Стандартное отклонение (Standard Deviation)

Стандартное отклонение (σ, s) – это мера разброса в наборе числовых данных. Выражаясь простыми словами, насколько далеко от Cреднего арифметического (Mean) находятся точки данных. Его также можно назвать мерой центральной тенденции: чем меньше стандартное отклонение, тем более «сгруппированы» данные вокруг центра (среднего). Чем отклонение больше, тем больше разброс значений.
Стандартное отклонение в статистике
Метрика рассчитывается с помощью следующей формулы:
Пример. Мы располагаем Выборкой (Sample) из 10 наблюдений, где указано, сколько килограммов томатов собрали дачники в этом месяце:

Средним значением выборки будет 7,7:
$$\bar
Следуя формуле, вычислим квадрат разницы между i-м элементом выборки и средним значением. К примеру, для первого вхождения это будет:

Причина, по которой мы возводим разницы в квадрат, заключается в том, что большие отклонения от среднего как бы «наказываются» более сурово. Возведение в квадрат также приводит одинаковому учету отклонений в обоих направлениях (положительном и отрицательном), то есть расстояние от среднего значения у отрицательного и положительного числа будет рассчитано верно в обоих случаях.
Суммой значений правого столбца является число 64,1. Итак, согласно формуле стандартное отклонение будет равно:
Стандартное отклонение в Машинном обучении
Представьте, что перепись «томатного» населения приобрела более широкие масштабы, и исследователи собрали данные о целом климатическом поясе. Мало тех, кто собрал по 2 килограмма, и тех, кто собрал 50. В среднем, садоводы собирали 25 кг.

При создании модели прогнозирования урожая стандартное отклонение уточняет наши предположения с помощью следующих принципов:
Библиотека Statistics
Рассчитывание стандартного отклонения выполняется мгновенно с помощью библиотеки statistics:
Описательные статистики
Первичные описательные статистики – это наиболее простые характеристики, которыми можно описать психологические данные, которые были получены в ходже тестирования испытуемых.
К наиболее часто используемым в курсовых и дипломных по психологии описательным статистикам можно отнести:
Среднее значение
Простейшая математическая процедура, которую необходимо освоить студенту-психологу при написании диплома – расчет среднего значения.
Среднее значение или среднее арифметическое – это число, получаемое как сумма нескольких показателей, деланная на количество этих показателей. Например, в результате тестирования были получены показатели тревожности в группе из 10-ти человек. Чтобы получить среднее значение тревожности по группе нужно сложить показатели всех испытуемых, а затем получившуюся сумму разделить на 10.
Среднее значение характеризует группу целиком. Зная среднее можно оценить показатели каждого испытуемого относительно остальных. Например, измеряемая в приведённом выше примере тревожность могла быть от 1 до 5 баллов. Пусть средняя по группе тревожность оказалась 3,5 балла. Тогда, показатель испытуемого в 4 балла можно считать относительно высоким, а в 2 балла- относительно низким.
Среднее значение относится к показателям центральной тенденции и отражает степень выраженности показателя в группе. Стандартное отклонение отражает степень изменчивости признака в группе, но о нем речь впереди.
Среднее значение какого-либо показателя характеризует группу в целом и позволяет сравнивать ее с другими группами. Например, проведена диагностика уровня эмпатии в группе мужчин и женщин. Как узнать, влияет ли пол на способность к эмпатии. Один из способов – найти средний уровень этого показателя в группах мужчин и женщин. Например, в группе женщин средний уровень эмпатии равен 23,5 баллов, а в группе мужчин – 17,7 баллов. Как видно, в среднем у женщин эмпатия выше, чем у мужчин.
Среднее – это не единственный статистический показатель, который отражает выраженность переменной в группе. Аналогичную функцию выполняют мода и медиана. Однако они редко используются в дипломах по психологии.
Средние значения выраженности психологических показателей в курсовой или дипломной по психологии представляются в виде таблиц и диаграмм. В таблицах среднее обозначается буквой «М».
Стандартное отклонение
Если среднее арифметическое отражает выраженность показателя в группе, то стандартное отклонение (среднеквадратичное отклонение) показывает его разброс данных или изменчивость. Чем больше величина стандартного отклонения, тем больше разброс показателей в группе испытуемых.
Например, группу мальчиков протестировали методикой на выявление уровня эгоцентризма, показатели которого изменяются от 1 до 10. Расчет среднего показал М=6,5, а стандартное отклонение σ=3 (стандартное отклонение обозначается буквой «сигма»). Эти данные позволяют нам говорить о том, что подавляющее большинство показателей эгоцентризма мальчиков укладываются в диапазон от 3,5 до 9,5 (среднее плюс/минус стандартное отклонение – М ± σ).
Если при тестировании группы девочек среднее значение М=5, а стандартное отклонение σ=1, то большинство испытуемых этой группы имеют эгоцентризм в диапазоне от 4 до 6 (5 ± 1).
Анализирую такие данные в дипломе по психологии можно указать, что средний уровень эгоцентризма у мальчиков больше, чем у девочек. При этом разброс показателей эгоцентризма у мальчиков также больше, чем у девочек, то есть, в группе мальчиков есть испытуемые с очень низкими и очень высокими показателями относительно среднего. У девочек показатели менее «разбросаны» относительно среднего.
Расчет среднего и стандартного отклонения
Формула расчета среднего очень проста и этот параметр можно рассчитать вручную.
Пример расчёта среднего
В таблице приведены показатели, полученные по тесту диагностики уровня одиночества у 64-х испытуемых.
Exceltip
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Что такое стандартное отклонение — использование функции СТАНДОТКЛОН для расчета стандартного отклонения в Excel

Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.
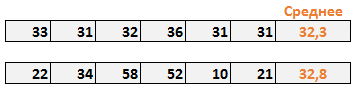
Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей выборке. Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.
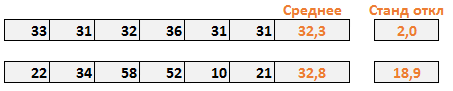
В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).
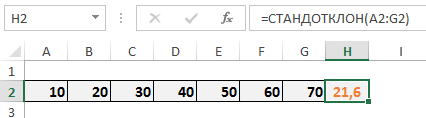
Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.
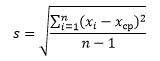
Функции расчета стандартного отклонения в Excel
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.
Вам также могут быть интересны следующие статьи
32 комментария
Ренат, добрый день.
Мне нравится статья, а главное способ подачи материала. Визуализация расчёта также порадовала новизной подхода, хотя и времени потребовала больше для понимания (классическое советское образование). Согласен, что про стандартное отклонение никто толком не знает, а зря…
Добрый день.
В формуле ошибка: под знаком корня необходимо суммировать квадраты отклонений
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:

То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:

s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А 2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:

На практике формула стандартного отклонения следующая:

Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).

Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:

По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Стандартное отклонение
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
Однако, глядя на цифры, можно заметить:
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
5. Поделить на размер выборки (т.е. на n):
6. Найти квадратный корень:
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
Ещё расчёт дисперсии можно сделать по этой формуле:
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:


