Неверно что обработка данных направлена на
7.1. Общее представление об обработке данных
Обработка данных психологических исследований – отдельный раздел экспериментальной психологии, тесно связанный с математической статистикой и логикой. Обработка данных направлена на решение следующих задач:
• упорядочивание полученного материала;
• обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях;
• выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей;
• обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса;
• выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов.
Различают количественную и качественную обработку данных. Количественная обработка – это работа с измеренными характеристиками изучаемого объекта, его «объективированными» свойствами. Качественная обработка представляет собой способ проникновения в сущность объекта путем выявления его неизмеряемых свойств.
Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала: корреляционный анализ, факторный анализ и т. д. Реализуется количественная обработка с помощью математико-статистических методов.
В качественной обработке преобладают синтетические способы познания. Обобщение проводится на следующем этапе исследовательского процесса – интерпретационном. При качественной обработке данных главное заключается в соответствующем представлении сведений об изучаемом явлении, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики.
Противопоставление друг другу качественной и количественной обработки довольно условно. Количественный анализ без последующей качественной обработки бессмыслен, так как сам по себе не приводит к приращению знаний, а качественное изучение объекта без базовых количественных данных в научном познании невозможно. Без количественных данных научное познание – чисто умозрительная процедура.
Единство количественной и качественной обработки наглядно представлено во многих методах обработки данных: факторном и таксономическом анализе, шкалировании, классификации и др. Наиболее распространены такие приемы количественной обработки, как классификация, типологизация, систематизация, периодизация, казуистика.
Качественная обработка естественным образом выливается в описание и объяснение изучаемых явлений, что составляет уже следующий уровень их изучения, осуществляемый на стадии интерпретации результатов. Количественная же обработка полностью относится к этапу обработки данных.
7.2. Первичная статистическая обработка данных
Все методы количественной обработки принято подразделять на первичные и вторичные.
Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале.
Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода.
Выборочное среднее (М) – это результат деления суммы всех значений (X) на их количество (N).
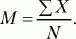
Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение – при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду.
Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
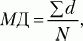
где d = |Х – М |, М – среднее выборки, X – конкретное значение, N – число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:

где d = |Х – М|, М – среднее выборки, X – конкретное значение, N – число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:

где d = |Х– М|, М – среднее выборки, X– конкретное значение, N – число значений.
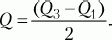
При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
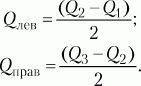
7.3. Вторичная статистическая обработка данных
К вторичным относят такие методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. Вторичные методы можно подразделить на способы оценки значимости различий и способы установления статистических взаимосвязей.
Способы оценки значимости различий. Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, используют t-критерий Стьюдента. Его формула выглядит следующим образом:
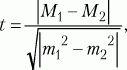
где М1, М2 – выборочные средние значения сравниваемых выборок, m1, m2 – интегрированные показатели отклонений частных значений из двух сравниваемых выборок, вычисляются по следующим формулам:
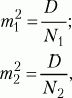
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя t по таблице критических значений (см. Статистическое приложение 1), заданного числа степеней свободы (N1 + N2 – 2) и избранной вероятности допустимой ошибки (0,05, 0,01, 0,02, 001 и т.д.) находят табличное значение t. Если вычисленное значение t больше или равно табличному, делают вывод о том, что сравниваемые средние значения двух выборок статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной.
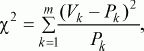
где Pk – частоты распределения в первом замере, Vk – частоты распределения во втором замере, m – общее число групп, на которые разделились результаты замеров.
Для сравнения дисперсий двух выборок используется F-критерий Фишера. Его формула выглядит следующим образом:
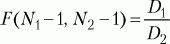
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя F по таблице критических значений (см. Статистическое приложение 3), заданного числа степеней свободы (N1 – 1, N2 – 1) находится Fкр. Если вычисленное значение F больше или равно табличному, делают вывод о том, что различие дисперсий в двух выборках статистически достоверно.
Способы установления статистических взаимосвязей. Предыдущие показатели характеризуют совокупность данных по какому-либо одному признаку. Этот изменяющийся признак называют переменной величиной или просто переменной. Меры связи выявляют соотношения между двумя переменными или между двумя выборками. Эти связи, или корреляции, определяют через вычисление коэффициентов корреляции. Однако наличие корреляции не означает, что между переменными существует причинная (или функциональная) связь. Функциональная зависимость – это частный случай корреляции. Даже если связь причинна, корреляционные показатели не могут указать, какая из двух переменных является причиной, а какая – следствием. Кроме того, любая обнаруженная в психологических исследованиях связь, как правило, существует благодаря и другим переменным, а не только двум рассматриваемым. К тому же взаимосвязи психологических признаков столь сложны, что их обусловленность одной причиной вряд ли состоятельна, они детерминированы множеством причин.
