Batch-normalization
Содержание
Идея [ править ]
Пакет [ править ]
Также существует «золотая середина» между стохастическим градиентным спуском и пакетным градиентным спуском — когда просматривается только некоторое подмножество обучающей выборки фиксированного размера (англ. batch-size). В таком случае такие подмножества принято называть мини-пакетом (англ. mini-batch). Здесь и далее, мини-пакеты будем также называть пакетом.
Ковариантный сдвиг [ править ]

Пакетная нормализация уменьшает величину, на которую смещаются значения узлов в скрытых слоях (т.н. ковариантный сдвиг (англ. covariance shift)).
Ковариантный сдвиг — это ситуация, когда распределения значений признаков в обучающей и тестовой выборке имеют разные параметры (математическое ожидание, дисперсия и т.д.). Ковариантность в данном случае относится к значениям признаков.
Простой способ решить проблему ковариантного сдвига для входного слоя — это случайным образом перемешать данные перед созданием пакетов. Но для скрытых слоев нейронной сети такой метод не подходит, так как распределение входных данных для каждого узла скрытых слоев изменяется каждый раз, когда происходит обновление параметров в предыдущем слое. Эта проблема называется внутренним ковариантным сдвигом (англ. internal covariate shift). Для решения данной проблемы часто приходится использовать низкий темп обучения (англ. learning rate) и методы регуляризации при обучении модели. Другим способом устранения внутреннего ковариантного сдвига является метод пакетной нормализации.
Свойства пакетной нормализации [ править ]
Кроме того, использование пакетной нормализации обладает еще несколькими дополнительными полезными свойствами:
Описание метода [ править ]
Данные параметры настраиваются в процессе обучения вместе с остальными параметрами модели.
Тогда алгоритм пакетной нормализации можно представить так:
Обучение нейронных сетей с пакетной нормализацией [ править ]
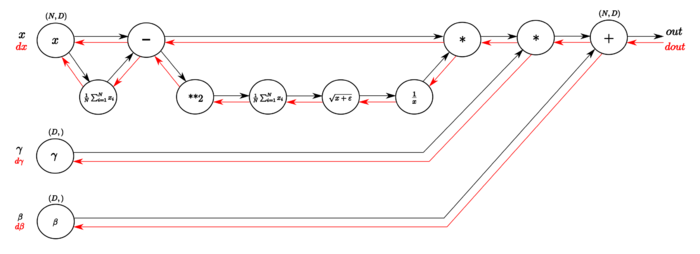
На Рисунке [math]2[/math] изображен граф вычислений слоя пакетной нормализации алгоритмом обратного распространения ошибки.
В обратном направлении вычисляются производные необходимых функций. В следующей таблице подробнее изображены шаги вычисления градиента функции потерь (иллюстрации из статьи, здесь [math]N=m[/math] и [math]D=d[/math] ):
Пакетная нормализация в свёрточных сетях [ править ]
Пакетная нормализация может быть применена к любой функции активации. Рассмотрим подробнее случай аффинного преобразования с некоторой нелинейной функцией:
где [math]BN[/math] применяется отдельно к каждой размерности [math]x=Wu[/math] с отдельной парой параметров [math]\gamma^<(k)>[/math] и [math]\beta^<(k)>[/math] для каждой размерности.
Индивидуальная нормализация [ править ]
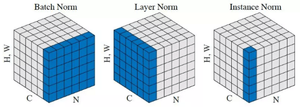
Условная пакетная нормализация [ править ]
Описание метода [ править ]
Выбор параметров нормализации [ править ]
В применении к переносу стиля [ править ]
![]()
Добавление условности [ править ]
Такой подход имеет много преимуществ по сравнению с наивным:
Когда использовать условную нормализацию? [ править ]
Во-первых, на условную нормализацию стоит обратить внимание, если вы настраиваете много сетей, решающих похожие задачи. Возможно, в этом случае вы можете использовать одну сеть с условными параметрами нормализации, зависящими от конкретной задачи. Например, при переносе стилей вместо [math]S[/math] сетей вы настраиваете одну сеть с [math]S[/math] наборами параметров нормализации.
