Объектное хранилище для извлечения любых объемов данных из любого места
5 ГБ в хранилище S3 Standard
Масштабируйте ресурсы хранилища, чтобы соответствовать меняющимся потребностям с надежностью данных 99,999999999 % (11 9 секунд).
Храните данные в разных классах хранилища Amazon S3, чтобы сократить затраты за счет отсутствия авансовых вложений или периодического обновления оборудования.
Защитите данные благодаря самым широким возможностям по обеспечению безопасности, соблюдению законодательных требований и аудиту.
С легкостью управляйте данными в любом масштабе с помощью надежных средств контроля доступа, гибких инструментов репликации и
видимости целой организации.
Как это работает


Примеры использования
Создание озера данных
Запустите приложения для аналитики больших данных, искусственного интеллекта (ИИ), машинного обучения (ML) и высокопроизводительных вычислений (HPC), чтобы получить полезную информацию.
Резервное копирование и восстановление критически важных данных
Выполняйте нормативы по времени восстановления (RTO), точкам восстановления (RPO) и законодательные требования с помощью надежных возможностей репликации S3.
Архивация данных по наименьшей цене
Переместите локальные архивы в недорогие классы хранения Amazon S3 Glacier и Amazon S3 Glacier Deep Archive, избавившись от операционных сложностей.
Запуск приложений с оптимизацией для облака
Создавайте быстрые, мощные мобильные и оптимизированные для облака интернет-приложения, которые автоматически масштабируются до самой высокой доступной конфигурации.
Что такое хранилище S3?

Хранение бизнес-данных в облаке давно стало стандартом. Здесь они надежно защищены как от несанкционированного доступа, так и от внезапной утери. В последнее время все больше и больше компаний выбирают облачное объектное хранилище S3.
Просто о сложном
Главное преимущество S3-хранилища — возможность работы из любой географической точки с файлами любого типа и объема. Принцип работы S3 простой: данные помещаются во множество контейнеров (папок). Содержимое любого контейнера можно просматривать, перемещать или удалять. У каждого контейнера и объекта есть адрес в виде уникального идентификатора. Он используется, как ключ доступа к данным. Эти ключи могут иметь любое строковое значение. При необходимости, можно сделать так, чтобы ключи содержали важную для работы информацию — например, принадлежность объекта к какому-либо проекту.

Также объектам в каждом контейнере можно назначить теги. Каждый объект может иметь несколько тегов разного вида. Это пригодится, если нужно описать его максимально точно. Например, можно создать аудиофайл с тегами имени исполнителя, названий песен, названия альбома и прочей информации. В дальнейшем эти метаданные индексируются, что значительно облегчает и в разы ускоряет поиск нужных объектов по заданным признакам. Кроме того, при работе с ними нет запутанной иерархической файловой системы со сложными и длинными адресами.

Важный момент: работая с S3-хранилищем, вы знаете, где и в каком виде хранятся ваши данные, кто может получать к ним доступ и какие ресурсы использует ваша организация в любой момент времени. Средства идентификации и контроля доступа в сочетании с непрерывным мониторингом данных гарантируют безопасность.
Зачем использовать объектное хранилище
Скорее всего, вашей компании надо работать с большим объемом разных данных. Это могут быть записи системы видеонаблюдения, бэкапы, хостинг, хранение big data и многое другое. Если вы понимаете, что традиционного облачного хранилища для всего этого уже не хватает, и работа с корпоративным облаком становится все медленнее, значит пришло время для объектного хранилища. Оно поможет вам рационально организовать работу с любым количеством информации.
S3-облако от провайдера Serverspace позволяет хранить неограниченное количество файлов на Enterprise-оборудовании с SLA 99,9%. Тройная репликация надежно защищает данные на серверах и обеспечивает им гарантию безопасности от внешних угроз. Еще одно достоинство объектного хранилища Serverspace — полная совместимость с протоколами S3 и Swift.
Вот распространенные примеры использования S3:
Как подключиться к S3 хранилищу

Внутри него нельзя обрабатывать объекты, их туда можно либо загружать, либо скачивать. Кроме того, с ним работают не сами пользователи, а приложения или отдельные системы, которые подключаются по API. Основа API — протокол HTTP. Подключиться можно несколькими способами. Каждая компания сама решает, какой из них удобнее. Вот два наиболее популярных варианта.
S3Browser
S3Browser даст вам подключиться к хранилищу по протоколу S3. Пользоваться им просто — нужно ввести имя аккаунта, выбрать тип подключения «S3 Compatible Storage», указать адрес подключения, ID ключа доступа, значение секретного ключа и активировать в случае необходимости опцию шифрования данных при подключении. После этого можно начинать работать с облаком.

Swift API/Cyberduck
Чтобы настроить подключение по Swift API, после установки и запуска Cyberduck нужно указать, что вы подключаетесь к объектному облаку. Затем нужно задать название сервера, номер порта 443, ключ доступа и пароль. После этого можно приступать к работе.


Для чего нужны хранилища данных
| Для каких задач подходит S3 хранилище | |
|---|---|
| Обеспечение работы сайтов и мобильных приложений | ✓ |
| Архивация, анализ больших объемов данных | ✓ |
| Хранение статического контента, мультимедийных файлов | ✓ |
| Хранение пользовательских данных и бэкапов | ✓ |
| Раздача статических файлов | ✓ |
| Хранение данных backend-платформ | ✓ |
| Электронный документооборот | ✓ |
| Хранение историй транзакций и логов | ✓ |
| Хранение резервных копий ИС | ✓ |
| Хранение неструктурированных данных | ✓ |
Заключение
Услуга объектного S3-хранилища становится все популярнее среди различных компаний, которым нужно работать с большим объемом данных. Представляя собой высоконадежное решение, такое S3 может хранить миллиарды и даже триллионы файлов, а его объем может составлять сотни петабайт. Безопасность, надежность и отказоустойчивость делает его все востребованнее и популярнее.
