Дисперсия и стандартное отклонение
Дисперсия случайной величины — мера разброса данной случайной величины, то есть её отклонения от математического ожидания. В статистике для обозначения дисперсии часто употребляется обозначение  (сигма в квадрате). Квадратный корень из дисперсии
(сигма в квадрате). Квадратный корень из дисперсии  , равный
, равный  , называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
, называется стандартным отклонением или стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения.
Хотя для оценки всей выборки очень удобно использовать лишь одно значение (такое как среднее значение или моду и медиану), этот подход легко может привести к неправильным выводам. Причина такого положения лежит не в самой величине, а в том, что одна величина никак не отражает разброс значений данных.
Например, в выборке:
среднее значение равно 5.
Однако, в самой выборке нет ни одного элемента со значением 5. Возможно, Вам потребуется знать степень близости каждого элемента выборки к ее среднему значению. Или, другими словами, вам потребуется знать дисперсию значений. Зная степень изменения данных, Вы можете лучше интерпретировать среднее значение, медиану и моду. Степень изменения значений выборки определяется путем вычисления их дисперсии и стандартного отклонения.
Дисперсия и квадратный корень из дисперсии, называемый стандартным отклонением, характеризуют среднее отклонение от среднего значения выборки. Среди этих двух величин наибольшее значение имеет стандартное отклонение. Это значение можно представить как среднее расстояние, на котором находятся элементы от среднего элемента выборки.
Дисперсию трудно интерпретировать содержательно. Однако, квадратный корень из этого значения является стандартным отклонением и хорошо поддается интерпретации.
Стандартное отклонение вычисляется путем определения сначала дисперсии и затем вычисления квадратного корня из дисперсии.
Например, для массива данных, приведенных на рисунке, будут получены следующие значения:
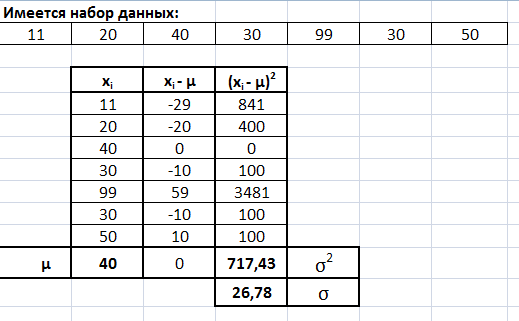
Здесь среднее значение квадратов разностей равно 717,43. Для получения стандартного отклонения осталось лишь взять квадратный корень из этого числа.
Результат составит приблизительно 26,78.
Следует помнить, что стандартное отклонение интерпретируется как среднее расстояние, на котором находятся элементы от среднего значения выборки.
Стандартное отклонение показывает, насколько хорошо среднее значение описывает всю выборку.
Допустим, Вы являетесь руководителем производственного отдела по сборке ПК. В квартальном отчете говорится, что выпуск за последний квартал составил 2500 ПК. Плохо это или хорошо? Вы попросили (или уже в отчете есть эта графа) в отчете отобразить стандартное отклонение по этим данным. Цифра стандартного отклонения, например, равна 2000. Становится понятным для Вас, как руководителя отдела, что производственная линия требует лучшего управления (слишком большие отклонения по количеству собираемых ПК).
Вспомним: при большой величине стандартного отклонения данные широко разбросаны относительно среднего значения, а при маленькой – они группируются близко к среднему значению.
Четыре статистические функции ДИСП(), ДИСПР(), СТАНДОТКЛОН() и СТАНДОТКЛОНП() – предназначены для вычисления дисперсии и стандартного отклонения чисел в интервале ячеек. Перед тем как вычислять дисперсию и стандартное отклонение набора данных, нужно определить, представляют ли эти данные генеральную совокупность или выборку из генеральной совокупности. В случае выборки из генеральной совокупности следует использовать функции ДИСП() и СТАНДОТКЛОН(), а в случае генеральной совокупности – функции ДИСПР() и СТАНДОТЛОНП():
| Генеральная совокупность | Функция |
 | ДИСПР() |
 | СТАНДОТЛОНП() |
| Выборка | |
 | ДИСП() |
 | СТАНДОТКЛОН() |
Дисперсия (а так же стандартное отклонение), как мы отмечали, свидетельствуют о том, в какой степени входящие в набор данных величины разбросаны вокруг среднего арифметического.
Малое значение дисперсии или стандартного отклонения говорит о том, что все данные сосредоточены вокруг среднего арифметического, а большое значение этих величин – о том, что данные разбросаны в широком диапазоне значений.
Дисперсию достаточно трудно интерпретировать содержательно (что значит малое значение, большое значение?). Выполнение Задания 3позволит визуально, на графике, показать смысл дисперсии для набора данных.
Задания
· 2.1. Дать понятия: дисперсия и стандартное отклонение; их символьное обозначение при статистической обработке данных.
· 2.2. Оформить рабочий лист в соответствии с рисунком 1 и произвести необходимые расчеты.
· 2.3. Привести основные формулы, используемые при расчетах
· 2.4. Пояснить все обозначения (  ,
,  , ,
, ,  )
)
· 2.5. Пояснить практическое значение понятия дисперсия и стандартное отклонение.
Задание 2.
1.1. Дать понятия: генеральная совокупность и выборка; математическое ожидание и среднее арифметическое их символьное обозначение при статистической обработке данных.
1.2. В соответствии с рисунком 2 оформить рабочий лист и произвести расчеты.
1.3. Привести основные формулы, используемые при расчетах (для генеральной совокупности и выборке).

1.4. Объяснить, почему возможны получения таких значений средних арифметических в выборках как 46,43 и 48,78 (см. файл Приложение). Сделать выводы.
Задание 3.
Имеется две выборки с различным набором данных, но среднее для них будет одинаковым:

 | |
| Рисунок 4 | Рисунок 5 |
| Видно, что практически разброса нет. Значение дисперсии 0,008 и стандартного отклонения – 0,089. Все очень наглядно. | Разброс данных явный, что подтверждает значение дисперсии – 2,19 и стандартного отклонения – 1,709 |
3.1. Оформить рабочий лист в соответствии с рисунком 3 и произвести необходимые расчеты.
3.2. Приведите основные формулы расчета.
3.3. Постройте графики в соответствии с рисунками 4, 5.
3.4. Поясните полученные зависимости.
3.5. Аналогичные вычисления проведите для данных двух выборок.
Исходная выборка 11119999
Значения второй выборки подбираете так, что бы среднее арифметическое для второй выборки было таким же, например,:

Подберите значения для второй выборки самостоятельно. Оформите вычисления и построения графиков подобно рисункам 3, 4, 5. Покажите основные формулы, которые использовали при вычислениях.
Сделайте соответствующие выводы.
Все задания оформить в виде отчета со всеми необходимыми рисунками, графиками, формулами и краткими пояснениями.
Примечание: построение графиков обязательно пояснить с рисунками и краткими пояснениями.
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:

То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:

s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А 2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:

На практике формула стандартного отклонения следующая:

Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).

Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:

По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
7 базовых статистических понятий, необходимых дата-сайентисту
Даже если вы хорошо программируете, но слабо ориентируетесь в статистике, вероятность выжить в Data Science очень низка.


У статистики есть несколько различных определений. Одно из самых простых и точных — это «наука о сборе и классификации цифровых данных». А если добавить к нему немного о программировании и машинном обучении, то получится неплохое описание основ Data Science.

В самом деле, в Data Science трудно найти область, где нет статистики в том или ином виде. Она нужна для:
Мы выбрали семь базовых концепций, без которых в Data Science точно не обойтись. К счастью, они не слишком сложны.

С некоторых пор утверждает, что он data scientist. В предыдущих сезонах выдавал себя за математика, звукорежиссёра, радиоведущего, переводчика, писателя. Кандидат наук, но не точных. Бесстрашно пишет о Data Science и программировании на Python.
1. Меры описательной статистики
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, мерами центральной тенденции), — это:

Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, меры рассеяния. Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
2. Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
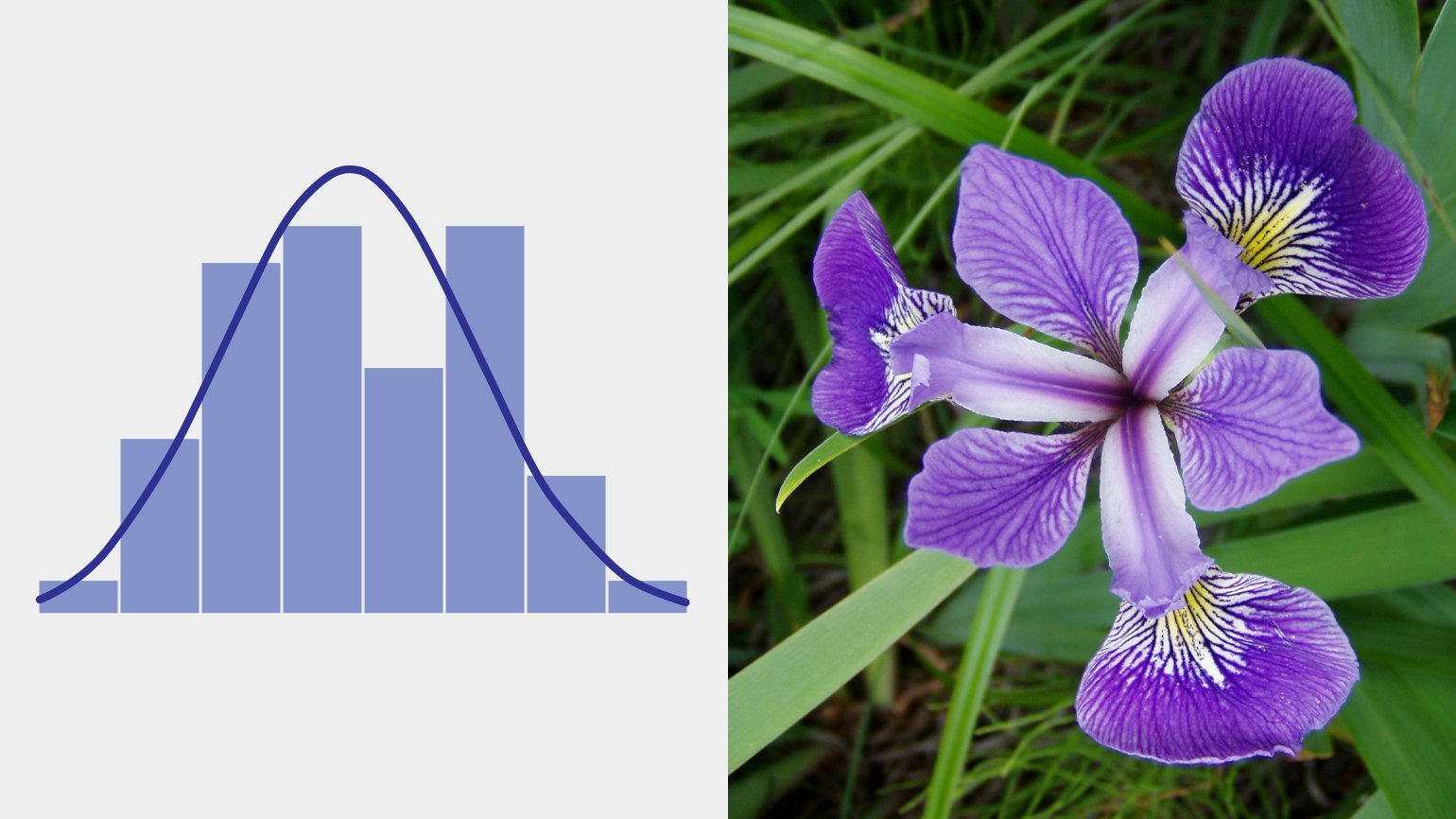
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
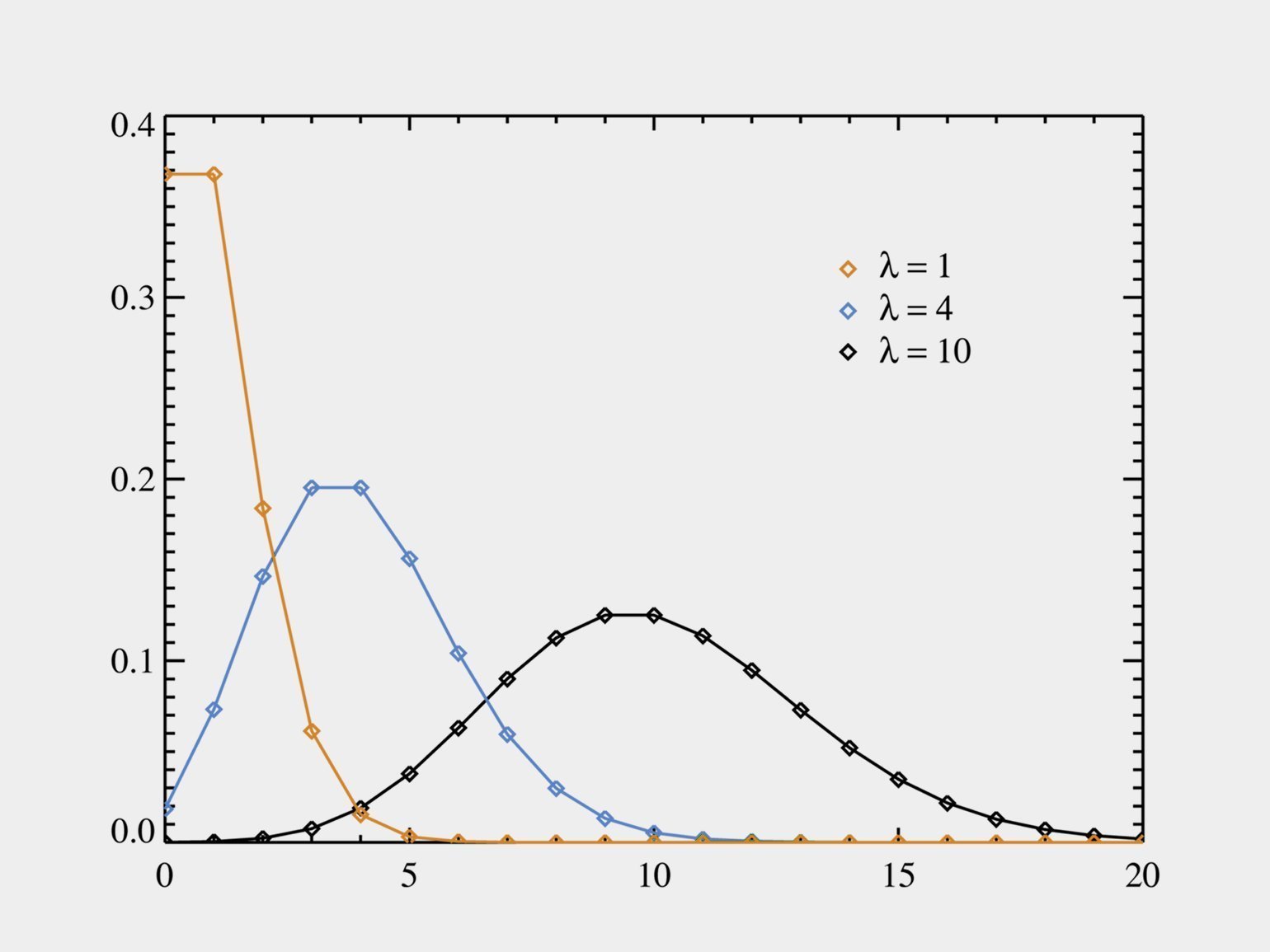
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и другие распределения, в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
3. Семплирование
Предположим, вам требуется решить важную задачу: выяснить среднюю ширину морды домашних котов нашей страны. Прямой способ, то есть измерение всех домашних питомцев, невозможен по ряду объективных причин. Придётся ограничиться выборкой — взять какое-то число животных, измерить морды именно им и сделать выводы по итогам только этих исследований.