Во-вторых, если вы подозреваете, что информация о структуре входных векторов имеет значение для выхода. Например, имеет смысл «слить» лингвистическую информацию и характеристики изображения для задачи ответа на визуальные вопросы (англ. Visual Question Answering, VQA).
Однако во всех случаях надо помнить, что полученные алгоритмы для разных задач будут различаться лишь параметрами свёртки и сжатия. Иначе говоря, если ваши задачи нельзя выразить аффинной комбинацией параметров сети после нормализации, условная нормализация не поможет.
Пример [ править ]
Реализации [ править ]
Приведем пример [11] применения пакетной нормализации с использованием библиотеки TensorFlow на языке программирования Python [12] :
Модификации [ править ]
Существует несколько модификаций и вариаций метода пакетной нормализации:
Эпоха, батч, итерация — в чем различия?
Вам должны быть знакомы моменты, когда вы смотрите на код и удивляетесь: “Почему я использую в коде эти три параметра, в чем отличие между ними?”. И это неспроста, так как параметры выглядят очень похожими.
Чтобы выяснить разницу между этими параметрами, требуется понимание простых понятий, таких как градиентный спуск.
Градиентный спуск
Это ни что иное, как алгоритм итеративной оптимизации, используемый в машинном обучении для получения более точного результата (то есть поиск минимума кривой или многомерной поверхности).
Градиент показывает скорость убывания или возрастания функции.
Спуск говорит о том, что мы имеем дело с убыванием.
Алгоритм итеративный, процедура проводится несколько раз, чтобы добиться оптимального результата. При правильной реализации алгоритма, на каждом шаге результат получается лучше. Таким образом, итеративный характер градиентного спуска помогает плохо обученной модели оптимально подстроиться под данные.
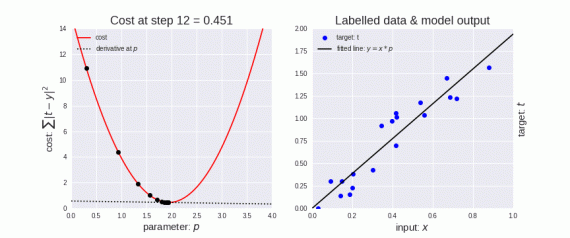
У градиентного спуска есть параметр, называемый скоростью обучения. На левой верхней картинке видно, что в самом начале шаги больше, то есть скорость обучения выше, а по мере приближения точек к краю кривой скорость обучения становится меньше благодаря уменьшению размера шагов. Кроме того, значение функции потерь (Cost function) уменьшается, или просто говорят, что потери уменьшаются. Часто люди называют функцию потерь Loss-функцией или просто «Лосс». Важно, что если Cost/Loss функция уменьшается, то это хорошо.
Как происходит обучение сети
Исследователи работают с гиганскими объемами данных, которые требуют соответствующих затрат ресурсов и времени. Чтобы эффективно работать с большими объемами данных, требуется использовать параметры (epoch, batch size, итерации), так как зачастую нет возможности загрузить сразу все данные в обработку.
Для преодоления этой проблемы, данные делят на части меньшего размера, загружают их по очереди и обновляют веса нейросети в конце каждого шага, подстраивая их под данные.
Epochs
Произошла одна эпоха (epoch) — весь датасет прошел через нейронную сеть в прямом и обратном направлении только один раз.
Так как одна epoch слишком велика для компьютера, датасет делят на маленькие партии (batches).
Почему мы используем более одной эпохи
Вначале не понятно, почему недостаточно одного полного прохода датасета через нейронную сеть, и почему необходимо пускать полный датасет по сети несколько раз.
Нужно помнить, что мы используем ограниченный датасет, чтобы оптимизировать обучение и подстроить кривую под данные. Делается это с помощью градиентного спуска — итеративного процесса. Поэтому обновления весов после одного прохождения недостаточно.
Одна эпоха приводит к недообучению, а избыток эпох — к переобучению:
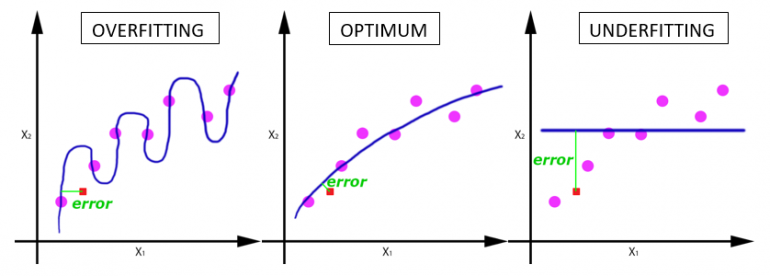
С увеличением числа эпох, веса нейронной сети изменяются все большее количество раз. Кривая с каждый разом лучше подстраивается под данные, переходя последовательно из плохо обученного состояния (последний график) в оптимальное (центральный график). Если вовремя не остановиться, то может произойти переобучение (первый график) — когда кривая очень точно подстроилась под точки, а обобщающая способность исчезла.
Какое количество эпох правильное?
На этот вопрос нет единственного точного ответа. Для различных датасетов оптимальное количество эпох будет отличаться. Но ясно, что количество эпох связано с разнообразием в данных. Например, в вашем датасете присутствуют только черные котики? Или это более разнообразный датасет?
Batch Size
Общее число тренировочных объектов, представленных в одном батче.
Отметим: Размер батча и число батчей — два разных параметра.
Что такое батч?
Нельзя пропустить через нейронную сеть разом весь датасет. Поэтому делим данные на пакеты, сеты или партии, так же, как большая статья делится на много разделов — введение, градиентный спуск, эпохи, Batch size и итерации. Такое разбиение позволяет легче прочитать и понять статью.
Итерации
Итерации — число батчей, необходимых для завершения одной эпохи.
Отметим: Число батчей равно числу итераций для одной эпохи.
Например, собираемся использовать 2000 тренировочных объектов.
Можно разделить полный датасет из 2000 объектов на батчи размером 500 объектов. Таким образом, для завершения одной эпохи потребуется 4 итерации.
Batch Normalization (батч-нормализация) что это такое?
Вам что-нибудь говорит термин внутренний ковариационный сдвиг:
internal covariance shift
Звучит очень умно, не так ли? И не удивительно. Это понятие в 2015-м году ввели два сотрудника корпорации Google:
Sergey Ioffe и Christian Szegedy (Иоффе и Сегеди)
решая проблему ускорения процесса обучения НС. И мы сейчас посмотрим, что же они предложили, как это работает и, наконец, что же это за ковариационный сдвиг. Как раз с последнего я и начну.
Давайте предположим, что мы обучаем НС распознавать машины (неважно какие, главное чтобы сеть на выходе выдавала признак: машина или не машина). Но, при обучении мы используем автомобили только черного цвета. После этого, сеть переходит в режим эксплуатации и ей предъявляются машины уже разных цветов:
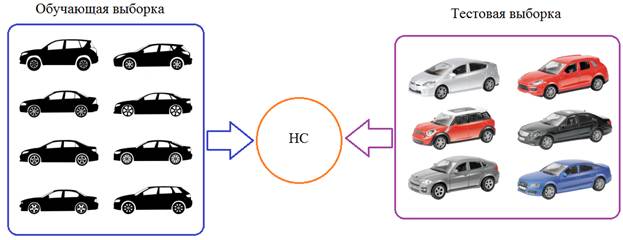
Как вы понимаете, это не лучшим образом скажется на качестве ее работы. Так вот, на языке математики этот эффект можно выразить так. Начальное распределение цветов (пусть это будут градации серого) обучающей выборки можно описать с помощью вот такой плотности распределения вероятностей (зеленый график):
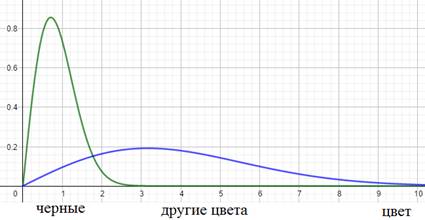
А распределение всего множества цветов машин, встречающихся в тестовой выборке в виде синего графика. Как видите эти графики имеют различные МО и дисперсии. Эта разница статистических характеристик и приводит к ковариационному сдвигу. И теперь мы понимаем: если такой сдвиг имеет место быть, то это негативно сказывается на работе НС.
Но это пример внешнего ковариационного сдвига. Его легко исправить, поместив в обучающую выборку нужное количество машин с разными цветами. Есть еще внутренний ковариационный сдвиг – это когда статистическая картина меняется внутри сети от слоя к слою:
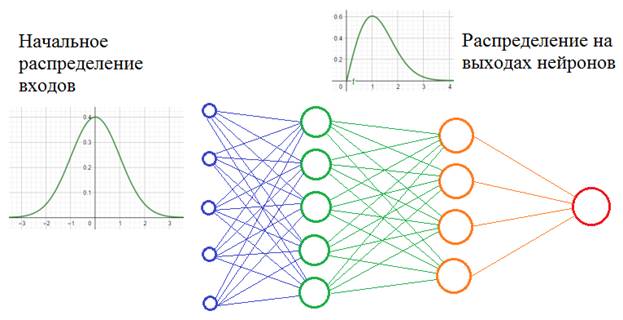
Само по себе такое изменение статистик не несет каких-либо проблем. Проблемы проявляются в процессе обучения, когда при изменении весов связей предыдущего слоя статистическое распределение выходных значений нейронов текущего слоя становится заметно другим. И этот измененный сигнал идет на вход следующего слоя. Это похоже на то, словно на вход скрытого слоя поступают то машины черного цвета, то машины красного цвета или какого другого. То есть, весовые коэффициенты в пределах мини-батча только адаптировались к черным автомобилям, как в следующем мини-батче им приходится адаптироваться к другому распределению – красным машинам и так постоянно. В ряде случаев это может существенно снижать скорость обучения и, кроме того, для адаптации в таких условиях приходится устанавливать малое значение шага сходимости, чтобы весовые коэффициенты имели возможность подстраиваться под разные статистические распределения.
Это описание проблемы, которую, как раз, и выявили сотрудники Гугла, изучая особенности обучения многослойных НС. Решение кажется здесь очевидным: если проблема в изменении статистических характеристик распределения на выходах нейронов, то давайте их стандартизировать, нормализовывать – приводить к единому виду. Именно это и делается при помощи предложенного алгоритма
Осталось выяснить: какие характеристики и как следует нормировать. Из теории вероятностей мы знаем, что самые значимые из них – первые две: МО и дисперсия. Так вот, в алгоритме batch normalization их приводят к значениям 0 и 1, то есть, формируют распределение с нулевым МО и единичной дисперсией. Чуть позже я подробнее поясню как это делается, а пока ответим на второй вопрос: для каких величин и в какой момент производится эта нормировка? Разработчики этого метода рекомендовали располагать нормировку для величин 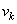 перед функцией активации:
перед функцией активации:
Но сейчас уже имеются результаты исследований, которые показывают, что этот блок может давать хорошие результаты и после функции активации.
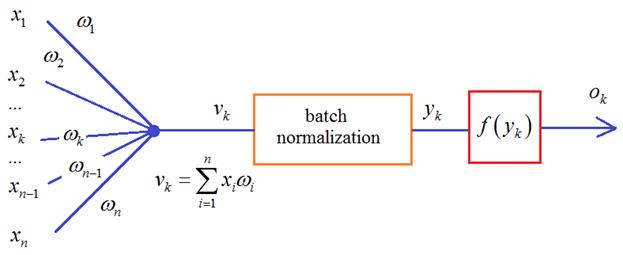
Что же из себя представляет batch normalization и где тут статистики? Давайте вспомним, что НС обучается пакетами наблюдений – батчами. И для каждого наблюдения из batch на входе каждого нейрона получается свое значение суммы:
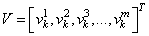
Здесь m – это размер пакета, число наблюдений в батче. Так вот статистики вычисляются для величин V в пределах одного batch:
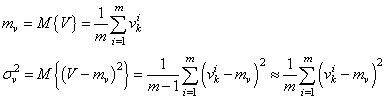
И, далее, чтобы вектор V имел нулевое среднее и единичную дисперсию, каждое значение преобразовывают по очевидной формуле:
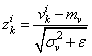
здесь 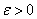 — небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
— небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
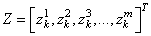
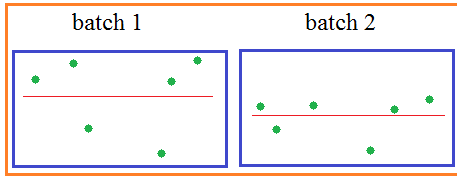
будет иметь нулевое МО и почти единичную дисперсию. Но этого недостаточно. Если оставить как есть, то будут теряться естественные статистические характеристики наблюдений между батчами: небольшие изменения в средних значениях и дисперсиях, т.е. будет уменьшена репрезентативность выборки:
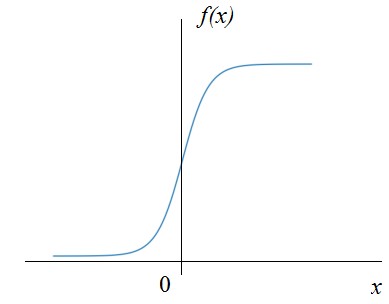
Кроме того, сигмоидальная функция активации вблизи нуля имеет практически линейную зависимость, а значит, простая нормировка значений x лишит НС ее нелинейного характера, что приведет к ухудшению ее работы:
Поэтому нормированные величины 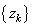 дополнительно масштабируются и смещаются в соответствии с формулой:
дополнительно масштабируются и смещаются в соответствии с формулой:

Параметры 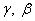 с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
Но это лишь возможные эффекты – они могут и не проявиться или даже, наоборот, применение этого алгоритма ухудшит обучаемость НС. Рекомендация здесь такая:
Изначально строить нейронные сети без batch normalization (или dropout) и если наблюдается медленное обучение или эффект переобучения, то можно попробовать добавить batch normalization или dropout, но не оба вместе.
Реализация batch normalization в Keras
Давайте теперь посмотрим как можно реализовать данный алгоритм в пакете Keras. Для этого существует класс специального слоя, который так и называется:
Он применяется к выходам предыдущего слоя, после которого указан в модели НС, например:
Здесь нормализация применяется к выходам скрытого слоя, состоящего из 300 нейронов. Правда в такой простой НС нормализация, скорее, негативно сказывается на обучении. Этот метод обычно помогает при большом числе слоев, то есть, при deep learning.
Видео по теме

Нейронные сети: краткая история триумфа

Структура и принцип работы полносвязных нейронных сетей | #1 нейросети на Python



Ускорение обучения, начальные веса, стандартизация, подготовка выборки | #4 нейросети на Python


Функции активации, критерии качества работы НС | #6 нейросети на Python



Как нейронная сеть распознает цифры | #9 нейросети на Python

Оптимизаторы в Keras, формирование выборки валидации | #10 нейросети на Python


Batch Normalization (батч-нормализация) что это такое? | #12 нейросети на Python

Как работают сверточные нейронные сети | #13 нейросети на Python

Делаем сверточную нейронную сеть в Keras | #14 нейросети на Python

Примеры архитектур сверточных сетей VGG-16 и VGG-19 | #15 нейросети на Python

Теория стилизации изображений (Neural Style Transfer) | #16 нейросети на Python

Делаем перенос стилей изображений с помощью Keras и Tensorflow | #17 нейросети на Python

Как нейронная сеть раскрашивает изображения | #18 нейросети на Python

Введение в рекуррентные нейронные сети | #19 нейросети на Python

Как рекуррентная нейронная сеть прогнозирует символы | #20 нейросети на Python

Делаем прогноз слов рекуррентной сетью Embedding слой | #21 нейросети на Python

Как работают RNN. Глубокие рекуррентные нейросети | #22 нейросети на Python


Как делать сентимент-анализ рекуррентной LSTM сетью | #24 нейросети на Python

Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа | #25 нейросети на Python

Двунаправленные (bidirectional) рекуррентные нейронные сети | #26 нейросети на Python

Автоэнкодеры. Что это и как работают | #27 нейросети на Python

Вариационные автоэнкодеры (VAE). Что это такое? | #28 нейросети на Python

Делаем вариационный автоэнкодер (VAE) в Keras | #29 нейросети на Python

Расширенный вариационный автоэнкодер (CVAE) | #30 нейросети на Python

Что такое генеративно-состязательные сети (GAN) | #31 нейросети на Python

Делаем генеративно-состязательную сеть в Keras и Tensorflow | #32 нейросети на Python
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Batch Normalization для ускорения обучения нейронных сетей
В современном мире нейронные сети находят себе всё больше применений в различных областях науки и бизнеса. Причем чем сложнее задача, тем более сложной получается нейросеть.
Обучение сложных нейронных сетей иногда может занимать дни и недели только для одной конфигурации. А чтобы подобрать оптимальную конфигурацию для конкретной задачи, требуется запустить обучение несколько раз — это может занять месяцы вычислений даже на действительно мощной машине.
В какой-то момент, знакомясь с представленным в 2015 году методом Batch Normalization от компании Google мне, для решения задачи связанной с распознаванием лиц, удалось существенно улучшить скорость работы нейросети.