Петабайты данных и быстрый поиск: зачем хранить файлы в облачном объектном хранилище
Большая часть современных компаний работает с огромными объемами данных, которые надо, во-первых, где-то хранить, а во-вторых — не потерять среди них что-нибудь важное. Объектные облачные хранилища (object cloud storage) легко справляются с решением этих проблем. Рассказываем, чем они отличаются от других видов хранилищ и какую информацию там лучше всего хранить.
Что такое объектное S3-хранилище
Объектное хранилище, или object storage, подходит для хранения и управления большими объемами информации: аудио и видеофайлы, документы, сообщения чатов, письма. Его используют, когда традиционная система хранения с множеством файлов и папок становится неудобной и неэффективной.
Компании могут развернуть объектное хранилище в собственном центре обработки данных (ЦОД) или воспользоваться услугой облачных провайдеров. Объектные хранилища взаимодействуют с приложениями через программный интерфейс — то есть, через команды, которые хранилище и приложения передают друг другу. Как правило, это интерфейсы S3 API, Swift API или CDMI.
Наличие стандартного интерфейса у хранилища позволяет без проблем его использовать большинству приложений и систем. S3-совместимые хранилища (S3 compatible storage) сейчас используют чаще всего.
В чем плюсы объектного хранения данных
Бывает, что нужно предоставить доступ к объектам хранения одновременно многим пользователям. Например — видеохостинг должен выдерживать тысячи запросов к выложенному видеоролику. Для таких задач не подходят «обычные» хранилища данных, в том числе — жесткие диски и облачные хранилища других типов, например, такие, где пользователи хранят свои фото: они не оптимизированы под параллельный доступ многих пользователей.
Объектные хранилища реализованы таким образом, что число обращений пользователей к объектам практически не замедляет доступ к ним.
При этом доступ к самому облачному объектному хранилищу данных возможен из любой точки мира, а совокупный объем загружаемых файлов может достигать десятков и сотен петабайт. Посмотрим, для чего его можно использовать.
Amazon S3 и все-все-все: выбираем объектное хранилище
Самые известные на мировом рынке объектные хранилища — это Amazon S3 (Simple Storage Service), Google Cloud Storage и Microsoft Blobs Storage. Они надежны, доступны через интернет и масштабируются до сотен петабайт. Наиболее популярный способ доступа к объектному хранилищу — S3 RESTful API от компании Amazon. Есть и альтернатива, OpenStack Swift — поддерживает оба API и даже имеет собственное (как у Microsoft или Google, например). Дополнительно предоставляется доступ по другим файловым и блочным протоколам вроде WebDAV, NFS и FTP, но в контексте этой статьи мы тестируем только доступ по протоколу HTTPS через разнообразные API.
Для сравнения возьмем отечественные публичные объектные хранилища. Их не так много, и мы рассмотрим наиболее заметных игроков российского рынка: Mail.Ru Cloud Solutions, servers.ru, Selectel, Техносерв и Ростелеком.
Предложения хранилищ большой западной тройки можно условно разделить на три части: объемы хранения, операции (запросы), трафик и дополнительные услуги — вроде Amazon S3 Storage Management, Amazon S3 Transfer Acceleration и межрегиональной репликации. Подробные прайсы есть на сайтах Amazon S3 (цены без налогов), Microsoft Blobs Storage (исходящий трафик) и Google Cloud Storage. Нас интересуют стандартные хранилища с «горячими» данными — для редко используемых данных и архивов многие провайдеры предлагают варианты дешевле, которые в этом обзоре мы не затрагиваем.
Основными составляющими стоимости услуг будут объёмы хранения, а также исходящий трафик за пределы сети облачного провайдера. Попробуем их оценить и для удобства переведём цены в рубли по курсу ЦБ РФ на 13 января 2018 г.

У отечественных компаний прайс-листы отличаются большим разнообразием (см. справку), мы для удобства пересчитаем их с ограничениями, которые использует большая западная тройка. Все цены в рублях с НДС 18%.
30 рублей в месяц или
3 рубля в месяц за 1 ГБ. Отдельно придётся оплатить поддержку версионности (0,50 рублей в сутки за 10 ГБ) и поддержку поиска по метаданным — 0,25 рублей за 10 ГБ в сутки (все цены в прайсе без учета НДС). Зато про трафик в прайс-листе ничего не сказано, но для Ростелекома это совершенно неудивительно.
Сферическое приложение в вакууме
Прайсы не очень наглядны, к тому же, в стоимость услуг заметную (часто — главную) роль играет исходящий трафик в интернет за пределы сети провайдера, поэтому мы попробуем прикинуть стоимость услуг на примере некоторого использующего объектное хранилище проекта. Допустим, мы хотим создать сервис и клиентское мобильное приложение к нему. Сразу возникает вопрос хранения статических и пользовательских данных. Есть мнение, что использовать объектные хранилища для статики накладно из-за больших объемов исходящего трафика — существуют отдельные провайдеры, которые позволяют создать сеть доставки и дистрибуции контента (CDN) с кеширующими серверами по всему миру. Если у вас крупный проект с огромным количеством пользователей — это может иметь смысл. Небольшие стартапы даже статику могут держать в объектном хранилище, но поскольку это все индивидуально, рассматривать такой сценарий мы не будем. Гораздо интереснее пользовательские данные. Благодаря постоянной доступности, возможностям масштабирования и способности выдерживать высокие нагрузки, объектное хранилище отлично подходит для пользовательских файлов любых форматов: фотографий, документов, видеороликов и т. д. Особенно хорошо это заметно на небольших проектах — несколько десятков тысяч файлов и несколько тысяч запросов в сутки обойдутся вам буквально в считанные доллары в месяц. Давайте теперь перейдём к расчётам. Пусть объём пользовательских данных будет достаточно ощутимым (для других вариантов все-таки есть традиционный хостинг) и составляет 1 ТБ — это примерно 5 миллионов фотографий или 50 тысяч небольших видеороликов. Пусть наш условный проект генерирует исходящий трафик в 1 ТБ в месяц. Давайте посчитаем в какую примерно сумму он нам обойдётся.