Но тут сразу же возникают вопросы:
Семплирование — это группа статистических методов и приёмов, отвечающих на эти вопросы. С помощью семплирования мы формируем нашу выборку так, чтобы она наилучшим образом отражала свойства генеральной совокупности — то есть свойства всех котов страны.

Иными словами, вы не можете измерить N первых попавшихся котов и обобщить результат для остальных. Выборка должна хорошо «сидеть» во всей популяции кошек, чтобы можно было делать обоснованные выводы. Такую выборку называют релевантной.
Кстати, статистика и котики — близнецы-братья. После выхода одноимённой книги Владимира Савельева мы говорим «статистика», а подразумеваем «котики», и наоборот. И смело рекомендуем эту книгу всем, кто дочитал до этого места.
В Data Science методы семплирования применяются при разработке, подготовке и оценке датасетов, чтобы они одновременно и были упорядоченными, и соответствовали реальности.
4. Смещение
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
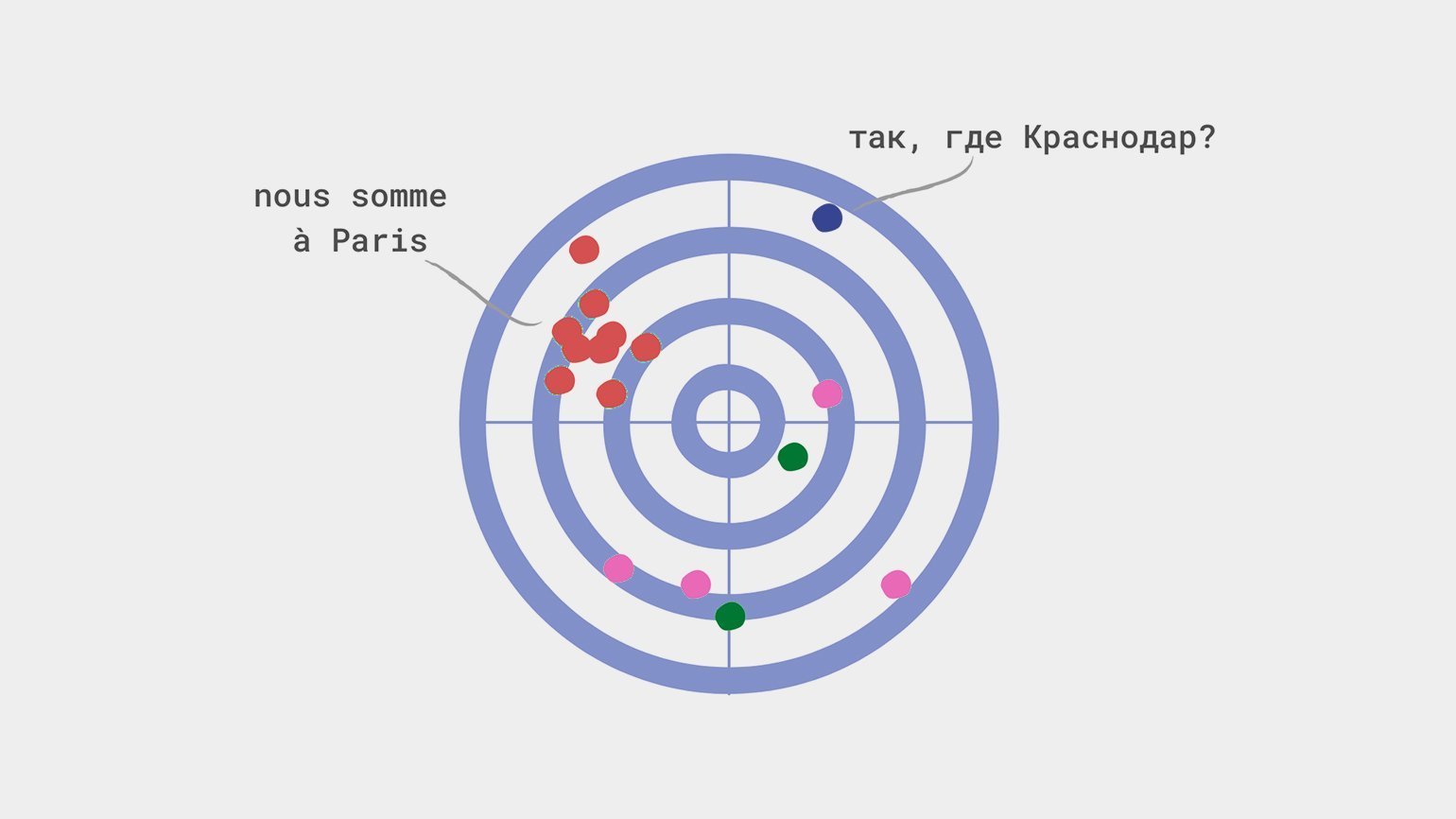
Чаще всего причиной смещения являются:
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.

Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
5. Дисперсия
Дисперсия — это величина, показывающая, как именно и насколько сильно разбросаны значения — например, предсказания модели машинного обучения или доход за рассматриваемый период. За точку, относительно которой эти значения разбросаны, берут истинное значение, целевую переменную или математическое ожидание, которое вычисляется теоретически и заранее.
Часто в качестве матожидания выступает обычное среднее арифметическое. Например, математическое ожидание количества очков при броске игрального кубика равно среднему арифметическому очков на всех гранях:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5
Представьте себе тир, стрелка и мишень. Снайпер стреляет в стандартный круг, где попадание в центр даёт 10 баллов, в зависимости от удаления от центра количество баллов снижается, а крайние области дают всего 1 балл. Каждый выстрел стрелка — это случайное целое значение от 1 до 10.
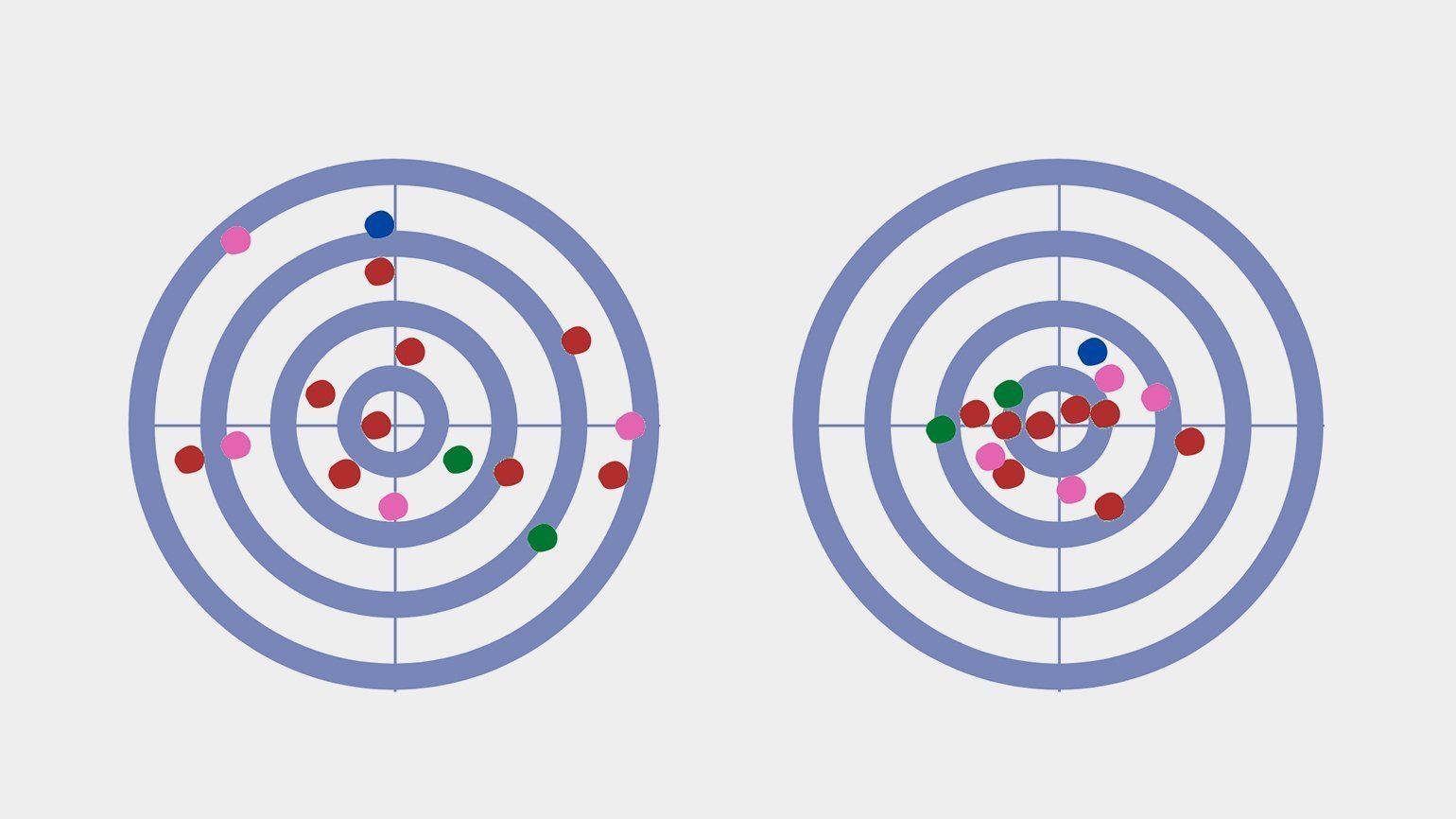
Изрешечённая пулями мишень — отличная иллюстрация распределения. Дисперсия здесь — величина, обратная кучности попаданий: хорошая кучность означает низкую дисперсию, и наоборот.
6. Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо». Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени.
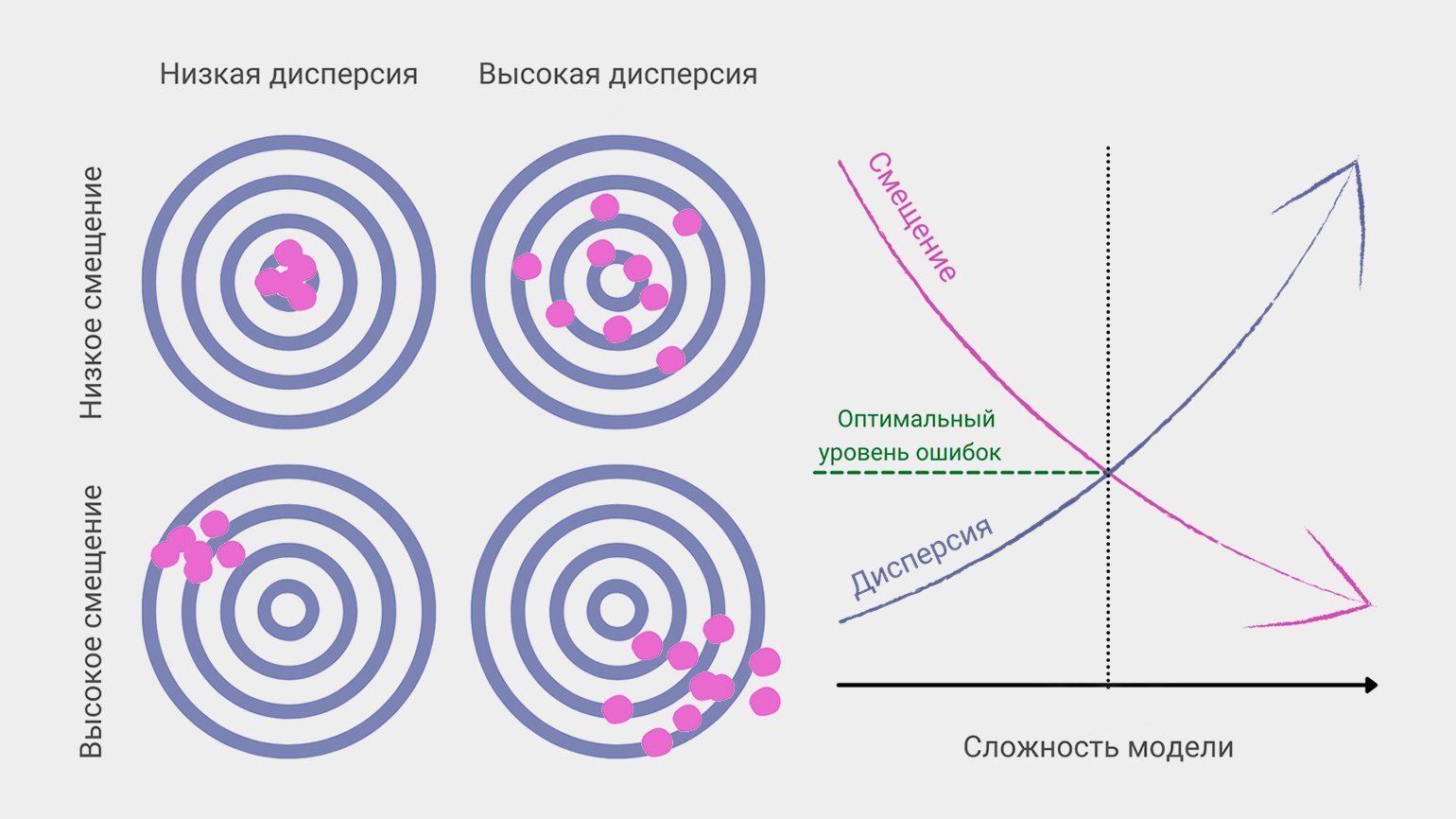
В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
7. Корреляция
Когда изменения одной величины сопутствуют изменениям другой, говорят о корреляции. Главное, что необходимо о ней знать: корреляция не означает причинно-следственную связь.
Линейная корреляция — это когда изменения одной величины пропорциональны изменениям другой. Она может быть:
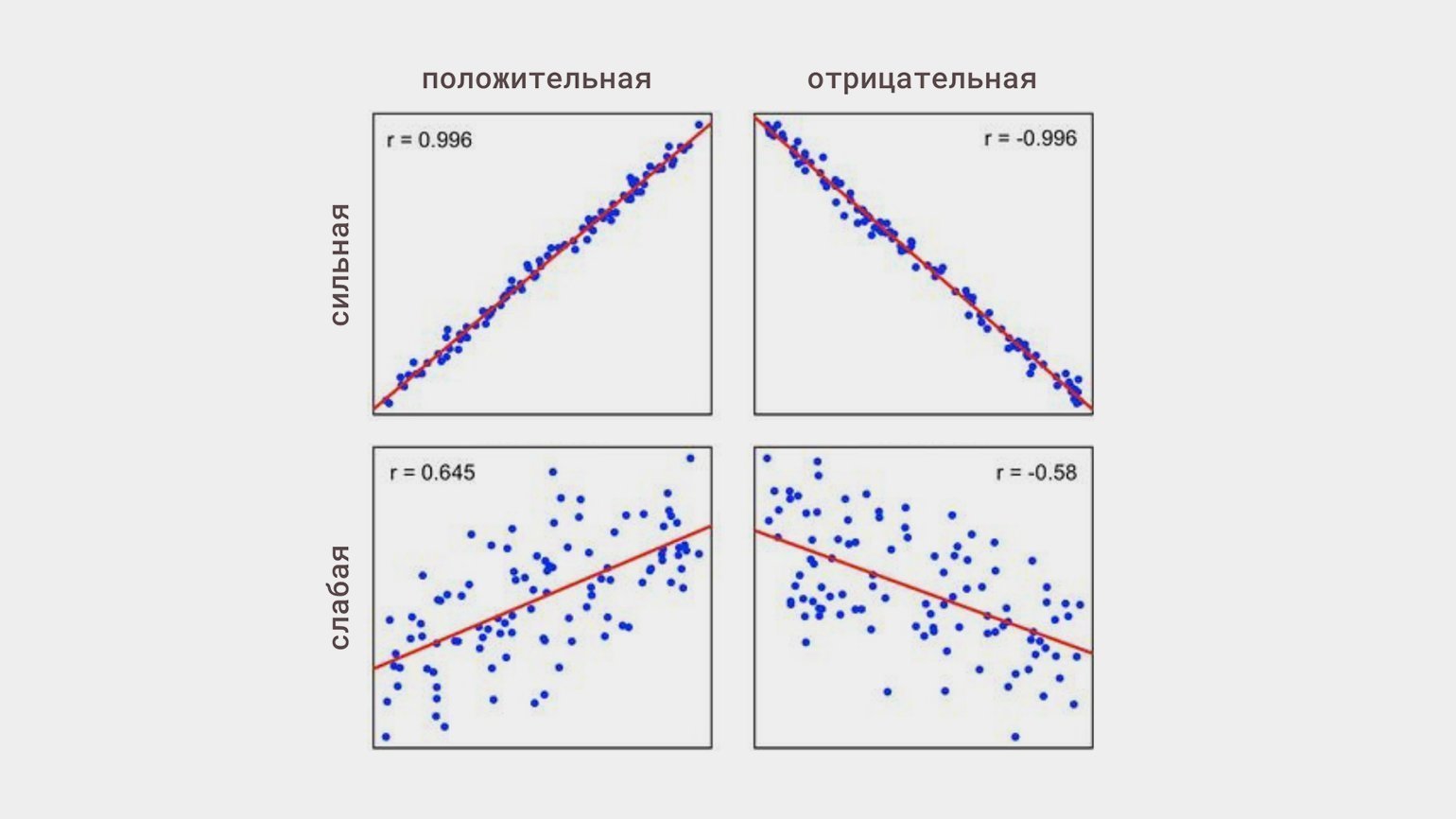