За подробностями прошу под кат.
В данной статье я постараюсь совместить две актуальные на сегодняшний день задачи — это задача компьютерного зрения и машинного обучения. В качестве проектировки архитектуры нейронной сети, как я уже и указывал, будет использоваться Batch Normalization для ускорения обучения нейронной сети. Обучение же нейронной сети (написанной с использованием популярной в рамках computer vision библиотеки Caffe) проводилось на базе из 3 миллионов лиц 14 тысяч различных людей.
В моей задаче была необходима классификация на 14700 классов. База разбита на две части: тренировочная и тестовая выборки. Известна точность классификации на тестовой выборке: 94,5%. При этом для этого потребовалось 420 тысяч итераций обучения — а это почти 4 суток (95 часов) на видеокарте NVidia Titan X.
Изначально для данной нейросети использовались некоторые стандартные способы ускорения обучения:
Все эти методы были применены к данной сети но затем возможность их применять сошла на нет, т.к. стала уменьшаться точность классификации.
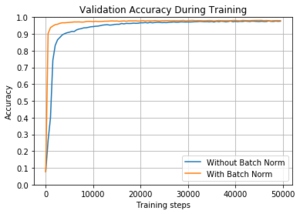
В этот момент я открыл для себя новый метод ускорения нейронных сетей — Batch Normalization. Авторы данного метода тестировали его на стандартной сети Inception на базе LSVRC2012 и получили хорошие результаты:
Из графика и таблицы видно что сеть обучилась в 15 раз быстрее и даже достигла более высокой точности в конечном итоге.
Что же из себя представляет Batch Normalization?
Рассмотрим классическую нейронную сеть с несколькими слоями. Каждый слой имеет множество входов и множество выходов. Сеть обучается методом обратного распространения ошибки, по батчам, то есть ошибка считается по какому-то подмножестве обучающей выборки.
Стандартный способ нормировки — для каждого k рассмотрим распределение элементов батча. Вычтем среднее и поделим на дисперсию выборки, получив распределение с центром в 0 и дисперсией 1. Такое распределение позволит сети быстрее обучатся, т.к. все числа получатся одного порядка. Но ещё лучше ввести две переменные для каждого признака, обобщив нормализацию следующим образом:
Получим среднее, дисперсию. Эти параметры будут входить в алгоритм обратного распространения ошибки.
Тем самым получаем batch normalization слой с 2*k параметрами, который и будем добавлять в архитектуру предложенной сети для распознавания лиц.
На вход в моей задаче подаётся черно-белое изображение лица человека размером 50×50 пикселей. На выходе имеем 14000 вероятностей классов. Класс с максимальной вероятностью считается результатом предсказания.
Оригинальная сеть при этом выглядит следующим образом:
Используется 8 свёрточных слоёв, каждый размером 3×3. После каждой свёртки, используется ReLU: max(x, 0). После блока из двух свёрток идёт max-pooling с размером ячейки 2×2 (без перекрытия ячеек). Последний pooling слой имеет размер ячейки 7×7, который усредняет значения, а не берёт максимум. В итоге получается массив 1x1x320, который и подаётся на полносвязный слой.
Сеть же с Batch Normalization выглядит несколько сложнее:
В новой архитектуре каждый блок из двух свёрток содержит слой Batch Normalization между ними. Также пришлось удалить один свёрточный слой из второго блока, так как добавление новых слоёв увеличило расход памяти графической карты.
При этом я убран Dropout в соответствии с рекомендациями по применению BN авторов оригинальной статьи.
Экспериментальная оценка
Основная метрика — точность, делим количество правильно классифицированных изображений на количество всех изображений в тестовой выборке.
Основная сложность в оптимизации нейросети с помощью слоя Batch Normalization — подобрать learning rate и правильно его изменять в процессе обучения сети. Чтобы сеть сходилась быстрее, начальный learning rate должен быть больше, а потом снижаться, чтобы результат был точнее.