По тесноте связи можно выделить следующие виды корреляции: полная, высокая, выраженная, частичная; отсутствие корреляции. Эти виды корреляций определяют в зависимости от значения коэффициента корреляции.
При полной корреляции его абсолютные значения равны или очень близки к 1. В этом случае устанавливается обязательная взаимозависимость между переменными. Здесь вероятна функциональная зависимость.
Высокая корреляция устанавливается при абсолютном значении коэффициента 0,8–0,9. Выраженная корреляция считается при абсолютном значении коэффициента 0,6–0,7. Частичная корреляция существует при абсолютном значении коэффициента 0,4–0,5.
Абсолютные значения коэффициента корреляции менее 0,4 свидетельствуют об очень слабой корреляционной связи и, как правило, в расчет не принимаются. Отсутствие корреляции констатируется при значении коэффициента 0.
Кроме того, в психологии при оценке тесноты связи используют так называемую «частную» классификацию корреляционных связей. Она ориентирована не на абсолютную величину коэффициентов корреляции, а на уровень значимости этой величины при определенном объеме выборки. Эта классификация применяется при статистической оценке гипотез. При данном подходе предполагается, что чем больше выборка, тем меньшее значение коэффициента корреляции может быть принято для признания достоверности связей, а для малых выборок даже абсолютно большое значение коэффициента может оказаться недостоверным.[86]
По направленности выделяют следующие виды корреляционных связей: положительная (прямая) и отрицательная (обратная). Положительная (прямая) корреляционная связь регистрируется при коэффициенте со знаком «плюс»: при увеличении значения одной переменной наблюдается увеличение другой. Отрицательная (обратная) корреляция имеет место при значении коэффициента со знаком «минус». Это означает обратную зависимость: увеличение значения одной переменной влечет за собой уменьшение другой.
По форме различают следующие виды корреляционных связей: прямолинейную и криволинейную. При прямолинейной связи равномерным изменениям одной переменной соответствуют равномерные изменения другой. Если говорить не только о корреляциях, но и о функциональных зависимостях, то такие формы зависимости называют пропорциональными. В психологии строго прямолинейные связи – явление редкое. При криволинейной связи равномерное изменение одного признака сочетается с неравномерным изменением другого. Эта ситуация для психологии типична.
Коэффициент линейной корреляции по К. Пирсону (r) вычисляется c помощью следующей формулы:
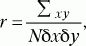
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 4).
При сравнении порядковых данных применяется коэффициент ранговой корреляции по Ч. Спирмену (R):
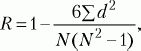
где d – разность рангов (порядковых мест) двух величин, N – число сравниваемых пар величин двух переменных (X и Y).
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 5).
Внедрение в научные исследования автоматизированных средств обработки данных позволяет быстро и точно определять любые количественные характеристики любых массивов данных. Разработаны различные программы для компьютеров, по которым можно проводить соответствующий статистический анализ практически любых выборок. Из массы статистических приемов в психологии наибольшее распространение получили следующие: 1) комплексное вычисление статистик; 2) корреляционный анализ; 3) дисперсионный анализ; 4) регрессионный анализ; 5) факторный анализ; 6) таксономический (кластерный) анализ; 7) шкалирование. Познакомиться с характеристиками этих методов можно в специальной литературе («Статистические методы в педагогике и психологии» Стенли Дж., Гласа Дж. (М., 1976), «Математическая психология» Г.В. Суходольского (СПб., 1997), «Математические методы психологического исследования» А.Д. Наследова (СПб., 2005) и др.).
Bookitut.ru
Тема 7. Обработка данных психологических исследований
7.1. Общее представление об обработке данных
Обработка данных психологических исследований – отдельный раздел экспериментальной психологии, тесно связанный с математической статистикой и логикой. Обработка данных направлена на решение следующих задач:
• упорядочивание полученного материала;
• обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях;
• выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей;
• обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса;
• выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов.
Различают количественную и качественную обработку данных. Количественная обработка – это работа с измеренными характеристиками изучаемого объекта, его «объективированными» свойствами. Качественная обработка представляет собой способ проникновения в сущность объекта путем выявления его неизмеряемых свойств.
Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала: корреляционный анализ, факторный анализ и т. д. Реализуется количественная обработка с помощью математико-статистических методов.
В качественной обработке преобладают синтетические способы познания. Обобщение проводится на следующем этапе исследовательского процесса – интерпретационном. При качественной обработке данных главное заключается в соответствующем представлении сведений об изучаемом явлении, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики.
Противопоставление друг другу качественной и количественной обработки довольно условно. Количественный анализ без последующей качественной обработки бессмыслен, так как сам по себе не приводит к приращению знаний, а качественное изучение объекта без базовых количественных данных в научном познании невозможно. Без количественных данных научное познание – чисто умозрительная процедура.
Единство количественной и качественной обработки наглядно представлено во многих методах обработки данных: факторном и таксономическом анализе, шкалировании, классификации и др. Наиболее распространены такие приемы количественной обработки, как классификация, типологизация, систематизация, периодизация, казуистика.
Качественная обработка естественным образом выливается в описание и объяснение изучаемых явлений, что составляет уже следующий уровень их изучения, осуществляемый на стадии интерпретации результатов. Количественная же обработка полностью относится к этапу обработки данных.
7.2. Первичная статистическая обработка данных
Все методы количественной обработки принято подразделять на первичные и вторичные.
Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении.
В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями.
К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных.
Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале.
Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода.
Выборочное среднее (М) – это результат деления суммы всех значений (Х) на их количество (N).
Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение – при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду.
Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной.
Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции.
Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки.
Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение.
Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных.
Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
где d = |Х – М |, М – среднее выборки, Х – конкретное значение, N – число значений.
Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану.
Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:
где d = |Х – М|, М – среднее выборки, Х – конкретное значение, N – число значений.
Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:
где d = |Х– М|, М – среднее выборки, Х– конкретное значение, N – число значений.
При симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
7.3. Вторичная статистическая обработка данных
К вторичным относят такие методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. Вторичные методы можно подразделить на способы оценки значимости различий и способы установления статистических взаимосвязей.
Способы оценки значимости различий. Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, используют т-критерий Стьюдента. Его формула выглядит следующим образом:
где М1, М2 – выборочные средние значения сравниваемых выборок, m1, m2 – интегрированные показатели отклонений частных значений из двух сравниваемых выборок, вычисляются по следующим формулам:
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя т по таблице критических значений (см. Статистическое приложение 1), заданного числа степеней свободы (N1 + N2 – 2) и избранной вероятности допустимой ошибки (0,05, 0,01, 0,02, 001 и т.д.) находят табличное значение т. Если вычисленное значение т больше или равно табличному, делают вывод о том, что сравниваемые средние значения двух выборок статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной.
где Pk – частоты распределения в первом замере, Vk – частоты распределения во втором замере, м – общее число групп, на которые разделились результаты замеров.
Для сравнения дисперсий двух выборок используется F-критерий Фишера. Его формула выглядит следующим образом:
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках.
После вычисления значения показателя F по таблице критических значений (см. Статистическое приложение 3), заданного числа степеней свободы (N1 – 1, N2 – 1) находится Fкр. Если вычисленное значение F больше или равно табличному, делают вывод о том, что различие дисперсий в двух выборках статистически достоверно.
Способы установления статистических взаимосвязей. Предыдущие показатели характеризуют совокупность данных по какому-либо одному признаку. Этот изменяющийся признак называют переменной величиной или просто переменной. Меры связи выявляют соотношения между двумя переменными или между двумя выборками. Эти связи, или корреляции, определяют через вычисление коэффициентов корреляции. Однако наличие корреляции не означает, что между переменными существует причинная (или функциональная) связь. Функциональная зависимость – это частный случай корреляции. Даже если связь причинна, корреляционные показатели не могут указать, какая из двух переменных является причиной, а какая – следствием. Кроме того, любая обнаруженная в психологических исследованиях связь, как правило, существует благодаря и другим переменным, а не только двум рассматриваемым. К тому же взаимосвязи психологических признаков столь сложны, что их обусловленность одной причиной вряд ли состоятельна, они детерминированы множеством причин.
По тесноте связи можно выделить следующие виды корреляции: полная, высокая, выраженная, частичная; отсутствие корреляции. Эти виды корреляций определяют в зависимости от значения коэффициента корреляции.
При полной корреляции его абсолютные значения равны или очень близки к 1. В этом случае устанавливается обязательная взаимозависимость между переменными. Здесь вероятна функциональная зависимость.
Высокая корреляция устанавливается при абсолютном значении коэффициента 0,8–0,9. Выраженная корреляция считается при абсолютном значении коэффициента 0,6–0,7. Частичная корреляция существует при абсолютном значении коэффициента 0,4–0,5.
Абсолютные значения коэффициента корреляции менее 0,4 свидетельствуют об очень слабой корреляционной связи и, как правило, в расчет не принимаются. Отсутствие корреляции констатируется при значении коэффициента 0.
Кроме того, в психологии при оценке тесноты связи используют так называемую «частную» классификацию корреляционных связей. Она ориентирована не на абсолютную величину коэффициентов корреляции, а на уровень значимости этой величины при определенном объеме выборки. Эта классификация применяется при статистической оценке гипотез. При данном подходе предполагается, что чем больше выборка, тем меньшее значение коэффициента корреляции может быть принято для признания достоверности связей, а для малых выборок даже абсолютно большое значение коэффициента может оказаться недостоверным.[86]
По направленности выделяют следующие виды корреляционных связей: положительная (прямая) и отрицательная (обратная). Положительная (прямая) корреляционная связь регистрируется при коэффициенте со знаком «плюс»: при увеличении значения одной переменной наблюдается увеличение другой. Отрицательная (обратная) корреляция имеет место при значении коэффициента со знаком «минус». Это означает обратную зависимость: увеличение значения одной переменной влечет за собой уменьшение другой.
По форме различают следующие виды корреляционных связей: прямолинейную и криволинейную. При прямолинейной связи равномерным изменениям одной переменной соответствуют равномерные изменения другой. Если говорить не только о корреляциях, но и о функциональных зависимостях, то такие формы зависимости называют пропорциональными. В психологии строго прямолинейные связи – явление редкое. При криволинейной связи равномерное изменение одного признака сочетается с неравномерным изменением другого. Эта ситуация для психологии типична.
Коэффициент линейной корреляции по К. Пирсону (r) вычисляется с помощью следующей формулы:
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 4).
При сравнении порядковых данных применяется коэффициент ранговой корреляции по Ч. Спирмену (R):
где d – разность рангов (порядковых мест) двух величин, N – число сравниваемых пар величин двух переменных (Х и У).
Оценка значимости коэффициента корреляции проводится по таблице (см. Статистическое приложение 5).
Внедрение в научные исследования автоматизированных средств обработки данных позволяет быстро и точно определять любые количественные характеристики любых массивов данных. Разработаны различные программы для компьютеров, по которым можно проводить соответствующий статистический анализ практически любых выборок. Из массы статистических приемов в психологии наибольшее распространение получили следующие: 1) комплексное вычисление статистик; 2) корреляционный анализ; 3) дисперсионный анализ; 4) регрессионный анализ; 5) факторный анализ; 6) таксономический (кластерный) анализ; 7) шкалирование. Познакомиться с характеристиками этих методов можно в специальной литературе («Статистические методы в педагогике и психологии» Стенли Дж., Гласа Дж. (М., 1976), «Математическая психология» Г.В. Суходольского (СПб., 1997), «Математические методы психологического исследования» А.Д. Наследова (СПб., 2005) и др.).
Тема 8. Интерпретация и представление результатов психологических исследований
8.1. Интерпретация и обобщение результатов исследования
Методы интерпретации данных корректнее называть подходами, поскольку они являются в первую очередь объяснительными принципами, предопределяющими направление интерпретации результатов исследования. В научной практике получили развитие генетический, структурный, функциональный, комплексный и системный подходы. Использование того или иного метода не означает отбрасывания других.
Генетический подход – это способ исследования и объяснения явлений (в том числе психических), основанный на анализе их развития как в онтогенетическом, так и филогенетическом планах. При этом требуется установление: 1) начальных условий возникновения явления; 2) главных этапов и 3) основных тенденций его развития. Цель генетического подхода – выявление связи изучаемых явлений во времени, прослеживание перехода от низших форм к высшим.
Чаще всего генетический подход применяется при интерпретации результатов в психологии развития: сравнительной, возрастной, исторической. Любое лонгитюдное исследование предполагает применение рассматриваемого подхода.
Генетический подход рассматривается как методическая реализация одного из основных принципов психологии, а именно принципа развития.[87] При таком видении другие варианты реализации этого принципа рассматриваются как модификации генетического подхода (исторический и эволюционный подходы).
Структурный подход – направление, ориентированное на выявление и описание структуры объектов (явлений). Для него характерно: углубленное внимание к описанию актуального состояния объектов; выяснение внутренне присущих им вневременных свойств; интерес не к изолированным фактам, а к отношениям между ними. В итоге строится система взаимосвязей между элементами объекта на различных уровнях его организации.[88]
Достоинством структурного подхода является возможность наглядного представления результатов в виде различных моделей. Эти модели могут даваться в форме описаний, перечня элементов, графической схемы, классификации и пр. Примеры подобного моделирования можно найти у З. Фрейда, Г. Айзенка и др.
Структурный подход часто применяется в исследованиях, посвященных изучению конституциональной организации психики и ее материального субстрата – нервной системы. Данный подход привел к созданию И.П. Павловым типологии высшей нервной деятельности, который затем был развит Б.М. Тепловым и В.Д. Небылицыным. Структурные модели человеческой психики в пространственном и функциональном аспектах представлены в работах В.А. Ганзена,[89] В.В. Никандрова[90] и др.
Функциональный подход ориентирован на выявление и изучение функций объектов (явлений). Он применяется главным образом при изучении связей объекта со средой. Этот подход исходит из принципа саморегуляции и поддержания равновесия объектов действительности. Примерами реализации функционального подхода в истории науки являются такие известные направления, как функциональная психология и бихевиоризм. Классическим образцом воплощения функционального подхода в психологии является динамическая теория поля К. Левина. В современной психологии функциональный подход обогащается компонентами структурного и генетического анализа. Общеизвестным считается представление о многоуровневости и многофазности всех психических функций человека, действующих одновременно на всех уровнях как единое целое. Элементы структур большинство авторов соответствующих моделей рассматривают также и как функциональные единицы, олицетворяющие определенные связи человека с действительностью.
Комплексный подход – это направление, рассматривающее объект исследования как совокупность компонентов, подлежащих изучению с помощью соответствующей совокупности методов. Компоненты могут быть как относительно однородными частями целого, так и его разнородными сторонами, характеризующими изучаемый объект в разных аспектах.
Часто комплексный подход предполагает изучение сложного объекта методами различных наук, т. е. организацию междисциплинарного исследования. Очевидно, что он предполагает применение в той или иной мере и всех предыдущих интерпретационных методов.
Яркий пример реализации комплексного подхода в науке – концепция человекознания, согласно которой человек как объект изучения подлежит скоординированному исследованию большого комплекса наук. В психологии эта идея комплексности изучения человека была четко сформулирована Б.Г. Ананьевым.[91] Человек рассматривается одновременно как представитель биологического вида (индивид), носитель сознания и активный элемент познавательной и преобразующей действительность деятельности (субъект), субъект социальных отношений (личность) и уникальное единство социально значимых биологических, социальных и психологических особенностей (индивидуальность).
Системный подход – это методологическое направление в изучении реальности, рассматривающее любой ее фрагмент как систему. Основателем системного подхода как неотъемлемого методологического и методического компонента научного познания можно считать австрийского ученого, переехавшего в США, Л. Берталанфи, разработавшего общую теорию систем.[92] Система есть некоторая целостность, взаимодействующая с окружающей средой и состоящая из множества элементов, находящихся между собой в некоторых отношениях и связях. Организация этих связей между элементами называется структурой. Элемент – мельчайшая часть системы, сохраняющая ее свойства в пределах данной системы. Дальнейшее расчленение этой части ведет к потере соответствующих свойств. Свойства элементов определяются их положением в структуре и, в свою очередь, определяют свойства системы. Но свойства системы не сводятся к сумме свойств элементов. Система как целое синтезирует (объединяет и обобщает) свойства частей и элементов, в результате чего она обладает свойствами более высокого уровня организации, которые во взаимодействии с другими системами могут представать как ее функции. Любая система может рассматриваться, с одной стороны, как объединение более простых (мелких) подсистем со своими свойствами и функциями, а с другой – как подсистема более сложных (крупных) систем.
Системные исследования осуществляются с помощью системных анализа и синтеза. В процессе анализа система выделяется из среды, определяются ее состав (набор элементов), структура, функции, интегральные свойства и характеристики, системообразующие факторы, взаимосвязи со средой. В процессе синтеза создается модель реальной системы, повышается уровень обобщения и абстракции описания системы, определяются полнота ее состава и структур, закономерности развития и поведения.
