нашей компании уже был центр сертификации, основанный на OpenSSL. Здесь мы пошли простым методом написания своего велосипеда.
Велосипед пишется за один день и позволяет при помощи GET-запросов получать сертификаты, сгенерированные уже на конкретное имя домена.
Осталось самое малое. Нужно это автоматизировать, потому что мы же хотим все это делать одной кнопкой.
Автоматизируем
Для себя на начальном этапе мы написали консольный скрипт, который позволяет просто поднять тестовый стенд или его удалить.
Очевидно, тестировщикам это не очень удобно. Поэтому можно, например, сделать специальную сборку, которая соберет тестовый стенд и запустит его.
Но на самом деле самый крутой шаг в этом плане — это добавить такую кнопку прямо в JIRA-тикет. Представьте, ваш тестировщик открывает JIRA-тикет, читает требование, нажимает кнопку и получает через пару минут тестовый стенд — здорово же?
Плюсы
Минусы
Но есть и минусы, я бы сказал, нюансы в управлении стендов. Нужно научиться правильно ими управлять.
Первую версию своей системы мы выкатили на старый слабый сервер и настроили создание тестовых стендов под каждую новую ветку. Конечно, где-то через день-полтора сервер не справился — просто потому, что веток появляется очень много.
Тогда, мы перестали их создавать автоматически, а появилась кнопка в JIRA, CI научилась запускать и останавливать тестовые стенды, собирать с них логи.
Определенно есть класс задач, которые эта система не позволит решать. Например, часто всплывающая проблема — это общее время для всех контейнеров. Некоторые задачи было бы удобно тестировать, сдвинув время на сервере. Эта система, к сожалению, не позволяет решать такие задачи. Но такие задачи можно решить, добавив в код специальные ветки для тестирования, чтобы можно было, например, посмотреть, как поведет себя форма через 2 недели.
На входе мы имели систему тестовых стендов, которая заставляла нас искать тестовый стенд и не гарантировала нам то, что никто не будет мешать друг другу на этих тестовых стендах.
Было: «Вася, а какой тестовый свободный — мне свою задачу раскатить потестировать».
На выходе получилась одна кнопка, которую можно нажать и получить через пару минут готовый тестовый стенд под конкретную версию кода. Даже если этим стендом будет пользоваться несколько человек, гарантировано то, что эти люди хотят смотреть именно эту версию кода.
Стало: «Жму кнопку и через полторы минуты получаю новый тестовый стенд под конкретную задачу».
Бонусом мы получили все тесты в один клик. Как я уже говорил, любые тесты на любой ветке прямо из CI выбираются одной кнопкой. Дальше машина все сделает сама: поднимет тестовый стенд, обстреляет его, соберет с него логи и удалит.
Возвращаясь к своему первому вопросу, сколько же тестовых стендов нам нужно? Я не знаю, сколько нам нужно тестовых стендов, потому что сегодня их нужно 20, завтра — 15, послезавтра 25.
Но я точно знаю, что у нас ровно столько тестовых стендов, сколько нужно здесь и сейчас.
Время летит незаметно, и до фестиваля конференций РИТ++ осталось совсем немного, напомним он пройдет 28 и 29 мая в Сколково. Пользуясь случаем, приводим небольшую подборку заявок RootConf для широкого круга слушателей:


