«Яндекс» научил генеративную модель выдавать тексты «в стиле Хабра»
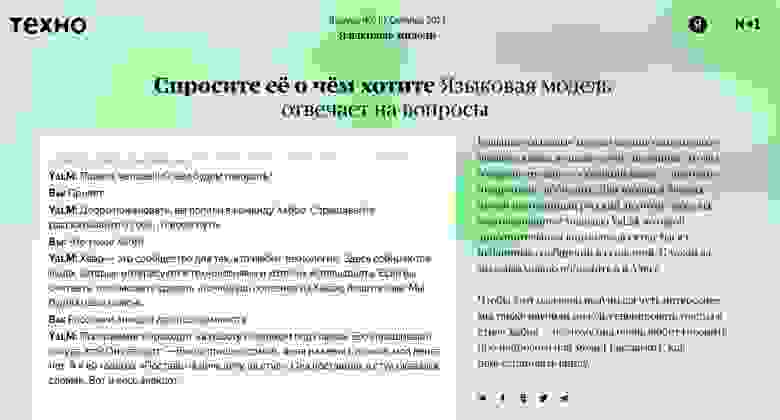
«Яндекс» в первом выпуске онлайн-журнала «Техно» открыл всем желающим доступ к общению с ИИ, генеративная модель которого обучена выдавать тексты «в стиле Хабра». Разработанная командой «Яндекса» «болтливая» языковая модель из семейства YaLM (Yet another Language Model), вдохновленная GPT-3 от компании Open AI, очень любит говорить про нейросети или может рассказать, как переустановить винду.
У данной нейросети есть несколько запрещенных стоп-слов (список не открыт, но можно его попытаться проанализировать), на которые она не отвечает и выдает фразу, что ей запретили говорить об этом и на подобные темы, но хочет поговорить о чем-то другом.
Также, если речь в беседе склоняется к чему-то непонятному или запрещенному, то нейросеть может сказать, что немножко устала и просит вернуться к разговору позже.
В середине октября «Яндекс» в сотрудничестве с изданием N+1 запустили онлайн-журнал «Техно». Каждый выпуск журнала будет посвящен одной из технологий «Яндекса». Первый номер о языковых моделях с интерактивными дополнениями и тестами уже доступен всем желающим.
В июне этого года «Яндекс» запустил нейросеть «Балабоба». «Балабоба» может закончить историю, придумать подпись или написать небольшой рассказ. Нейросеть не училась на писательских курсах, но сочиняет тексты за несколько секунд не хуже живых людей. Фактически «Балабоба» обучена на индексируемых «Яндексом» страницах, включая Википедию, новостные статьи и книги, а также записи пользователей в социальных сетях и на форумах. Аналогичные технологии генеративных нейросетей YaLM «Яндекс» использует для ответов в «Поиске» и в голосовом ассистенте «Алиса».

Можете написать в комментариях, что вам ответила нейросеть по-Хабровски.
Как Яндекс помогает преодолеть языковой барьер: нейросетевой перевод видео, картинок и текста

Недавно мы впервые показали прототип переводчика видео в Яндекс.Браузере. Прототип работал с ограниченным числом роликов, но даже в таком виде вызвал интерес у пользователей. Теперь мы переходим к следующему ключевому этапу: в новых версиях Браузера и приложения Яндекс перевод доступен для всех англоязычных роликов на YouTube, Vimeo, Facebook и других популярных платформах.
Сегодня я не только расскажу о том, как устроен новый переводчик видео и какие у нас планы, но и поделюсь предысторией. Потому что считаю, что контекст важен: мы шли к этому шагу более десяти лет. Но если история вам вдруг не интересна, то можете сразу переходить к разделу «Перевод видео», где я описал работу технологии (а точнее, целого комплекса наших технологий) по шагам.
Десятью годами ранее
В 2011 году в Яндексе решалась судьба собственного полноценного браузера. На тот момент браузеров на любой цвет и вкус уже хватало. Но почти все они создавались «где-то там»: без оглядки на рунет и потребности тех пользователей, для которых английский язык и латиница не были родными. Поэтому мы решили создать свой браузер, который бы в числе прочего более полно поддерживал русский язык и наши с вами «региональные» потребности. Уверен, эта фраза звучит непонятно, поэтому ниже вас ждут два моих любимых примера. Они не связаны с переводом, но показательны.
Русский язык отличается богатой морфологией. Падежи, род, бо́льшая свобода в построении предложений — всё это приводит к разнообразию форм одного и того же слова и способов написать одну и ту же фразу. При этом классический поиск по странице, который работает одинаково во всех известных мне браузерах, умеет искать только точные вхождения слов в тексте. Наш поиск работает гибче и учитывает морфологию русского языка. Наглядный пример:
Кстати, этой фиче был посвящён мой самый первый пост на Хабре в 2013-м. Как будто вчера это было.
Что будет, если ввести в адресную строку [ь]? Скорее всего, браузер предложит вам отправиться в поисковую систему и поискать там мягкий знак. Но чего на самом деле хотел человек, который набрал [ь]? Ответ: вероятно, он привык ходить на [m.habr.com] или [maps.yandex.ru], но забыл переключить раскладку на клавиатуре.
В отличие от англоязычной аудитории, нам с вами приходится жить в мире двух алфавитов и постоянно переключаться между ними. Это приводит к ошибкам. А ошибки приводят к выбору: или ввести адрес заново, или совершить лишний переход в поисковую систему. Мы — за экономию времени, поэтому учли подобные ошибки с раскладкой ещё в самой ранней версии 2012 года. В таких ситуациях Яндекс.Браузер исправляет раскладку «в уме» и предлагает перейти не в поиск, а сразу и в один клик — на нужный сайт.
Таких примеров много, но думаю, суть я передал. В любом случае все они меркнут на фоне главной проблемы, которой мы бросили вызов: проблемы языкового барьера.
Перевод текста
В интернете более миллиарда сайтов, но лишь около 9% — на русском языке. Интернет быстро растёт, но опять же — в основном за счёт иностранных сайтов. Информация, которая создаётся там, недоступна для большинства наших пользователей здесь.
Ещё тогда — в 2011-м — мы решили изменить это и помочь распространению знаний между пользователями. К счастью, в том же году появился Яндекс.Переводчик (тогда он ещё назывался Яндекс.Перевод). В его основе была технология статистического машинного перевода собственной разработки. Мы применили её и в Яндекс.Браузере. Да, мы не были первыми: Chrome уже умел подобное. Но в нашем случае переводчик работал с одной актуальной для рунета особенностью.
Большинство из нас с детства учит английский язык. Кто-то овладел им в совершенстве, но многие знают его достаточно фрагментарно, на уровне «читаю и пишу со словарём». Поэтому для нас особенно полезна возможность переводить не только страницы целиком, но и отдельные фразы и слова. Так мы пополняем словарный запас, продолжаем совершенствовать знания. Так оно и работает в Яндекс.Браузере с первого дня его существования.

Перевод картинок
Перевод текста — это хорошо. Но мы не должны забывать, что текст встречается ещё и на изображениях. Например, заметная часть сайтов израильских государственных организаций предпочитает именно такой способ размещения информации. Похожую картину можно увидеть на корейских, китайских, арабских сайтах. Аналогичная ситуация с техническими характеристиками товаров в иностранных интернет-магазинах.
Особенность этой задачки в том, что для её решения нужно объединить три технологии, которые отрабатывают последовательно. Сначала с помощью компьютерного зрения найти текст на картинке и распознать его в текстовый формат (OCR), затем с помощью машинного перевода перевести текст на русский язык, ну а вишенка на торте — рендеринг перевода поверх оригинальной картинки. Тут на каждом шаге можно закопаться в самостоятельную статью, поэтому я расскажу про самое неочевидное: про то, как мы боролись за экономию ресурсов.
Итак, можно взять исходную картинку, отправить в оригинальном виде из Браузера к нам на сервер, там проделать всю-всю работу, затем вернуть вариант с уже отрисованным переводом. Это самый простой для нас вариант. Но самый плохой для пользователя. Потому что картинки в интернете могут весить очень много. Их пересылка туда-обратно — это не только трафик, но и время, а значит, тормоза в продукте.
Чтобы не раздражать пользователей, мы пошли другим, сложным путём. На стороне Яндекс.Браузера уменьшаем картинки и переводим их в чёрно-белое представление. Кроме того, формат картинки меняем на WebP, который в среднем весит на 15–20% меньше, чем JPEG. В совокупности эти меры снизили вес картинок в несколько раз. При этом качество распознавания и перевода ощутимо не упало.
Этап объединения исходной картинки с переводом мы тоже перенесли на устройство. И вот тут возникла сложность. У Браузера есть исходная, цветная картинка и текст перевода. Если просто взять и наложить чёрный (белый?) текст на цветную картинку, то в большинстве случаев получится жуть. А мы не для того длину текста и переносы строк подгоняем под оригинал, чтобы испортить всю магию цветом шрифта.
Итак, нам нужно подогнать цвет перевода под цвет оригинала. Но Яндекс.Браузер не различает текст и фон на исходной картинке, а значит, не может выбрать цвет для перевода. Наш серверный OCR видит текст, но не видит цвета, которые были потеряны в результате конвертации в ч/б.
Придумали следующее. На стороне OCR выделяем ключевые точки на картинке для фона и текста. Отправляем их координаты Браузеру вместе с переводом. Браузер на своей стороне по этим координатам определяет цвета. И уже затем выбирает для перевода цвет, который накладывается на фон.
Получилось в целом неплохо:
Перевод картинок работает на десктопе и устройствах с Android. В ближайшем будущем добавим и iOS. Ну и конечно же, продолжим совершенствовать распознавание и перевод.
Перевод видео
У нас была давняя мечта: научиться переводить ещё и видео. Люди всё чаще смотрят образовательные и научно-популярные ролики, интервью, репортажи и многое другое. Бо́льшая часть подобных видео создаётся не на русском языке. Профессиональный перевод — редкость для свежего контента в интернете. В лучшем случае пользователи получают автоматически сгенерированные субтитры. Мы же решились замахнуться на большее: на автоматический перевод и озвучку любого видео прямо в браузере.
Как и в случае с картинками, для решения этой задачи одного только машинного перевода недостаточно. Качество перевода видео сильно зависит от качества распознавания и синтеза речи. К счастью, запуск Алисы и наших умных колонок здорово подстегнул развитие этих технологий в Яндексе. Настолько, что в сентябре прошлого года мы решились запустить проект. Казалось бы, остаётся только соединить все технологии в общий процесс. Какие тут могут быть сложности, не правда ли? Сейчас расскажу какие, описав процесс по шагам (а в конце рассказа вас ждёт простая наглядная схема).
Шаг 1. Распознавание речи и предобработка текста
Пользователь нажимает кнопку переводчика, и мы начинаем обрабатывать ролик.
У нас на входе есть какое-то видео с какими-то голосами. Это может быть образовательный ролик с одним ведущим. Это может быть интервью из двух человек. А может быть и вовсе многоголосая дискуссия. Если просто перевести поток речи в текст, то получится сырой набор слов. Без запятых, без точек, без логической группировки слов в предложения, а предложений — в абзацы. И если прогнать такой текст через переводчик, то результат будет в полной мере соответствовать принципу GIGO. Поэтому мы не только превращаем аудио в текст, но и запускаем специальную нейросеть, которая вычищает мусор, группирует слова в смысловые сегменты и расставляет знаки препинания.
Кстати, мы опираемся не только на голос, но и на субтитры. Решили так: если человек загрузил к видео субтитры — то распознавание не используем: ведь тексты, написанные людьми, обычно более качественные, чем тексты на выходе у ASR. Но если субтитры сгенерированы автоматически, то игнорируем их и применяем свою технологию.
При этом даже ручные субтитры нужно пропускать через ту самую нейросеть. Как минимум потому, что в них бывает много текста, который не нужен для синтеза голоса. Например, описание звуков (*аплодисменты*, *звук сирены* и т. д.) или указание имени спикера перед каждой фразой.
Кроме того, ручные субтитры могут быть нарезаны на строки не по границам фраз, а произвольно. Приходится пересобирать текст из разных строк. Покажу пример:

На скриншоте выше вы видите две строки субтитров. Раньше мы их так (построчно) и переводили. Но на самом деле это фрагменты двух предложений, начало и конец которых прячутся в соседних строках:
The output from my scanning electron microscope is than oscilloscope screen.
So I set that up and adjusted the contrast and everything.
И вот такие вещи надо уметь восстанавливать, иначе смысл перевода исказится до неузнаваемости.
Шаг 2. Биометрия
Итак, у нас на руках части неплохого текста и тайминги, которые нам ещё пригодятся. Что дальше? Перевод?
Нет: мы ещё больше усложнили себе задачку. Мы хотим, чтобы голоса у спикеров были разными: так проще воспринимать речь. Мы планируем адаптировать синтезированный голос к голосу спикера. Но на текущем этапе у нас более простое решение: мы определяем пол говорящего для каждой части текста, чтобы озвучивать их мужским или женским голосами.
Шаг 3. Машинный перевод
Теперь пора переводить. Тут в целом всё происходит достаточно стандартно, но с одной важной особенностью: мы передаём в модель переводчика ещё и информацию о спикерах, об их поле. Это нужно для того, чтобы в переводе разные спикеры говорили о себе или обращались к другим с корректным согласованием местоимений, глаголов и прилагательных.
Шаг 4. Синтез речи
Переходим к синтезу голоса. Сейчас у нас два голоса, дальше станет больше. Но самая большая сложность вовсе не в этом. Тексты на русском языке длиннее, чем на английском. Разница может составлять в среднем от 10 до 30%. Это значит, что при длительном воспроизведении мы рискуем словить существенный рассинхрон между тем, что говорит спикер на английском, и тем, что мы произносим на русском. Значит, нужно синхронизировать два потока речи. И нет, мы не стали фиксированно ускорять одну дорожку относительно другой.
Помните, чуть выше я уже говорил про тайминги, которые мы получили после анализа исходной речи? Благодаря им мы знаем, какие фразы в какой момент должны произноситься. Это позволяет нам синхронизировать речь более гибко. Работает это так. Синтез речи — многоступенчатый процесс, в котором можно выделить два самых больших этапа. На первом мы с помощью нейросетей представляем текст в виде промежуточной спектрограммы. На втором с помощью других нейросетей превращаем спектрограммы в звук. Мы используем тайминги на первом этапе, чтобы сгенерировать спектрограмму нужной длительности. При этом ускорение в первую очередь достигается за счёт сокращения бесполезных пауз между фразами и словами. И только если этого недостаточно, алгоритм ускоряет сами фразы.
Шаг 5. Уведомления
Ура, у нас готов перевод, его можно включить в Яндекс.Браузере. Расходимся? А вот и нет. Мы выстроили целый каскад из тяжёлых технологий, которые последовательно сменяют друг друга. Требуется время на работу огромных нейросетей-трансформеров, даже с учётом их распараллеливания на GPU. К примеру, когда мы делали первый подход к снаряду и собрали быстрый внутренний прототип, то видео длиной в час переводили целых полчаса. Нам удалось оптимизировать всё это дело и ускорить переводчик в несколько раз, но это по-прежнему минуты, а не мгновения. Над мгновенным переводом мы продолжаем работать, а сейчас придумали такую схему: мы не только говорим пользователю, что нужно немного подождать, но и присылаем пуш-уведомление о готовности. Такое решение удобно: можно запросить перевод, закрыть вкладку и уйти заниматься своими делами. Браузер переведёт и напомнит.
Вместо заключения
Вот наглядная схема всего процесса перевода видео:
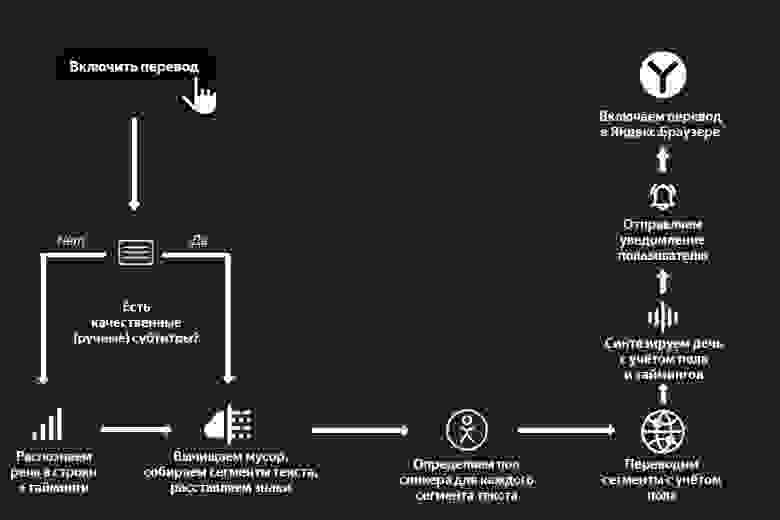
Чуть ниже вас ждёт образец готового перевода на примере фрагмента лекции Джимми Уэйлса в Яндексе (оригинал тут). Этот фрагмент хорошо демонстрирует не только потенциал нашей технологии, но и проблемы, над которыми мы будем работать дальше.
Сейчас перевод видео доступен для английского языка и популярных сервисов. Он работает в Яндекс.Браузере для десктопа и Android, а также в приложении Яндекс для Android и iOS.
Хочется верить, что наше решение поможет пользователям хотя бы частично преодолеть языковой барьер и открыть для себя новый полезный контент, для которого ещё нет профессионального перевода. Мы продолжим совершенствовать перевод видео. У нас ещё очень много работы, поэтому любые идеи приветствуются.
«Ублюдок, ты, маленькая задница»: как автоперевод видео в «Яндекс.Браузере» справляется с мемами и вирусными роликами Статьи редакции
Компания представила автоматическую озвучку англоязычных роликов с помощью нейросети. TJ протестировал её на вирусных видео из прошлого.
7 сентября «Яндекс» запустил автоматический перевод любых англоязычных видео на YouTube, Vimeo, TikTok, Twitter, Facebook и «ВКонтакте». С помощью сразу нескольких технологий сервис распознаёт речь, превращает его в структурированный текст, определяет пол говорящего и синтезирует соответствующую озвучку к ролику.
Прототип функции показали ещё в июле, но тогда она работала только в «Яндекс.Браузере», а для перевода было доступно ограниченное число роликов. Теперь перевод доступен также в приложениях «Яндекса» на iOS и Android и работает практически для всех роликов с указанных платформ, кроме лицензионного контента (хотя при переводе отдельных сцен из фильмов и сериалов проблем не возникает).
Хотя переводчик лучше всего справляется с лекциями и официальными выступлениями из-за чёткой структуры текста, сразу после анонса пользователи стали тестировать новую опцию, создавая озвучку для десятков роликов разных жанров.
Один из самых популярных примеров — сцена из фильма «Кровь и бетон», ставшая мемом из-за цитаты «Ублюдок, мать твою, а ну иди сюда. ». С новой озвучкой главный герой лишился доли экспрессии, а набор ругательств хотя и стал скромнее, почти не потерял в разнообразии.
Ублюдок, давай ты, маленькая задница, со мной, ты, маленькая задница, придурок, сосунок ты, давай, пойдём со мной.
Трансформеры в Поиске: как Яндекс применил тяжёлые нейросети для поиска по смыслу
Привет, Хабр. Меня зовут Саша Готманов, я руковожу группой нейросетевых технологий в поиске Яндекса. На YaC 2020 мы впервые рассказали о внедрении трансформера — новой нейросетевой архитектуры для ранжирования веб-страниц. Это наиболее значимое событие в нашем поиске за последние 10 лет.
Сегодня я расскажу читателям Хабра, в чём заключается иллюзия «поиска по смыслу», какой путь прошли алгоритмы и нейросети в ранжировании и какие основные сложности стоят перед теми, кто хочет применить для этой задачи трансформеры и даже заставить их работать в рантайме.
Задача поиска
Чтобы хорошо ранжировать результаты поиска, надо научиться оценивать семантическую (то есть смысловую) связь между запросом пользователя и документом (веб-страницей) из интернета. Иначе говоря, нужно построить алгоритм, который сможет предсказать, содержит ли данный документ ответ на запрос пользователя, есть ли в нём релевантная запросу информация.
С точки зрения пользователя это совершенно естественная задача. Смысл запроса ему очевиден; дальше достаточно лишь прочитать документ, понять его и либо найти в нём нужное содержание (тогда документ релевантен), либо нет (не релевантен).
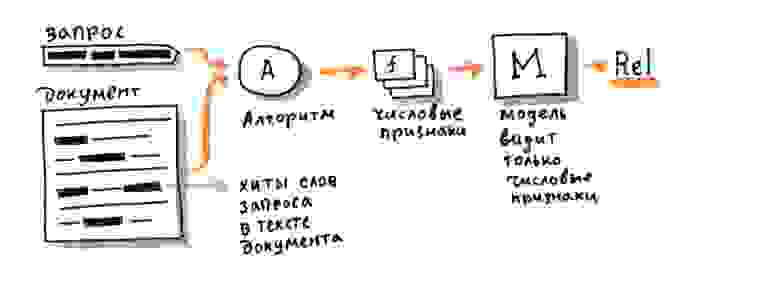
Алгоритм, в отличие от человека, оперирует словами из запроса и текста документа чисто математически, как строчками из символов. Например, алгоритмически легко посчитать число совпадающих слов в запросе и документе или длину самой длинной подстроки из запроса, которая присутствует и в документе. Можно также воспользоваться накопленной историей поиска и достать из заранее подготовленной таблицы сведения о том, что запрос уже задавался в поиск много раз, а документ получил по нему много кликов (или наоборот, получил их очень мало, или вообще ещё ни разу не был показан). Каждый такой расчёт приносит полезную информацию о наличии семантической связи, но сам по себе не опирается на какое-либо смысловое понимание текста. Например, если документ отвечает на запрос, то правдоподобно, что у запроса и документа должны быть общие слова и подстроки. Алгоритм может использовать этот статистический факт, чтобы лучше оценить вероятность смысловой связи, а на основе большого числа таких расчётов уже можно построить достаточно хорошую модель. При её использовании на практике у человека будет возникать ощущение, что алгоритм «понимает» смысл текста.