Особенности отечественных провайдеров
Mail.ru Cloud Solutions развивается аналогично западным сервисам. Помимо Hotbox заказчикам предлагают хранилище Icebox для редко используемых данных. S3-совместимый API позволяет подключаться к хранилищу при помощи множества разнообразных приложений и использовать коннекторы к разным языкам программирования.
Хранилище servers.ru использует OpenStack Swift (S3 API не поддерживается). Недорогих тарифных планов для редко используемых данных и архивов провайдер не предлагает — по сути дела это хороший вариант для хостинга, позволяющий, например, хранить статические данные сайтов и решать другие сходные задачи. Для корпоративной виртуальной инфраструктуры список услуг все-таки бедноват. Есть сведения, что провайдер строит приватные облака для клиентов и, в частности, делает там выделенные ceph-инсталляции. На сайте об этом не сообщается.
В Selectel все аналогично: доступ через OpenStack Swift (S3 API хранилище не поддерживает) и отсутствие отдельных тарифных планов для редко используемых данных, хотя очень вкусная цена сглаживает этот момент. Основное применение, как и в предыдущем случае — хостинг статических данных, сайтов и т. д.
Компания Техносерв запустила полноценное корпоративное объектное хранилище для бизнеса и вполне может поспорить с Mail.Ru Cloud Solutions. Заявлена полная совместимость с S3 API и есть отдельный тариф для хранения «холодных» данных. Недостаток один — с физическими лицами провайдер не работает.
Надежда национальной облачной платформы — хранилище Ростелеком использует Hitachi Content Platform и поддерживает S3 API, OpenStack Swift и некий REST API. Отдельные тарифные планы для редко используемых данных у Ростелекома отсутствуют, а настройка хранилища и доступа к нему, как бы это помягче выразиться, неочевидна. Для примера — статья [http://help.cloud.rt.ru/virthran/start/instrukcyas3browver] про доступ через S3 Browser — необходимость вручную кодировать login в base64 и считать хеш md5 для пароля радуют несказанно. С физическими лицами Ростелеком также не работает — все облачные услуги компании доступны только бизнесу и госструктурам.
Пинг из России
Увы, на стороне объектного хранилища мы не можем запускать программы, поэтому клиент-серверные измерялки пропускной способности канала (iperf и т. д.) использовать не получится. Мы пропингуем свои хранилища сотней маленьких (64 байта) и сотней больших (1 килобайт) пакетов с внешней по отношению ко всем подопытным виртуальной машины, работающей в одном из российских датацентров. Пакеты не бьются (0% потерь), но время отклика разное. У отечественных сервисов оно гораздо меньше, как и ожидалось — при обмене большими пачками мелких файлов это свою роль сыграет. Пропинговать Техносерв нет технической возможности, провайдер фильтрует ICMP.
Датацентры наших сервисов размещаются в Москве, большой западной тройки — в США.
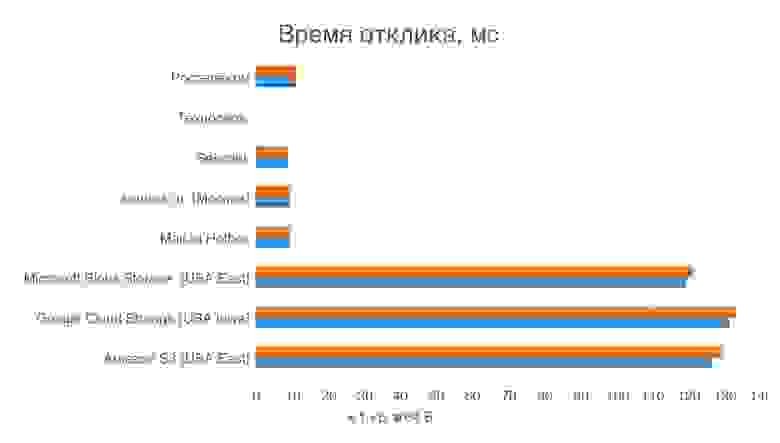
Нагрузочные тесты
Для тестирования производительности из России мы с внешней по отношению ко всем подопытным машины (та же, что и в предыдущем опыте) посмотрим скорость закачки файлов в хранилище и скорость скачивания. Для первого теста возьмём большой файл, а для второго — кучу мелких файлов россыпью. Сведём все результаты в диаграмму и взглянем на результат. Работать, разумеется, будем через REST API, которое поддерживает тот или иной сервис — при том разнообразные файловые и блочные протоколы нам неинтересны.