Описание объектов как систем, т. е. системные описания, выполняют те же функции, что и любые другие научные описания, – объяснительную и прогнозирующую. Но еще важнее, что системные описания выполняют функцию интеграции знаний об объектах.
Рассмотренные выше подходы являются фактически органичными компонентами системного подхода. Некоторые авторы сопоставляют эти подходы с соответствующими уровнями качеств человека, составляющих предмет психологического исследования (В.П. Кузьмин[93] и др.).
В настоящее время большинство научных исследований проводится в русле системного подхода. Наиболее полное освещение применительно к психологии системный подход нашел в работах В.А. Ганзена,[94] А.А. Крылова,[95] Б.Ф. Ломова,[96] А. Раппопорта[97] и др.
8.2. Формы представления результатов исследования
Завершением любой исследовательской работы является представление результатов в той форме, которая принята научным сообществом. Следует различать две основные формы представления результатов: квалификационную и научно-исследовательскую.
Квалификационная работа – курсовая, дипломная работа, диссертация и т. д. – служит для того, чтобы студент, аспирант или соискатель, представив свое научное исследование, получил документ, удостоверяющий уровень компетентности. Требования к таким работам, способу их оформления и представления результатов изложены в соответствующих инструкциях и положениях, принятых учеными советами.
Результаты научно-исследовательской работы – это результаты, полученные в ходе исследовательской деятельности ученого. Представление научных результатов обычно происходит в трех формах: 1) устные изложения; 2) публикации; 3) электронные версии. В любой их этих форм присутствует описание. В. А. Ганзен под описанием понимает любую форму представления информации о полученных в исследовании результатах.[98]
Различают следующие варианты представления информации: вербальная форма (текст, речь), символическая (знаки, формулы), графическая (схемы, графики), предметнообразная (макеты, вещественные модели, фильмы и др.).
Вербальная форма – наиболее распространенный вариант представления описаний. Любое научное сообщение – это прежде всего текст, организованный по определенным правилам. Различают два вида текстов: на естественном языке («природном», обыденном) и на научном языке. Обычно представление результатов научного исследования является текстом «смешанного» вида, где в естественную речевую структуру включены фрагменты, сформулированные на строго научном языке. Эти языки нельзя строго разграничить: научные термины входят в повседневное обращение, а наука черпает из естественного языка слова для обозначения вновь открытых сторон реальности. Но в отличие от обыденного употребления каждый научный термин имеет однозначное предметное содержание. В психологии в качестве научных терминов употребляются такие слова, как «личность», «внимание», «чувство» и т. п. Здесь грань между научной и обыденной терминологией весьма тонка, что порождает дополнительную трудность для автора-психолога.
Главное требование к научному тексту – последовательность и логичность изложения. Автор должен по возможности не загружать текст избыточной информацией, но может использовать метафоры, примеры, для того чтобы привлечь внимание к особо значимому для понимания сути звену рассуждений. Научный текст в отличие от литературного текста или повседневной речи очень клиширован – в нем преобладают устойчивые структуры и обороты (в этом он сходен с «канцеляритом» – бюрократическим языком деловых бумаг). Роль таких штампов чрезвычайно важна, поскольку внимание читателя не отвлекается на литературные изыски или неправильности изложения, а сосредоточивается на значимой информации: суждениях, умозаключениях, доказательствах, цифрах, формулах. «Наукообразные» штампы на самом деле играют важную роль «рамок», стандартной установки для нового научного содержания.
Текст состоит из высказываний. Каждое высказывание имеет определенную логическую форму. Существуют основные логические формы высказывания: 1) индуктивное – обобщающее некоторый эмпирический материал; 2) дедуктивное – логический вывод от общего к частному или описание алгоритма; 3) аналогия – «трансдукция»; 4) толкование или комментарий – «перевод», раскрытие содержания одного текста посредством создания другого.
Геометрические (пространственно-образные) описания являются традиционным способом кодирования научной информации. Поскольку геометрическое описание дополняет и поясняет текст, оно «привязано» к описанию языковому. Геометрическое описание наглядно. Оно позволяет одновременно представить систему отношений между отдельными переменными, исследуемыми в эксперименте. Информационная емкость геометрического описания очень велика.
В психологии используется несколько основных форм графического представления научной информации. Для первичного представления данных используются следующие графические формы: диаграммы, гистограммы и полигоны распределения, а также различные графики.
Начальным способом представления данных является изображение распределения. Для этого используют гистограммы и полигоны распределения. Часто для наглядности распределение показателя в экспериментальной и контрольной группах изображают на одном рисунке.
Гистограмма – это «столбчатая» диаграмма частотного распределения признака на выборке. При построении гистограмм на оси абсцисс откладывают значения измеряемой величины, а на оси ординат – частоты или относительные частоты встречаемости данного диапазона величины в выборке.
В полигоне распределения количество испытуемых, имеющих данную величину признака (или попавших в определенный интервал величины), обозначают точкой с координатами. Точки соединяются отрезками прямой. Перед тем как строить полигон распределения или гистограмму, исследователь должен разбить диапазон измеряемой величины, если признак дан в шкале интервалов или отношений, на равные отрезки. Рекомендуют использовать не менее пяти, но не более десяти градаций. В случае использования шкалы наименований или порядковой шкалы такой проблемы не возникает.
Если исследователь хочет нагляднее представить соотношение между различными величинами, например доли испытуемых с разными качественными особенностями, то ему выгоднее использовать диаграмму. В секторной круговой диаграмме величина каждого сектора пропорциональна величине встречаемости каждого типа. Величина круговой диаграммы может отображать относительный объем выборки или значимость признака.
Переходным от графического к аналитическому вариантом отображения информации являются в первую очередь графики, представляющие функциональную зависимость признаков. Идеальный вариант завершения экспериментального исследования – обнаружение функциональной связи независимой и зависимой переменных, которую можно описать аналитически.
Можно выделить два различных по содержанию типа графиков: 1) отображающие зависимость изменения параметров во времени; 2) отображающие связь независимой и зависимой переменных (или любых двух других переменных). Классическим вариантом изображения временной зависимости является обнаруженная Г. Эббингаузом связь между объемом воспроизведенного материала и временем, прошедшим после заучивания («кривая забывания»). Аналогичны многочисленные «кривые заучивания» или «кривые утомления», показывающие изменение эффективности деятельности во времени.
В психологии часто встречаются и графики функциональной зависимости двух переменных: законы Г. Фехнера, С. Стивенса (в психофизике), закономерность, описывающая зависимость вероятности воспроизведения элемента от его места в ряду (в когнитивной психологии), и т. п.
Л.В. Куликов дает начинающим исследователям ряд простых рекомендаций по построению графиков.[99]
1. График и текст должны взаимно дополнять друг друга.
2. График должен быть понятен «сам по себе» и включать все необходимые обозначения.
3. На одном графике не разрешается изображать больше четырех кривых.
4. Линии на графике должны отражать значимость параметра, важнейшие параметры необходимо обозначать цифрами.
5. Надписи на осях следует располагать внизу и слева.
6. Точки на разных линиях принято обозначать кружками, квадратами и треугольниками.
Если необходимо на том же графике представить величину разброса данных, то их следует изображать в виде вертикальных отрезков, чтобы точка, обозначающая среднее, находилась на отрезке (в соответствии с показателем асимметрии).
Видом графиков являются диагностические профили, которые характеризуют среднюю выраженность измеряемых показателей у группы или определенного индивида.
При представлении информации с использованием топологических характеристик применяются графы. Например, в виде графа представлена иерархическая модель интеллекта Д. Векслера.
Наряду с графами в психологии применяются пространственно-графические описания, в которых учитываются структура параметров и отношения между элементами. Примером является описание структуры интеллекта – «куб» Д. Гилфорда. Другой вариант применения пространственного описания – пространство эмоциональных состояний по В. Вундту или же описание типов личности по Г. Айзенку («круг Айзенка»).
В случае, если в пространстве признаков определена метрика, используется более строгое представление данных. Положение точки в пространстве, изображенном на рисунке, соответствует ее реальным координатам в пространстве признаков. Таким способом представляются результаты многомерного шкалирования, факторного и латентно-структурного анализа, а также некоторых вариантов кластерного анализа.
Наиболее важный способ представления результатов научной работы – числовые значения величины, в частности:
1) показатели центральной тенденции (среднее, мода, медиана);
2) абсолютные и относительные частоты;
3) показатели разброса (стандартное отклонение, дисперсия, процентильный разброс);
4) значения критериев, использованных при сравнении результатов разных групп;
5) коэффициенты линейной и нелинейной связи переменных и т. д.