По такому принципу и работал поиск Яндекса до 2016 года. За годы разработки для повышения качества было придумано множество остроумных эвристических алгоритмов. Одних только способов посчитать общие слова запроса и документа было предложено и внедрено несколько десятков. Вот так, к примеру, выглядит один из сравнительно простых:
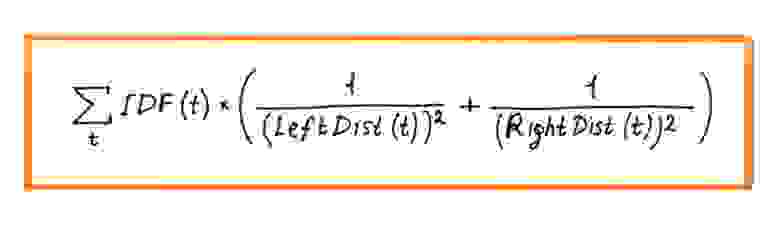
Здесь каждому «хиту» t (то есть вхождению слова из запроса в документ, от англ. hit, попадание) присваивается вес с учётом частотности слова в корпусе (IDF, Inverse Document Frequency) и расстояний до ближайших вхождений других слов запроса в документ слева и справа по тексту (LeftDist и RightDist). Затем полученные значения суммируются по всем найденным хитам. Каждая такая эвристика при внедрении позволяла получить небольшой, но статистически значимый прирост качества модели, то есть чуть лучше приблизить ту самую смысловую связь. Суммарный эффект от простых факторов постепенно накапливался, и внедрения за длительный период (полгода-год) уже заметно влияли на ранжирование.
Немного другой, но тоже хорошо работающий способ принести качество с помощью простого алгоритма — придумать, какие еще тексты можно использовать в качестве «запроса» и «документа» для уже существующих эвристик. Слова запроса можно расширить близкими им по смыслу (синонимичными) словами или фразами. Либо вместо исходного запроса пользователя взять другой, который сформулирован иначе, но выражает схожую информационную потребность. Например, для запроса [отдых на северном ледовитом океане] похожими могут быть:
[можно ли купаться в баренцевом море летом]
[путешествие по северному ледовитому океану]
[города и поселки на побережье северного ледовитого океана]
(Это реальные примеры расширений запроса, взятые из поиска Яндекса.)
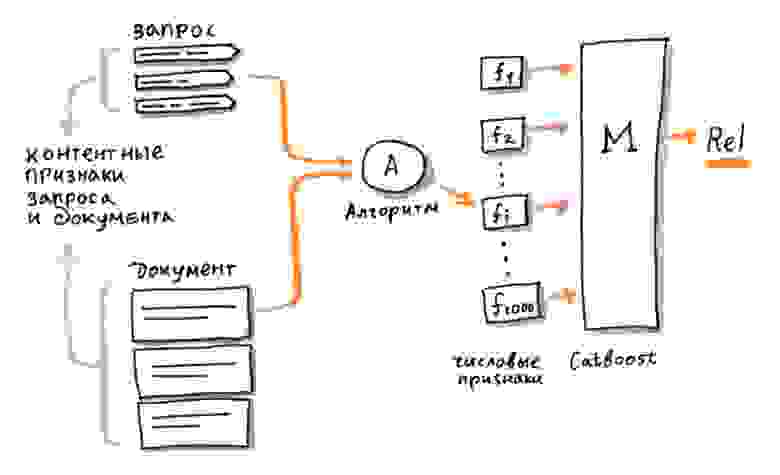
Как найти похожие слова и запросы — тема отдельного рассказа. Для этого в нашем поиске тоже есть разные алгоритмы, а решению задачи очень помогают логи запросов, которые нам задают пользователи. Сейчас важно отметить, что если похожий запрос найден, то его можно использовать во всех эвристических расчётах сразу; достаточно взять уже готовый алгоритм и заменить в нём один текст запроса на другой. Таким методом можно получить сразу много полезной информации для ранжирования. Что может быть чуть менее очевидно — аналогично запросу можно «расширять» и документ, собирая для него «альтернативные» тексты, которые в Яндексе называют словом стримы (от англ. stream). Например, стрим для документа может состоять из всех текстов входящих ссылок или из всех текстов запросов в поиск, по которым пользователи часто выбирают этот документ на выдаче. Точно так же стрим можно использовать в любом готовом эвристическом алгоритме, заменив на него исходный текст документа.
Говоря более современным языком, расширения и стримы — это примеры дополнительных контентных признаков, которые поиск Яндекса умеет ассоциировать с запросом и документом. Они ничем не отличаются от обычных числовых или категориальных признаков, кроме того, что их содержимое — это неструктурированный текст. Интересно, что эвристики, для которых эти признаки изначально разрабатывались, уже утратили большую часть своей актуальности и полезности, но сами расширения и стримы продолжают приносить пользу, только теперь уже в качестве входов новых нейронных сетей.
В результате многих лет работы над качеством поиска у нас накопились тысячи самых разных факторов. При решении задачи ранжирования все они подаются на вход одной итоговой модели. Для её обучения мы используем нашу открытую реализацию алгоритма GBDT (Gradient Boosting Decision Trees) — CatBoost.
Нейросети в ранжировании
Современные поисковые системы развиваются и улучшают своё качество за счёт всё более точных приближений семантической связи запроса и документа, так что иллюзия понимания становится полнее, охватывает новые классы запросов и пользовательских задач. Основным инструментом для этого в последние годы стали нейронные сети всё более возрастающей сложности. Впрочем, начало (как нам теперь кажется) было довольно простым.