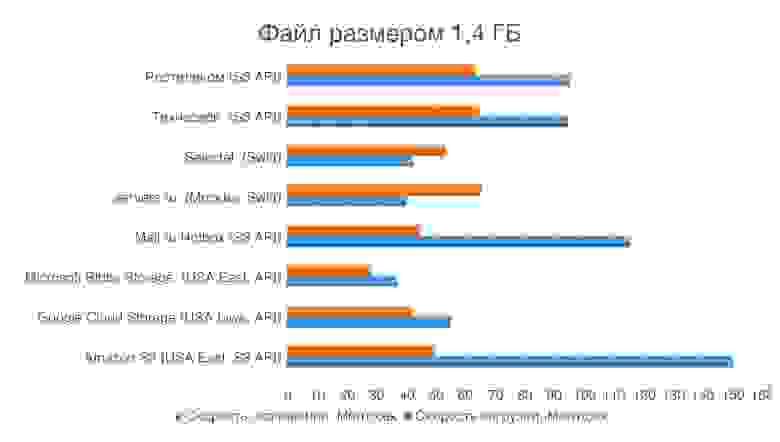
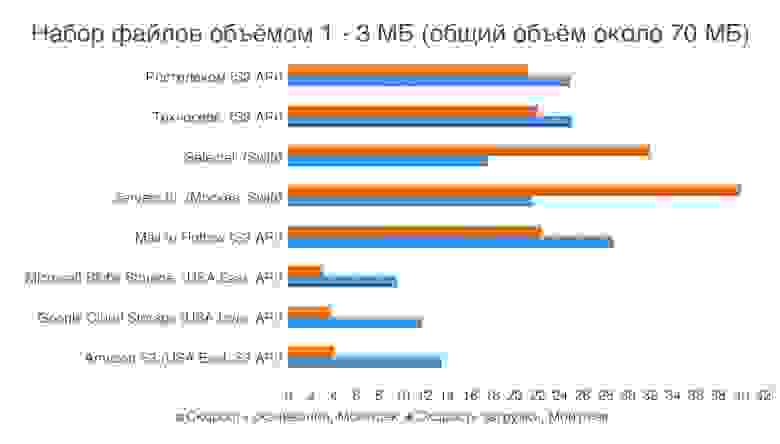
Для клиентов из России наши сервисы явно быстрее американских Google и Microsoft, а вот Amazon вполне способен с ними поспорить и даже серьезно обогнать по скорости загрузки большого файла. Хотя скачивается такой файл с отечественных хранилищ ощутимо быстрее. С набором мелких файлов картина совершенно иная — отечественные сервисы серьезно обгоняют зарубежные, что было ожидаемо. У публичных хранилищ Selectel и servers.ru обнаружилась интересная особенность: контент скачивается с них гораздо быстрее, чем закачивается (у других сервисов все наоборот). Это лишний раз подтверждает, что эти сервисы оптимизированы под раздачу статического контента и хороши для разнообразного хостинга, но хуже подходят для корпоративной ИТ-инфраструктуры.
Итоги
Отечественные провайдеры достойно конкурируют с большой западной тройкой. Мы тестировали публичные хранилища для горячих данных, и наличие датацентров в России (читай — в Москве) здорово им помогает. Хотя Amazon в состоянии дать высокую скорость на больших (1,4 ГБ) файлах, с пачками мелких наши сервисы работают гораздо быстрее, что важно: основные сценарии применения все-таки предполагают работу с большим количеством мелких файлов. По ценам все не так однозначно — есть варианты гораздо дешевле иностранных аналогов, есть и дороже (разброс достаточно большой). У servers.ru и Selectel отсутствуют недорогие тарифные планы для редко используемых данных. Это станет проблемой, если вы соберётесь развернуть на их площадке виртуальную ИТ-инфраструктуру компании (не хотелось бы по полной программе оплачивать хранение бекапов и архивов). Зато они очень быстро отдают статический контент и хороши для хостинга. Услуги Ростелекома сложны в настройке, но список поддерживаемых API у него самый широкий и скорости хранилище обеспечивает впечатляющие. Хотя отдельного тарифа для редко используемых данных там тоже нет. Для корпоративного применения наиболее интересны предложения Mail.ru и Техносерв — тут тебе и поддержка S3 API, и отдельные тарифы для редко используемых данных, и приличные скорости доступа. В общем, есть из чего выбрать.
Еще один плюс российских сервисов — отсутствие конфликтов с законодательством (все мы помним о работе с персональными данными). Даже собирая анкетные сведения о пользователях сайта, вы можете ненароком получить серьезный штраф, если информация будет храниться за пределами страны. Тут лидеры мирового рынка не смогут ничего противопоставить местным игрокам (у сервисов Amazon, Google и Microsoft датацентров в России нет).
Как устроено S3 хранилище DataLine
Не секрет, что в работе современных приложений задействованы огромные объемы данных, и их поток постоянно растет. Эти данные нужно хранить и обрабатывать, зачастую с большого числа машин, и это непростая задача. Для ее решения существуют облачные объектные хранилища. Обычно они представляют из себя реализацию технологии Software Defined Storage.
В начале 2018 года мы запускали (и запустили!) собственное 100% S3-совместимое хранилище на основе Cloudian HyperStore. Как оказалось, в сети очень мало русскоязычных публикаций о самом Cloudian, и еще меньше — о реальном применении этого решения.
Сегодня я, основываясь на опыте DataLine, расскажу вам об архитектуре и внутреннем устройстве ПО Cloudian, в том числе, и о реализации SDS от Cloudian, базирующейся на ряде архитектурных решений Apache Cassandra. Отдельно рассмотрим самое интересное в любом SDS хранилище — логику обеспечения отказоустойчивости и распределения объектов.
Если вы строите свое S3 хранилище или заняты в его обслуживании, эта статья придется вам очень кстати.
В первую очередь, я объясню, почему наш выбор пал на Cloudian. Всё просто: достойных вариантов в этой нише крайне мало. Например, пару лет назад, когда мы только задумывали строительство, опций было всего три:
И да, самое (безусловно!) главное — у DataLine и Cloudian похожие корпоративные цвета. Согласитесь, перед такой красотой мы не могли устоять.
К сожалению, Cloudian — не самое распространенное ПО, и в рунете информации о нём практически нет. Сегодня мы исправим эту несправедливость и поговорим с вами об особенностях архитектуры HyperStore, изучим его наиболее важные компоненты и разберемся с основными архитектурными нюансами. Начнем с самого основного, а именно — что же находится у Cloudian под капотом?
Как устроено хранилище Cloudian HyperStore
Давайте взглянем на схему и посмотрим, как устроено решение от Cloudian.

Основная компонентная схема хранилища.
Как мы видим, система состоит из нескольких основных компонентов:
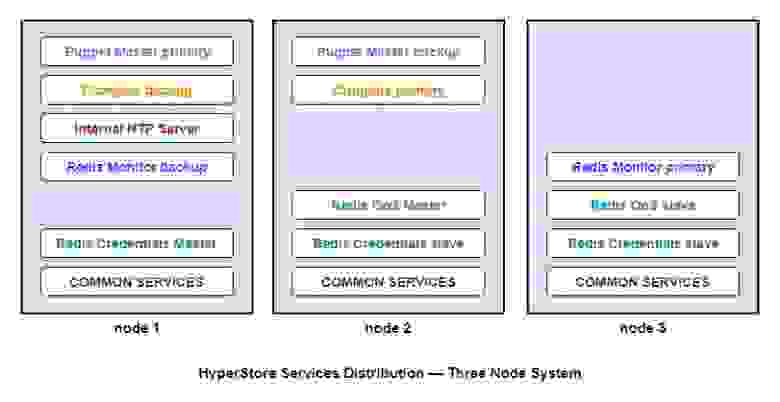
Под common services в схеме выше имеются в виду сервисы S3, HyperStore, CMC и Apache Cassandra. На первый взгляд, все красиво и аккуратно. Но при более детальном рассмотрении выясняется, что эффективно отрабатывается только одиночный отказ ноды. А одновременная потеря сразу двух нод может стать фатальной для доступности кластера — у Redis QoS (на node 2) есть только 1 slave (на node 3). Такая же картина с риском потери управления кластером — Puppet Server есть только на двух нодах (1 и 2). Впрочем, вероятность отказа сразу двух узлов очень невысока, и с этим вполне можно жить.
Тем не менее, для повышения надежности хранилища мы в DataLine используем 4 ноды вместо минимальных трёх. Получается следующее распределение ресурсов:
Сразу бросается в глаза еще один нюанс — Redis Credentials ставится не на каждую ноду (как можно было предположить из официальной схемы выше), а только на 3 из них. При этом Redis Credentials используется при каждом входящем запросе. Получается, из-за необходимости ходить в чужой Redis есть некоторый перекос в производительности четвертой ноды.
Для нас это пока несущественно. При нагрузочном тестировании значительных отклонений в скорости отклика ноды замечено не было, но на больших кластерах в десятки рабочих нод есть смысл поправить этот нюанс.
Вот так выглядит схема миграции на 6 нодах:

Из схемы видно, как реализована миграция сервиса при отказе ноды. Учитывается только случай отказа одного сервера каждой роли. Если упадут оба сервера, потребуется ручное вмешательство.
Здесь дело тоже не обошлось без некоторых тонкостей. Для миграции ролей используется Puppet. Поэтому, если вы потеряете его или случайно сломаете, automatic failover может не сработать. По этой же причине не стоит вручную править манифесты встроенного Puppet. Это не совсем безопасно, изменения могут быть внезапно перетерты, так как манифесты редактируются с помощью админки кластера.
С точки зрения сохранности данных всё значительно интереснее. Метаданные объектов хранятся в Apache Cassandra, и каждая запись реплицирована на 3 ноды из 4-х. Для хранения данных также используется фактор репликации 3, но можно настроить и больший. Это гарантирует сохранность данных даже при одномоментном отказе 2-х нод из 4-х. А при наличии времени на перебалансировку кластера можно и с одной оставшейся нодой ничего не потерять. Главное, чтобы хватило места.

Вот что происходит при отказе двух нод. На схеме хорошо видно, что даже в этой ситуации данные остаются сохранными
При этом доступность данных и хранилища будет зависеть от стратегии обеспечения консистентности. Для данных, метаданных, чтения и записи она настраивается отдельно.
Допустимые варианты — хотя бы одна нода, кворум или все ноды.
Эта настройка определяет, сколько нод должны подтвердить запись/чтение, чтобы запрос считался успешным. Мы используем кворум как разумный компромисс между временем на обработку запроса и надежностью записи/противоречивостью чтения. То есть из трех нод, задействованных в операции, для безошибочной работы достаточно получить непротиворечивый ответ от 2-х. Соответственно, чтобы остаться на плаву при отказе более чем одной ноды, понадобится перейти в стратегию единичной записи/чтения.
Отработка запросов в Cloudian
Ниже мы рассмотрим две схемы отработки входящих запросов в Cloudian HyperStore, PUT и GET. Это основная задача для S3 Service и HyperStore.
Начнем с того, как обрабатывается запрос на запись:
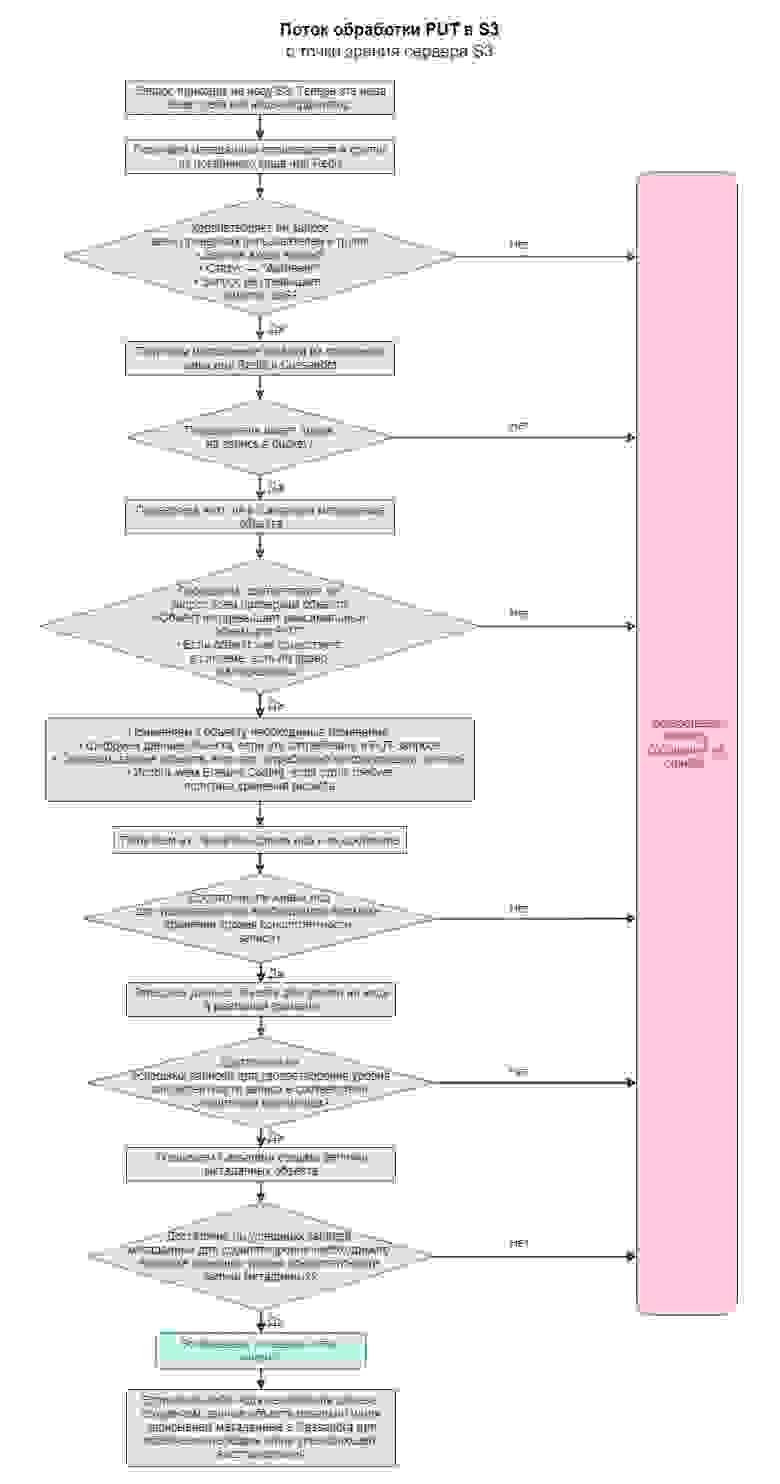
Наверняка вы отметили, что каждый запрос генерирует очень много проверок и извлечений данных, минимум 6 обращений от компонента к компоненту. Именно отсюда появляются задержки записи и высокий расход времени CPU при работе с маленькими файлами.
Крупные файлы передаются чанками. Отдельные чанки не рассматриваются как отдельные запросы и часть проверок не проводится.
Нода, получившая исходный запрос, дальше самостоятельно определяет, куда и что писать, даже если непосредственно на нее запись не производится. Это позволяет скрыть от конечного клиента внутреннюю организацию кластера и использовать внешние балансировщики нагрузки. Всё это положительно сказывается на удобстве обслуживания и отказоустойчивости хранилища.