Стандартный вид таблиц для представления первичных результатов таков: по строкам располагаются испытуемые, по столбцам – значения измеренных параметров. Результаты математической статистической обработки также сводятся в таблицы. Существующие компьютерные пакеты статистической обработки данных позволяют выбрать любую стандартную форму таблиц для представления их в научной публикации.
Приложения
1. Этические принципы проведения исследования на человеке (American Psychological Association, 1973)[100]
Решение проводить исследования должно основываться на осознанном желании каждого психолога внести ощутимый вклад в психологическую науку и способствовать благополучию человека. Ответственный психолог обдумывает различные направления, где нужны энергия и возможности человека.
Приняв решение о проведении исследований, психологи должны осуществлять свои замыслы с уважением к людям, принимающим в них участие, и с заботой об их достоинстве и благополучии.
Принципы, о которых говорится ниже, разъясняют исследователю этичное ответственное отношение к участникам экспериментов в ходе проведения исследовательских работ – от первоначального замысла до шагов, необходимых для защиты конфиденциальности данных исследований. Эти принципы должны рассматриваться в контексте документов, прилагаемых в качестве дополнения к принципам.
1. При планировании опыта исследователь несет персональную ответственность за составление точной оценки его этической приемлемости, опираясь на принципы исследований. Если, опираясь на эту оценку и взвесив научные и человеческие ценности, исследователь предлагает отклониться от принципов, то он дополнительно берет на себя серьезные обязательства по разработке этических рекомендаций и принятию более строгих мер по защите прав участников исследований.
2. На каждом исследователе всегда лежит ответственность за установление и поддержание приемлемой этики исследования. Исследователь также несет ответственность за этичное обращение коллег, ассистентов, студентов и всех других служащих с испытуемыми.
3. Этика требует, чтобы исследователь информировал испытуемых обо всех сторонах эксперимента, которые могут повлиять на их желание принимать в нем участие, а также отвечал на все вопросы о других подробностях исследования. Невозможность ознакомления с полной картиной эксперимента дополнительно усиливает ответственность исследователя за благополучие и достоинство испытуемых.
4. Честность и открытость – важные черты отношений между исследователем и испытуемым. Если утаивание и обман необходимы по методологии исследования, то исследователь должен объяснить испытуемому причины таких действий для восстановления их взаимоотношений.
5. Этика требует, чтобы исследователь относился с уважением к праву клиента сократить или прервать свое участие в процессе исследований в любое время. Обязательство по защите этого права требует особой бдительности, когда исследователь находится в позиции, доминирующей над участником. Решение по ограничению этого права увеличивает ответственность исследователя за достоинство и благополучие участника.
6. Этически приемлемое исследование начинается с установления четкого и справедливого соглашения между исследователем и участником эксперимента, разъясняющего ответственность сторон. Исследователь обязан чтить все обещания и договоренности, включенные в это соглашение.
7. Этичный исследователь защищает своих клиентов от физического и душевного дискомфорта, вреда и опасности. Если риск таких последствий существует, то исследователь обязан проинформировать об этом испытуемых, достичь согласия до начала работы и принять все возможные меры для минимизации вреда. Процедура исследований не должна применяться, если есть вероятность, что она причинит серьезный и продолжительный вред участникам.
8. Этика работы требует, чтобы после сбора данных исследователь обеспечил участникам полное разъяснение сути эксперимента и устранил любые возникающие недоразумения. Если научные или человеческие ценности оправдывают задержку или утаивание информации, то исследователь несет особую ответственность за то, чтобы для его клиентов не было тяжелых последствий.
9. Если процедура исследования может иметь нежелательные последствия для участников, то исследователь несет ответственность за выявление, устранение или корректировку таких результатов (в том числе и долговременных).
Информация, полученная в ходе исследования, является конфиденциальной. Если существует вероятность, что другие люди могут получить доступ к этой информации, то этика практики исследований требует, чтобы эта вероятность, а также планы по обеспечению конфиденциальности были объяснены участникам как часть процесса по достижению взаимного информационного согласия.
2. Статистические приложения
1. Значимость т-распределения Стьюдента
3. Граничные значения F-критерия Фишера для вероятности допустимой ошибки 0,05 и числа степеней свободы N1 и N2
4. Таблица значимости коэффициента корреляции (по Пирсону)
5. Таблица значимости коэффициента корреляции рангов (по Ч. Спирмену)