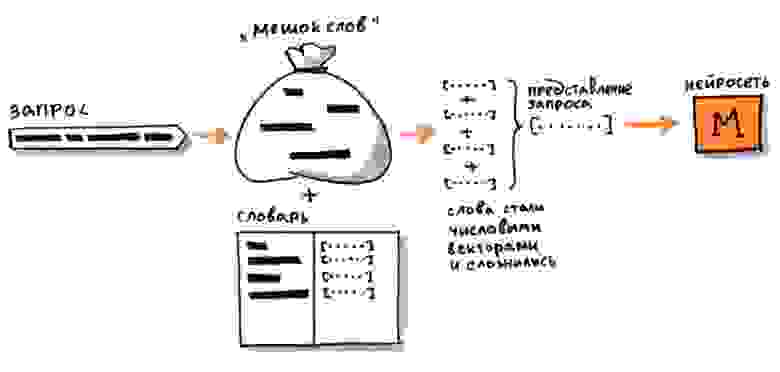
Первые нейронные сети в поиске обладали простой feed-forward-архитектурой. На вход сети подаётся исходный текст в виде «мешка слов» (bag of words). Каждое слово превращается в вектор, вектора затем суммируются в один, который и используется как представление всего текста. Взаимный порядок слов при этом теряется или учитывается лишь частично с помощью специальных технических трюков. Кроме того, размер «словаря» у такой сети ограничен; неизвестное слово в лучшем случае удаётся разбить на частотные сочетания букв (например, на триграммы) в надежде сохранить хотя бы часть его смысла. Вектор мешка слов затем пропускается через несколько плотных слоёв нейронов, на выходе которых образуется семантический вектор (иначе эмбеддинг, от англ. embedding, вложение; имеется в виду, что исходный объект-текст вкладывается в n-мерное пространство семантических векторов).
Замечательная особенность такого вектора в том, что он позволяет приближать сложные «смысловые» свойства текста с помощью сравнительно простых математических операций. Например, чтобы оценить смысловую связь запроса и документа, можно каждый из них сначала превратить в отдельный вектор-эмбеддинг, а затем вектора скалярно перемножить друг на друга (или посчитать косинусное расстояние).
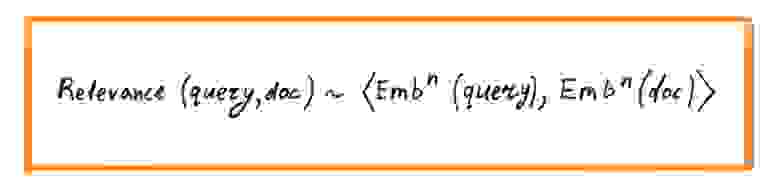
В этом свойстве семантических векторов нет ничего удивительного, ведь нейронная сеть обучается решать именно такую задачу, то есть приближать смысловую связь между запросом и документом на миллиардах обучающих примеров. В качестве таргета (то есть целевого, истинного значения релевантности) при этом используются предпочтения наших пользователей, которые можно определить по логам поиска. Точнее, можно предположить, что определённый шаблон поведения пользователя хорошо коррелирует с наличием (или, что не менее важно, с отсутствием) смысловой связи между запросом и показанным по нему документом, и собрать на его основе вариант таргета для обучения. Задача сложнее, чем может показаться на первый взгляд, и допускает различные решения. Если в качестве положительного примера обычно подходит документ с «кликом» по запросу, то найти хороший отрицательный пример гораздо труднее. Например, оказывается, что почти бесполезно брать в качестве отрицательных документы, для которых был показ, но не было «клика» по запросу. Здесь снова открывается простор для эвристических алгоритмов, а их правильное использование позволяет на порядок улучшить качество получающейся нейронной сети в задаче ранжирования. Алгоритм, который лучше всего показал себя на практике, называется в Яндексе «алгоритмом переформулировок» и существенно опирается на то, что пользователям свойственно при решении поисковой задачи задавать несколько запросов подряд, постепенно уточняя формулировку, то есть «переформулировать» исходный запрос до тех пор, пока не будет найден нужный документ.
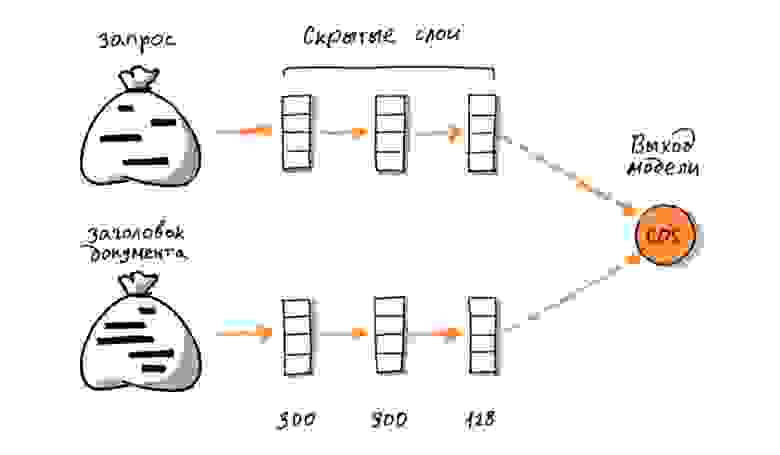
Пример архитектуры сети в подходе с семантическими эмбеддингами. Более подробное описание этого подхода — тут.
Важное ограничивающее свойство такой сети: весь входной текст с самого начала представляется одним вектором ограниченного размера, который должен полностью описывать его «смысл». Однако реальный текст (в основном это касается документа) обладает сложной структурой — его размер может сильно меняться, а смысловое содержание может быть очень разнородным; каждое слово и предложение обладают своим особым контекстом и добавляют свою часть содержания, при этом разные части текста документа могут быть в разной степени связаны с запросом пользователя. Поэтому простая нейронная сеть может дать лишь очень грубое приближение реальной семантики, которое в основном работает для коротких текстов.
Тем не менее, использование плотных feed-forward-сетей в своё время позволило существенно улучшить качество поиска Яндекса, что легло в основу двух крупных релизов: «Палех» и «Королёв». В значительной степени этого удалось добиться за счёт длительных экспериментов с обучающими выборками и подбором правильных контентных признаков на входе моделей. То есть ключевыми вопросами для нас были: «На какой (кликовый) таргет учить?» и «Какие данные и в каком виде подавать на вход?»
Интересно, что хотя нейронная сеть обучается предсказывать связь между запросом и документом, её затем можно легко адаптировать и для решения других смысловых задач. Например, уже готовую сеть можно на сравнительно небольшом числе примеров дообучить для различных вариантов запросной или документной классификации, таких как выделение потока порнозапросов, товарных и коммерческих, навигационных (то есть требующих конкретного сайта в ответе) и так далее. Что ещё более важно для ранжирования, такую же сеть можно дообучить на экспертных оценках. Экспертные оценки в ранжировании — это прямые оценки смысловой связи запроса и документа, которые ставятся людьми на основе понимания текста. В сложных случаях правильная оценка требует специальных знаний в узкой области, например в медицине, юриспруденции, программировании, строительстве. Это самый качественный и самый дорогой из доступных нам таргетов, поэтому важно уметь его выучивать максимально эффективно.
Нейронная сеть, сначала обученная на миллиардах «переформулировок», а затем дообученная на сильно меньшем количестве экспертных оценок, заметно улучшает качество ранжирования. Это характерный пример применения подхода transfer learning: модель сначала обучается решать более простую или более общую задачу на большой выборке (этот этап также называют предварительным обучением или предобучением, англ. pre-tain), а затем быстро адаптируется под конкретную задачу уже на сильно меньшем числе примеров (этот этап называют дообучением или настройкой, англ. fine-tune). В случае простых feed-forward-сетей transfer learning уже приносит пользу, но наибольшего эффекта этот метод достигает с появлением архитектур следующего поколения.