Статистическую связь между переменными исследуют с помощью корреляционного анализа. Его основная задача — оценить тесноту связи (это термин) между переменными, чтобы понять, какие переменные учитывать в модели, а какие нет.
И ещё раз, потому что действительно важно: корреляция ни в коем случае не означает причинно-следственную связь. Если два показателя скоррелированы, то далеко не факт, что они хоть как-то связаны.
Кстати, проект Spurious Correlations («Ложные корреляции») публикует графики корреляций между совершенно неожиданными статистическими показателями — например, количеством людей, утонувших в домашних бассейнах, и числом фильмов с участием Николаса Кейджа.
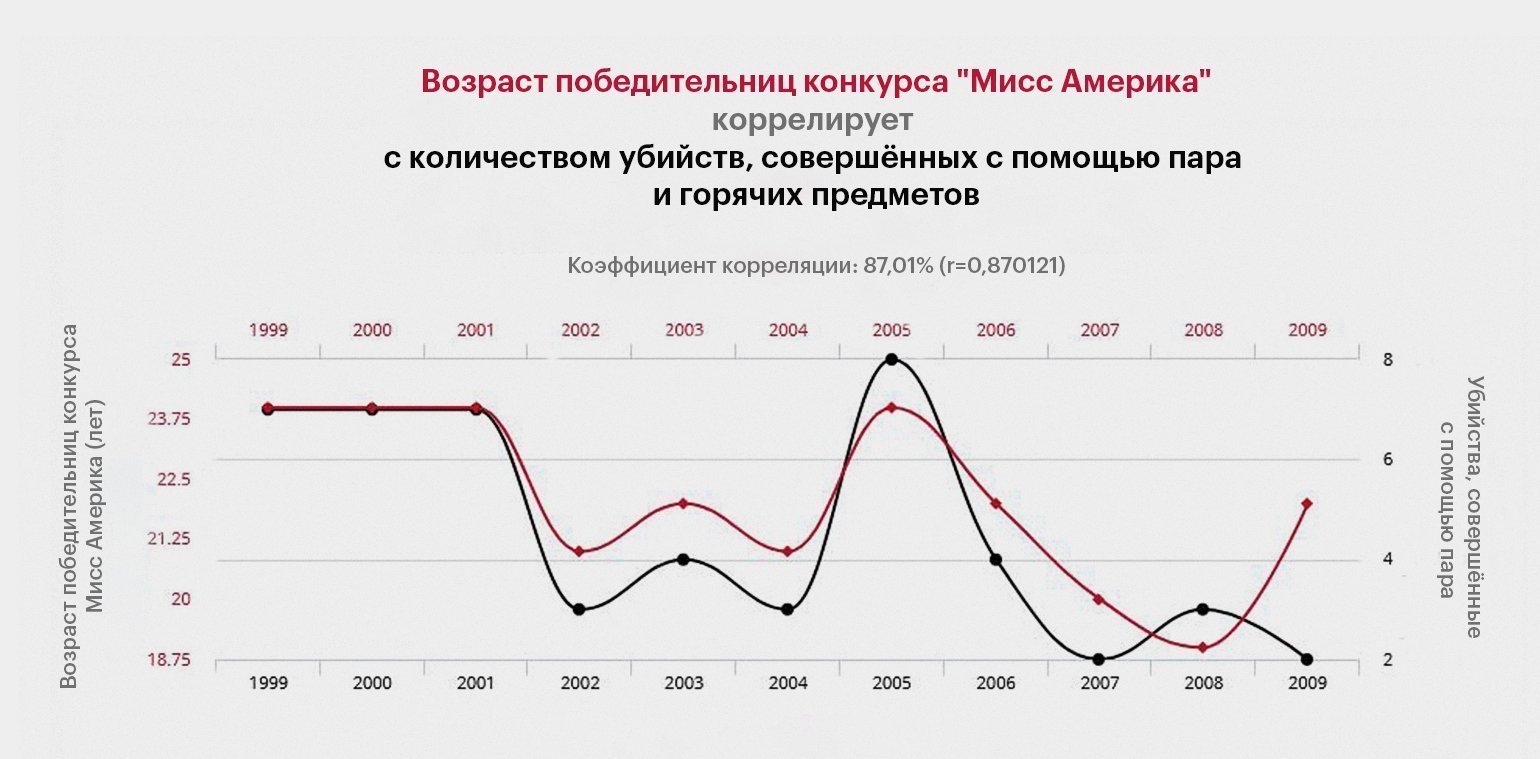
Имеет смысл время от времени заходить по этой ссылке с целью профилактики СПГС — синдрома поиска глубинной связи.
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании. Приходите!
Polina Vari для Skillbox
Для отличия статистического термина от терминов из других отраслей (музыки, биологии) часто пишут этот термин через «е», а не через «э».
Описательная статистика (англ. descriptive statistics) занимается обработкой опытных данных, их систематизацией, наглядным представлением в форме графиков и таблиц, а также их количественным описанием посредством основных статистических показателей.
Тренировочный набор, или обучающая выборка (англ. train set, training sample), — часть данных из датасета, по которой производится настройка или оптимизация модели машинного обучения.
Рекомендательные системы — программы, которые пытаются предсказать, какие объекты (фильмы, музыка, книги, новости, веб-сайты и др.) будут интересны пользователю.
Разницу между наблюдаемым значением и значением, предсказанным моделью.