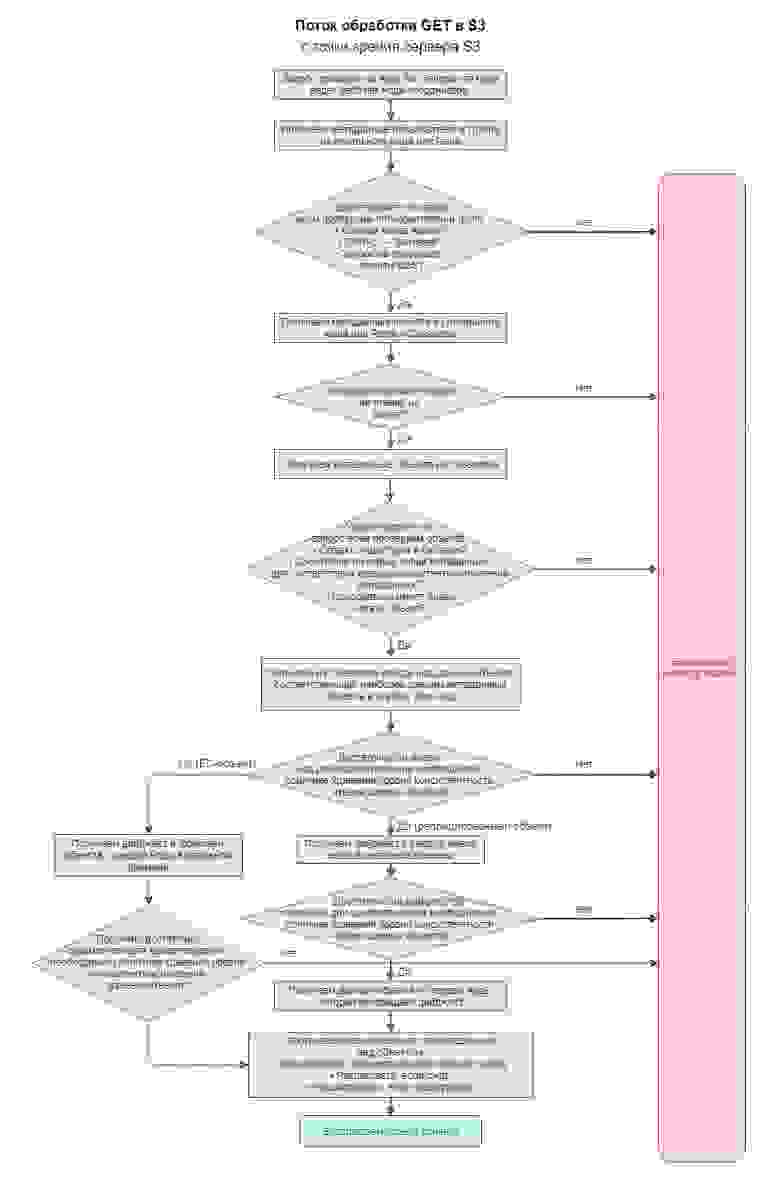
Как видите, логика чтения не слишком отличается от записи. В ней наблюдается такая же высокая чувствительность производительности к размеру обрабатываемых объектов. Следовательно, из-за существенной экономии на работе с метаданными извлекать один мелко нарезанный объект значительно проще, чем множество отдельных объектов того же общего объема.
Хранение и дублирование данных
Как видно из приведенных выше схем, Cloudian поддерживает различные схемы хранения и дублирования данных:
Репликация — с помощью репликации возможно поддерживать в системе настраиваемое количество копий каждого объекта данных и хранить каждую копию на разных узлах. Например, с помощью 3X репликации создается 3 копии каждого объекта, и каждая копия «лежит» на своей ноде.
Erasure Coding — с помощью erasure coding каждый объект кодируется в настраиваемое количество (известное как число K) фрагментов данных плюс настраиваемое количество кода избыточности (число M). Каждые K + M фрагменты объекта уникальны, и каждый фрагмент хранится на своем узле. Декодирован объект может быть с помощью любых K фрагментов. Другими словами, объект остается читаемым, даже если M узлов недоступны.
Например, в erasure coding по формуле 4+2 (4 фрагмента данных плюс 2 фрагмента кода избыточности) каждый объект расщепляется на 6 уникальных фрагментов, хранящихся на шести различных узлах, и этот объект может быть восстановлен и прочтен, если любые 4 из 6 фрагментов доступны.
Плюс Erasure Coding по сравнению с репликацией состоит в экономии места, пусть и ценой значительного роста нагрузки на процессор, ухудшения скорости отклика и необходимости работы фоновых процедур по контролю консистентности объектов. В любом случае, метаданные хранятся отдельно от данных (в Apache Cassandra), что повышает гибкость и надежность работы решения.
Кратко о прочих функциях HyperStore
Как я уже писал в начале статьи, в HyperStore встроено несколько полезных инструментов. Среди них:
Логика работы Cloudian HyperStore
Теперь мы погрузимся еще глубже и посмотрим на самое интересное в любом SDS хранилище — логику распределения объектов по нодам. В случае с хранилищем Cloudian, метаданные хранятся отдельно от самих данных. Для метаданных используется Cassandra, для данных — проприетарное решение HyperStore.
К сожалению, пока что в интернете отсутствует официальный перевод документации Cloudian на русский язык, поэтому ниже я помещу свой перевод наиболее интересных частей этой документации.
Роль Apache Cassandra в HyperStore
В HyperStore Cassandra используется для хранения метаданных объекта, данных учетной записи пользователя и данных об использовании сервиса. При типичном развертывании на каждом узле HyperStore данные Cassandra хранятся на том же диске, что и ОС. Система также поддерживает данные Cassandra на выделенном диске на каждом узле. Данные Cassandra не хранятся на дисках данных HyperStore. Когда vNodes назначаются хост-машине, они распределяются только по узлам хранения данных HyperStore. vNodes не выделяются на диск, где хранятся данные Cassandra.
Внутри кластера метаданные в Cassandra реплицируются в соответствии с политикой (стратегией) вашего хранилища. Репликация данных Cassandra использует vNodes таким образом:
Как работает хранилище HyperStore
В «классическом» хранилище, основанном на консистентном хэшировании, один токен присваивается одному физическому узлу. Система Cloudian HyperStore использует и расширяет функциональность «виртуального узла» (vNode), введенную в Cassandra в версии 1.2, — каждому физическому хосту присваивается большое количество токенов (максимум 256). По сути, кластер хранилища состоит из очень большого количества «виртуальных узлов» с большим количеством виртуальных узлов (токенов) на каждом физическом хосте.
Система HyperStore назначает отдельный набор токенов (виртуальных узлов) каждому диску на каждом физическом хосте. Каждый диск на хосте отвечает за свой набор реплик объектов. Сбой на диске затрагивает только те реплики объектов, которые находятся на нем. Другие диски на хосте продолжат работать и выполнять свои обязанности по хранению данных.