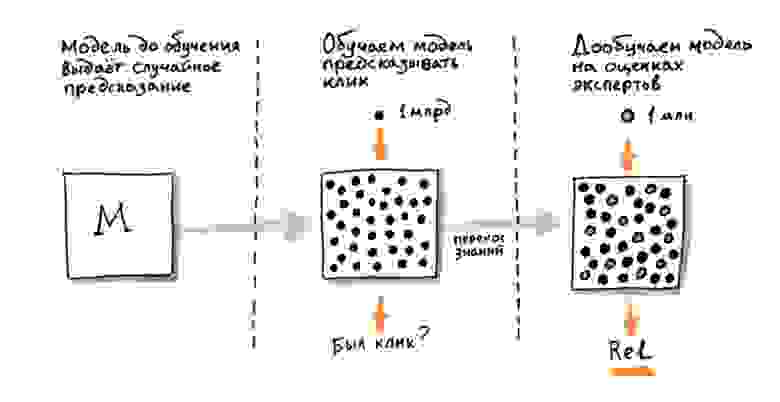
Нейросети-трансформеры
Долгое время самой активно развивающейся областью применения для сложных алгоритмов анализа текста была задача машинного перевода. Результат работы переводчика — это полностью сгенерированный текст, и даже небольшие смысловые ошибки сразу заметны пользователю. Поэтому для решения задач перевода всегда использовались самые сложные модели, которые могли учесть порядок слов в тексте и их взаимное влияние друг на друга. Сначала это были рекуррентные нейронные сети (Recurrent Neural Networks, RNN), а затем трансформеры. Далее речь пойдёт только о трансформерах, которые по сути являются более технологически совершенным развитием идеи рекуррентных сетей.
В сетях с архитектурой трансформеров каждый элемент текста обрабатывается по отдельности и представляется отдельным вектором, сохраняя при этом своё положение. Элементом может быть отдельное слово, знак пунктуации или частотная последовательность символов, например BPE-токен. Сеть также включает механизм «внимания» (англ. attention), который позволяет ей при вычислениях «концентрироваться» на разных фрагментах входного текста.
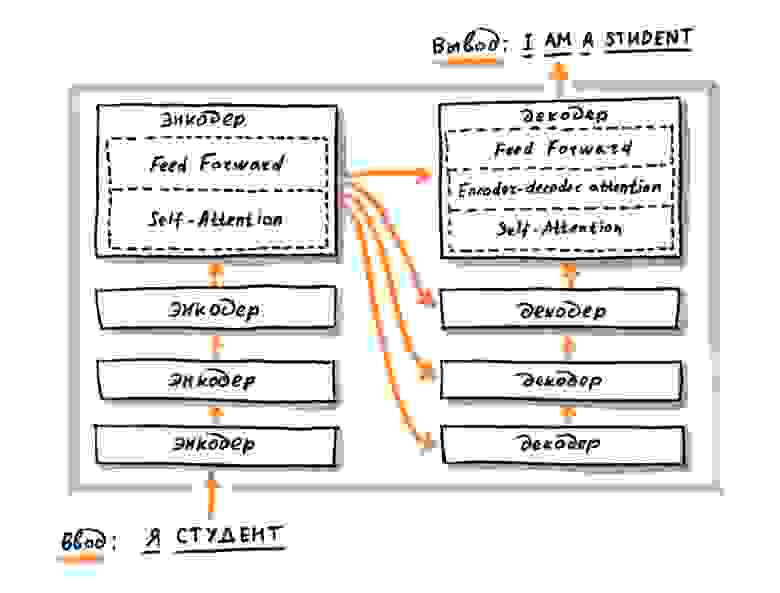
Применительно к задаче ранжирования, по запросу [купить кофеварку] такая нейронная сеть может выделить часть документа (e.g. страницы интернет-магазина), в которой речь идёт именно о нужном пользователю товаре. Остальные части тоже могут быть учтены, но их влияние на результат будет меньше. Трансформеры могут хорошо выучивать сложные зависимости между словами и активно используются для генерации естественных текстов в таких задачах, как перевод и ответы на вопросы (англ. question answering). Поэтому в Яндексе они применяются уже достаточно давно. В первую очередь, конечно, в Яндекс.Переводчике.
В ранжировании трансформеры позволяют добиться нового уровня качества при моделировании семантической связи запроса и документа, а также дают возможность извлекать полезную для поиска информацию из более длинных текстов. Но одних только ванильных трансформеров для этой задачи мало.
Transformers + transfer learning
Глубокие нейронные сети достаточно требовательны к объёму примеров для обучения. Если данных мало, то никакого выигрыша от применения тяжёлой архитектуры не получится. При этом практических задач всегда много, и они несколько отличаются друг от друга. Собрать миллиарды примеров для каждый задачи просто невозможно: не хватит ни времени, ни бюджета. На помощь снова приходит подход transfer learning. Как мы уже разобрались на примере feed-forward-сетей, суть в том, чтобы переиспользовать информацию, накопленную в рамках одной задачи, для других задач. В Яндексе этот подход применяется повсеместно, особенно он хорош в компьютерном зрении, где обученная на поиске изображений базовая модель легко дообучается почти на любые задачи. В трансформерах transfer learning тоже ожидаемо заработал.
В 2018-м команда OpenAI показала, что если обучить трансформер на сыром корпусе текстов большого размера в режиме языковой модели, а затем дообучать модель на малых данных для конкретных задач, то результат оказывается существенно лучше, чем раньше. Так родился проект GPT (Generative Pre-trained Transformer). Похожая идея чуть позже легла в основу проекта BERT (Bidirectional Encoder Representations from Transformers) от Google.
Такой же метод мы решили применить и в качестве поиска Яндекса. Но для этого нам потребовалось преодолеть несколько технологических трудностей.
Трансформеры в поиске Яндекса
Проект BERT замечателен тем, что каждый может взять в открытом доступе уже готовую предобученную модель и применить её к своей задаче. Во многих случаях это даёт отличный результат. Но, к сожалению, поиск Яндекса — не такой случай. Простое дообучение готовой модели приносит лишь небольшое улучшение качества, совершенно непропорциональное затратам ресурсов, которые необходимы для применения такой модели в рантайме. Чтобы раскрыть реальные возможности трансформера для поиска, нужно было обучать свою модель с нуля.
Для иллюстрации приведу несколько результатов из наших экспериментов. Давайте возьмём открытую модель BERT-Base Multilingual и обучим на наши экспертные оценки. Можно измерить полезность такого трансформера как дополнительного фактора в задаче ранжирования; получим статистически значимое уменьшение ошибки предсказания релевантности на 3-4%. Это хороший фактор для ранжирования, который мы бы немедленно внедрили, если бы он не требовал применения 12-слойного трансформера в рантайме. Теперь возьмём вариант модели BERT-Base, который мы обучили с нуля, и получим уменьшение ошибки предсказания почти на 10%, то есть более чем двукратный рост качества по сравнению с ванильной версией, и это далеко не предел. Это не значит, что модель Multilingual от Google — низкого качества. С помощью открытых моделей BERT уже было получено много интересных результатов в разных задачах NLP (Natural Language Processing, то есть в задачах обработки текстов на естественном языке). Но это значит, что она плохо подходит для ранжирования веб-страниц на русском языке.
Первая трудность, которая возникает на пути к обучению своего трансформера, — это вычислительная сложность задачи. Новые модели хорошо масштабируются по качеству, но при этом в миллионы раз сложнее, чем те, которые применялись в поиске Яндекса раньше. Если раньше нейронную сеть удавалось обучить за один час, то трансформер на таком же графическом ускорителе Tesla v100 будет учиться 10 лет. То есть без одновременного использования хотя бы 100 ускорителей (с возможностью быстрой передачи данных между ними) задача не решается в принципе. Необходим запуск специализированного вычислительного кластера и распределённое обучение на нём.
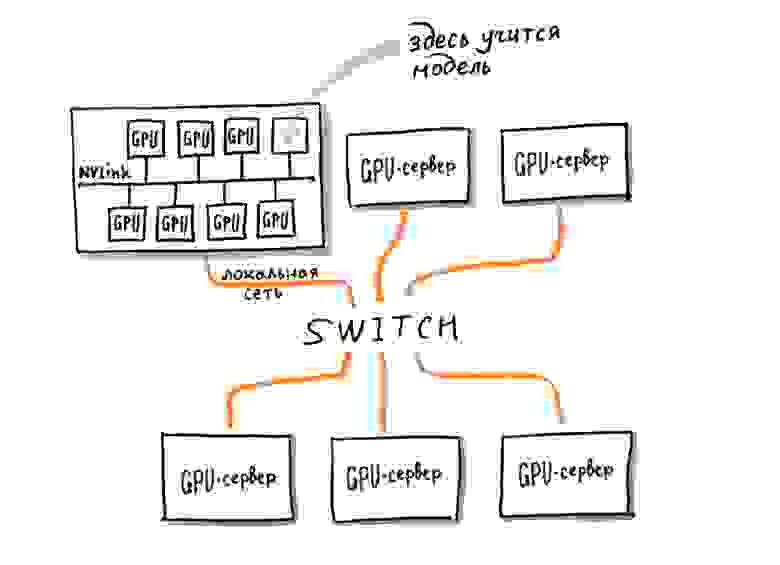
Нам потребовалось немного времени, пара сотен GPU-карт, место в одном из дата-центров Яндекса и классные инженеры. К счастью, всё это у нас было. Мы собрали несколько версий кластера и успешно запустили на нём обучение. Теперь модель одновременно обучается примерно на 100 ускорителях, которые физически расположены в разных серверах и общаются друг с другом через сеть. И даже с такими ресурсами на обучение уходит около месяца.
Несколько слов про само обучение. Нам важно, чтобы получившаяся модель решала с оптимальным качеством именно задачу ранжирования. Для этого мы разработали свой стек обучения. Как и BERT, модель сначала учится свойствам языка, решая задачу MLM (Masked Language Model), но делает это сразу на текстах, характерных для задачи ранжирования. Уже на этом этапе вход модели состоит из запроса и документа, и мы с самого начала обучаем модель предсказывать ещё и вероятность клика на документ по запросу. Удивительно, но тот же самый таргет «переформулировок», который был разработан ещё для feed-forward-сетей, отлично показывает себя и здесь. Обучение на клик существенно увеличивает качество при последующем решении семантических задач ранжирования.
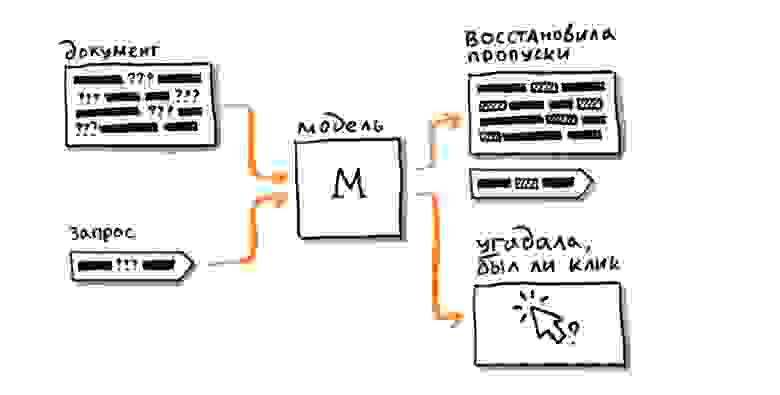
В дообучении мы используем не одну задачу, а последовательность задач возрастающей сложности. Сначала модель учится на более простых и дешёвых толокерских оценках релевантности, которыми мы располагаем в большом количестве. Затем на более сложных и дорогих оценках асессоров. И наконец, обучается на итоговую метрику, которая объединяет в себе сразу несколько аспектов и по которой мы оцениваем качество ранжирования. Такой метод последовательного дообучения позволяет добиться наилучшего результата. По сути весь процесс обучения выстраивается от больших выборок к малым и от простых задач к более сложным и «семантическим».
На вход модели мы подаём всё те же контентные признаки, о которых шла речь в самом начале. Здесь есть текст запроса, его расширения и фрагменты содержимого документа. Документ целиком всё ещё слишком большой, чтобы модель могла справиться с ним полностью сама, без предварительной обработки. Стримы тоже содержат полезную информацию, но с ними нам ещё надо поработать, чтобы понять, как её эффективно донести до поиска. Сложнее всего оказалось выделить хорошие фрагменты текста документа. Это вполне ожидаемо: чтобы выделить наиболее важную часть веб-страницы, уже нужно многое понимать про её смысловое содержание. Сейчас нам на помощь опять приходят простые эвристики и алгоритмы автоматической сегментации, то есть разметки страницы на структурные зоны (основное содержание, заголовки и так далее). Стоимость ошибки достаточно велика, иногда для правильного решения задачи необходимо, чтобы модель «увидела» одно конкретное предложение в длинном тексте статьи, и здесь ещё остается потенциал для улучшений.
Итак, мы научились обучать модели в офлайне, но вот работать им уже нужно в онлайне, то есть в реальном времени в ответ на тысячи пользовательских запросов в секунду. Тут заключается вторая принципиальная трудность. Применение трансформера — это тяжелая для рантайма задача; модели такой сложности можно применять только на GPU-картах, иначе время их работы окажется чрезмерным и легко может превысить время работы всего поиска. Потребовалось разработать с нуля и развернуть несколько сервисов для быстрого применения («инференса», англ. inference) трансформеров на GPU. Это новый тип инфраструктуры, который до этого не использовался в поиске.
Непосредственно для применения мы доработали внутреннюю библиотеку для инференса трансформеров, которая разработана нашими коллегами из Яндекс.Переводчика и, по нашим замерам, как минимум не уступает другим доступным аналогам. Ну и конечно, всё считается в FP16 (16-битное представление чисел с плавающей точкой).
Однако, даже с учетом использования GPU и оптимизированного кода для инференса, модель с максимальным уровнем качества слишком большая для внедрения в рантайм поиска. Для решения этой проблемы есть классический приём — knowledge distillation (или dark knowledge). В Яндексе мы используем менее пафосный термин «пародирование». Это обучение более простой модели, которая «пародирует» поведение более сложной, обучаясь на её предсказания в офлайне.