Было протестированы несколько вариантов изменения learning rate:
| Имя | Формула изменения learning rate | Итераций до точности 80% | Итераций до полной сходимости | Максимальная точность |
|---|---|---|---|---|
| original | 0.01*0.1 [#iter/150000] | 64000 | 420000 | 94,5% |
| short step | 0.055*0.7 [#iter/11000] | 45000 | 180000 | 86,7% |
| multistep without dropout | 0.055*0.7 Nsteps | 45000 | 230000 | 91,3% |
[x] — целая часть
#iter — номер итерации
Nsteps — шаги заданные вручную на итерациях: 14000, 28000, 42000, 120000(x4),160000(x4), 175000, 190000, 210000.
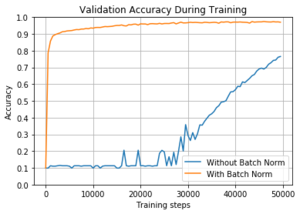
График, демонстрирующий процесс обучения: точность на тестовой выборке в зависимости от количества выполненных итераций обучения нейронной сети:
Оригинальная сеть сходится за 420000 итераций, при этом learning rate за всё время изменяется только 2 раза на 150000-ой итерации и на 300000-ой. Такой подход был предложен автором оригинальной сети, и мои эксперименты с этой сетью показали, что этот подход оптимален.
Но если присутствует слой Batch Normalization, такой подход даёт плохие результаты — график long_step. Поэтому моей идеей было — на начальной стадии менять learning rate плавно, а потом сделать несколько скачков (график multistep_no_dropout). График short_step показывает, что просто плавное изменение learing rate работает хуже. По сути здесь я опираюсь на рекомендации статьи и пытаюсь их применить к оригинальному подходу.
В итоге экспериментов я пришёл к выводу, что ускорить обучение можно, но точность в любом случае будет немного хуже. Можно сравнить задачу распознавания лиц с задачей рассмотренной в статьях Inception (Inception-v3, Inception-v4): авторы статьи сравнивали результаты классификации для различных архитектур и выяснилось, что всё-таки Inception-BN уступает новым версиям Inception без использования Batch Normalization. В нашей задаче получается такая же проблема. Но всё-таки если стоит задача как можно быстрее получить приемлимую точность, то BN как раз может помочь: чтобы достичь точности 80% требуется в 1,4 раза меньше времени по сравнению с оригинальной сетью (45000 итераций против 64000). Это можно использовать, например, для проектирования новых сетей и подбора параметров.
Программная реализация
Как я уже писал, в моей работе используется Caffe — удобный инструмент для глубинного обучения. Всё реализовано на C++ и CUDA, что обеспечивает оптимальное использование ресурсов компьютера. Для данной задачи это особенно актуально, т.к. если бы программа была написана не оптимально не было бы смысла ускорять обучение с помощью изменения архитектуры сети.
Caffe обладает модульностью — есть возможность подключить любой нейросетевой слой. Для слоя Batch Normalization удалось найти 3 реализации:
Для быстрого сравнения этих реализаций я взял стандартную базу Cifar10 и тестировал всё под операционной системой Linux x64, используя видеокарту NVidia GeForce 740M (2GB), процессор(4 ядра) Intel® Core(TM) i5-4200U CPU @ 1.60GHz и 4GB RAM.
Реализацию от caffe windows встроил в стандартный caffe, т.к. тестировал под Linux.
На графике видно, что 1-ая реализация уступает 2-ой и 3-ей по точности, кроме этого в 1-ом и 2-ом случаях точность предсказания изменяется скачками от итерации к итерации (в первом случае скачки намного сильнее). Поэтому для задачи распознавания лиц выбрана именно 3-я реализация (от NVidia) как более стабильная и более новая.
Данные модификации нейросети с помощью добавления слоев Batch Normalization показывают, что для достижения приемлемой точности (80%) потребуется в 1,4 раза меньше времени.