Приведем пример и рассмотрим кластер из 6 хостов HyperStore, на каждом из которых находится по 4 диска S3-хранилища. Предположим, что каждому физическому хосту назначено 32 токена и существует упрощенное пространство токенов от 0 до 960, а значения 192 токенов в этой системе (6 хостов по 32 токена) — это 0, 5, 10, 15, 20 и так далее до 955.
На приведенной ниже схеме приводится одно возможное распределение токенов по всему кластеру. 32 токена каждого хоста распределены равномерно по 4 дискам (8 токенов на диск), а сами токены случайным образом распределены по кластеру.

Теперь предположим, что вы настроили HyperStore на 3X репликацию объектов S3. Условимся, что объект S3 загружается в систему, и алгоритм хеширования, примененный к его имени, дает нам хеш-значение 322 (в этом упрощенном хэш-пространстве). На приведенной ниже схеме показано, как три экземпляра или реплики объекта будут храниться в кластере:
Добавлю комментарий: с практической точки зрения эта оптимизация (распределение токенов не только по физическим нодам, но и по отдельным дискам) нужна не только для обеспечения доступности, но и для равномерности распределения данных между дисками. При этом RAID-массив не используется, всей логикой размещения данных на дисках управляет сам HyperStore. С одной стороны, это удобно и контролируемо, при потере диска всё самостоятельно перебалансируется. С другой стороны, лично я хорошим RAID-контроллерам доверяю больше — всё-таки их логика работы оптимизируется уже много лет. Но это всё лично мои предпочтения, на реальных косяках и проблемах мы HyperStore ни разу не ловили, если соблюдать рекомендации вендора при установке ПО на физические сервера. А вот попытка использовать виртуализацию и виртуальные диски поверх одного и того же луна на СХД окончилась неудачей, при перегрузке СХД во время нагрузочного тестирования HyperStore сходил с ума и раскидывал данные совершенно неравномерно, забивая одни диски и не трогая другие.
Устройство диска внутри кластера
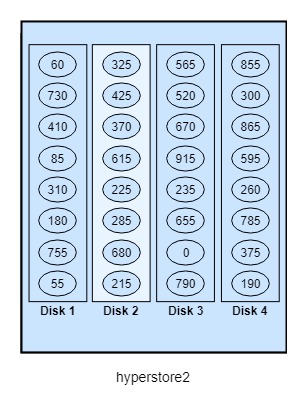
Напомним, что у каждого хоста по 32 токена, а токены каждого хоста равномерно распределены между его дисками. Давайте детально рассмотрим hyperstore2:Disk2 (на схеме ниже). Мы видим, что этому диску присвоены токены 325, 425, 370 и так далее.
Так как кластер сконфигурирован для 3X-репликации, на hyperstore2:Disk2 будет храниться следующее:
Как было замечено ранее, при размещении вторых и третьих реплик HyperStore может в некоторых случаях пропускать токены, чтобы не хранить больше одной копии объекта на одном физическом узле. Это исключает использование hyperstore2:disk2 как хранилища для вторых или третьих реплик одного и того же объекта.
При сбое Диска 2 на Дисках 1, 3 и 4 продолжат храниться данные, и объекты на Диске 2 сохранятся в кластере, т.к. были реплицированы на другие хосты.
Комментарий: в итоге, распределение реплик и/или фрагментов объектов в кластере HyperStore строится на доработанном под нужды файлового хранилища дизайне Cassandra. Чтобы понять, куда поместить объект физически, берется некий хэш от его имени и, в зависимости от его значения, выбираются пронумерованные «токены» для размещения. Токены заранее случайно распределены по кластеру с целью балансировки нагрузки. При выборе номера токена для размещения учитываются ограничения на размещение реплик и частей объекта на одни и те же физические ноды. К сожалению, у такого дизайна возникает побочный эффект: если нужно добавить или убрать ноду в кластере, придется заново перетасовывать данные, а это достаточно ресурсоемкий процесс.
Единое хранилище в нескольких ЦОД
Теперь давайте посмотрим, как у HyperStore работает геораспределенность в нескольких ЦОДах и регионах. В нашем случае мультиЦОД-режим от мультирегионального отличается использованием одного или нескольких пространств токенов. В первом случае пространство токенов едино. Во втором каждый регион будет иметь независимое пространство токенов с (потенциально) своими собственными настройками уровня консистентности, емкости и конфигурациями хранилища.
Чтобы понять, как это работает, снова обратимся к переводу документации, раздел «Multi-Data Center Deployments».
Рассмотрим развертывание HyperStore в двух дата-центрах. Назовем их DC1 и DC2. В каждом дата-центре расположено по 3 физических узла. Как и в наших предыдущих примерах, каждый физический узел имеет четыре диска, каждому хосту назначаются 32 токена (vNodes), и мы предполагаем упрощенное пространство токенов от 0 до 960. Согласно такому сценарию с несколькими дата-центрами, пространство токенов делится на 192 токена — по 32 токена на каждый из 6 физических хостов. По хостам токены распределены абсолютно случайно.
Также предположим, что репликация объектов S3 в данном случае настроена на двух репликах в каждом дата-центре.
Давайте рассмотри, как гипотетический объект S3 со значением хэша 942 будет реплицироваться в 2 дата-центрах:
Комментарий: еще одно свойство приведенной выше схемы в том, что для нормальной работы политик хранения, затрагивающих оба ЦОДа, объем места, количество нод и дисков на ноде должно совпадать в обоих ЦОДах. Как я уже говорил выше, мультирегиональная схема такого ограничения не имеет.