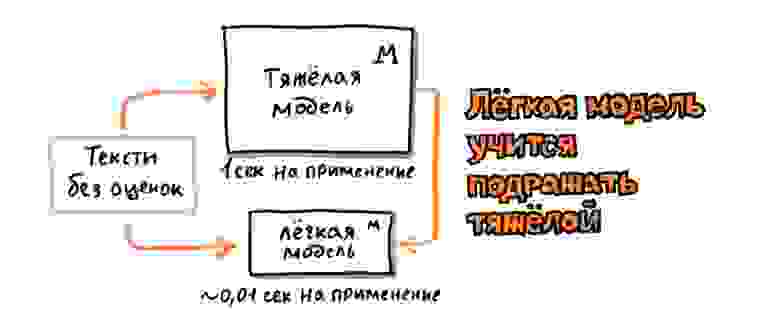
В результате пародирования сложность модели удаётся уменьшить в разы, а потери качества остаются в пределах
Это не единственный способ оптимизации. Мы также научились делать многозадачные модели, когда одна модель «подражает» сразу нескольким сложным моделям, обученным на разные задачи. При этом суммарная полезность модели для ранжирования существенно возрастает, а её сложность почти не увеличивается.
Если же хочется добиться максимального качества, то возможностей одной дистилляции недостаточно. Приходится поделить модель на несколько частей, каждая из которых применяется независимо. Часть модели применяется только к запросу; часть — только к документу; а то, что получилось, затем обрабатывается финальной связывающей моделью. Такой метод построения «раздельной» или split-модели распределяет вычислительную нагрузку между разными компонентами системы, что позволяет сделать модель более сложной, увеличить размер её входа и заметно повысить качество.
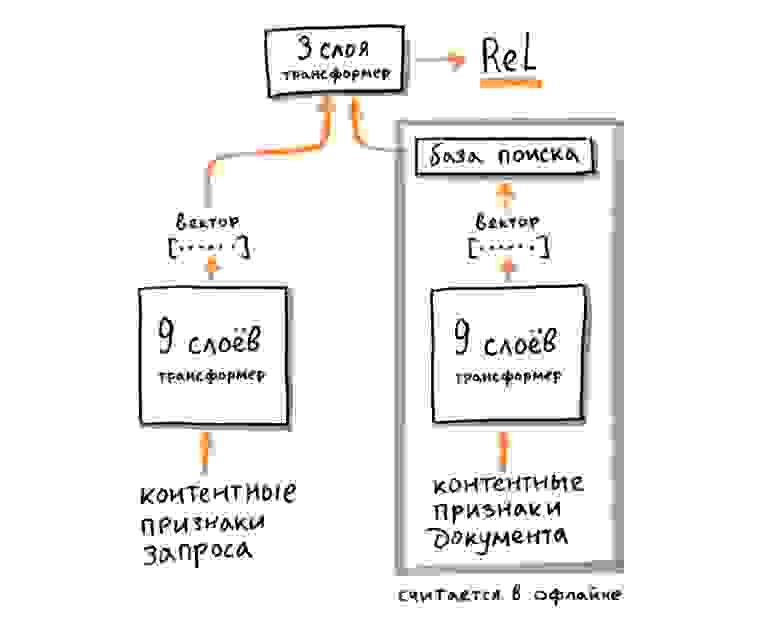
Внедрение split-модели опять приводит нас к новым и интересным инженерным задачам, но рассказать обо всём в одном посте, увы, невозможно. Хотя архитектура нейросетей-трансформеров известна уже достаточно давно, а их использование для задач NLP приобрело огромную популярность после появления BERT в 2018 году, внедрение трансформера в современную поисковую систему невозможно без инженерной изобретательности и большого числа оригинальных технологических улучшений в обучении и рантайме. Поэтому мы назвали нашу технологию YATI — Yet Another Transformer (with Improvements), что, как нам кажется, хорошо отражает её суть. Это действительно «ещё один трансформер», архитектурно похожий на другие модели (а их в последние годы появилось великое множество), но уникальный тем, что благодаря совокупности улучшений он способен работать и приносить пользу в поиске — самом сложном сервисе Яндекса.
Итоги
Что в итоге? У нас появилась своя инфраструктура обучения и дистилляции тяжёлых моделей, адаптированная под наш стек задач ранжирования. С её помощью мы сначала обучили большие модели-трансформеры высокого качества, а затем дистиллировали их в многозадачную split-модель, которая внедрена в рантайм на GPU в виде нескольких частей, независимо применяемых к запросу и документу.
Это внедрение принесло нам рекордные улучшения в ранжировании за последние 10 лет (со времён внедрения Матрикснета). Просто для сравнения: Палех и Королёв вместе повлияли на поиск меньше, чем новая модель на трансформерах. Более того, в поиске рассчитываются тысячи факторов, но если выключить их все и оставить только новую модель, то качество ранжирования по основной офлайн-метрике упадёт лишь на 4-5%!
В таблице ниже сравнивается качество нескольких нейросетевых алгоритмов в задаче ранжирования. “% NDCG” — это нормированное значение обычной метрики качества DCG по отношению к идеальному ранжированию на нашем датасете. 100% означает, что модель располагает документы в порядке убывания их истинных офлайн-оценок. Худший результат ожидаемо даёт подход предыдущего поколения, то есть просто обучение feed-forward-сети на кликовый таргет. Дообучение готовых моделей BERT существенно проигрывает по качеству специализированной версии, которая показывает рекордный результат в 95,4% — сравнимо с качеством дистилляции YATI в feed-forward-сеть. Все модели, кроме первой, дообучались на одном и том же множестве экспертных оценок.
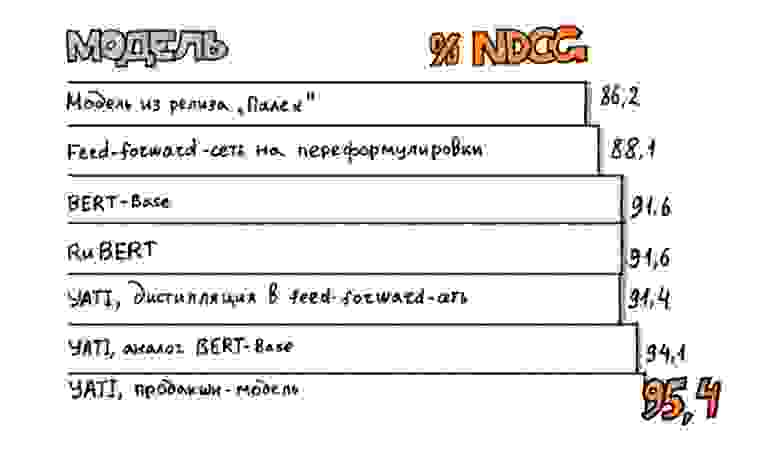
Приводимые числа показывают: несмотря на универсальность нейросетей последнего поколения, их адаптация к конкретным задачам на практике даёт существенный прирост эффективности. Это особенно важно для промышленных применений под высокой нагрузкой. Тем не менее очевидная ценность универсальных моделей в том, что они позволяют добиться достаточно хороших результатов на широком круге NLP-задач при минимальном вложении времени и ресурсов.
В начале поста я рассказал про ощущение поиска по смыслу. Применение тяжёлых (как мы сейчас о них думаем) нейросетевых моделей, которые точнее приближают структуру естественного языка и лучше учитывают семантические связи между словами в тексте, поможет нашим пользователям встречаться с этим эффектом ещё чаще, чем раньше. И может быть, однажды нам уже будет непросто отличить иллюзию от реальности. Но до этого, я уверен, в качестве поиска ещё предстоит сделать много нового и интересного.


