Тест итоговый ТФБ. Тема Мировые промышленные тренды Тест 1 Промышленные революции. Причины и последствия
Тест 7.2. Интернет вещей и технологии работы с большими данными
1. Дайте определение Big Data
a. Комплексный набор инструментов обработки структурированных данных колоссальных объемов
b. Комплексный набор подходов, инструментов и методов обработки структурированных и неструктурированных данных колоссальных объемов
c. Комплексный набор методов обработки неструктурированных данных колоссальных объемов
d. Комплексный набор методов обработки структурированных данных колоссальных объемов
2. Главным источником Big Data для большинства компаний являются:
d. События
3. Выберите главные характеристики Big Data
a. Огромный объем данных, скорость обработки больших данных, скорость появления новых данных
b. Огромный объем данных, скорость анализа данных, скорость обработки данных
c. Огромный объем данных, достоверность данных, ценность накопленной информации
d. Огромный объем данных, сложность типов данных и их структуры, скорость появления новых данных
4. Что не относится к неструктурированной информации?
b. Текстовые документы
d. Аудио-контент
5. Какие из задач решаются Big Data?
a. Мониторинг оборудования
b. Анализ социальных сетей
c. Оптимизация автомобильного движения
d. Все вышеперечисленное
6. Данные текстовых файлов с определенными паттернами для их обработки (Например: XML) являются
d. Неструктурированными
7. Данные имеющие определенный тип, формат и структуру (Например: Транзакционные данные) являются
d. Квазиструктурированными
8. Данные, у которых нет строго зафиксированного формата (Например: Текстовые документы, PDF, изображения и видеозапись) являются
d. Структурированными
9. Когда BigData становится проблемой?
a. Когда требуется анализ и выявление закономерностей
b. Все вышеперечисленное
c. Когда требуется хранить и осуществлять поиск
d. Когда требуется провести сложные вычисления
10. Размер больших данных определяется от…
a. Нескольких десятков зетабайт
b. Нескольких десятков терабайт
c. Нескольких десятков петабайт
d. Нескольких десятков гигабайт
11. Принцип 3Vs расшифровывается как
a. Value, Variety, Velocity
b. Volume, Veracity, Velocity
c. Volume, Variety, Velocity
d. Value, Veracity, Velocity
12. Какие понятия содержит в себе принцип трех «V»?
a. Volume, Variety, Virtuality
b. Volume, Variety, Velocity
c. Velocity, Volume, Verbosity
a. Проблема хранения и обработки гигантских объемов данных
b. Все вышеперечисленные определения
c. Данные, которые связаны с высокой изменчивостью источников данных и сложностью взаимосвязей
d. Комплексный набор методов обработки данных колоссальных объемов
14. Закончите следующее предложение: «С точки зрения машины, информация становится структурированной, если.
a. Машина проинструктирована, каким образом её обрабатывать
b. Информация разделена на части и озаглавлена
c. Информация имеет логическую взаимосвязь внутри себя
d. Машина знает из каких частей состоит информация
15.Какое из нижеперечисленных понятий не относится к перечню необходимых критериев для создания проекта, связанного с Большими данными?
a. Географическое положение
c. Гибкость анализа
d. Скорость принятия решения
16.Чем характеризуются «Большие данные»?
a. Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
b. Большой объем, высокая скорость поступления и выбытия данных и большое их разнообразие
c. Всем вышеперечисленным
d. Данные больших размеров, высокой изменчивости, и большого разнообразия
17.Что из этого не относится к четырем основным типам данных?
a. Quasi-Structured Data
c. Semi-Structured Data
d. Unstructured Data
18. Кто и в каком году впервые ввел термин «Big Data»?
a. Разработчик компании Google в 2009 году
b. Инженер компании Amazon в 2006 году
c. Клиффорд Линч, редактор журнала Nature, в 2008 году
d. Профессор Стэнфордского университета в 2007 году
19. BigData – это…
a. Класс в Java, предназначенный для хранения данных от 100 Гб
b. Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
c. Колоссальный объем данных, собранных человечеством
d. Представление фактов, понятий или инструкций в форме, приемлемой для интерпретации, или обработки
20.Какая из характеристик не является основной для «Больших данных»?
d. Скорость
21. Основные отличительные особенности BigData?
a. Традиционные технологии хранения
b. Большой объем информации
c. Распределенный подход к обработке
d. Фиксированный набор истоков данных
22. Какой из ниже перечисленных принципов работы не применятся к Big Data?
b. Вертикальная масштабируемость
c. Локальность данных
d. Горизонтальная масштабируемость
23. Какие данные имеют наибольший объем на сегодняшний день?
d. Неструктурированные
24. Что означает термин «Big Data» в информационных технологиях?
a. Комплексный набор методов обработки структурированных и неструктурированных данных колоссальных объемов
b. Представление времени, дня, месяца и года в качестве значения количества миллисекунд, прошедших с начала нашей эры
c. Файлы с большим количеством данных
d. Комплексный набор методов для создания файлов большого объёма
25. Текстовые данные с неустойчивым форматом, которые для обработки инструментами требуют больших временных затрат на преобразование (Например: Web) являются
d. Неструктурированными
26. Рост объема данных имеет…
a. Экспоненциальный характер
b. Линейный характер
c. Циклический характер
d. Неопределенный характер
27. Выберите верную зависимость структурированности информации от её объема
a. Чем больше объем, тем более структурирована информация
b. Чем больше объем информации, тем менее она структурирована
c. Чем меньше объем, тем менее структурирована информация
d. Они не зависят друг от друга
7.3. Облачные технологии для цифровой трансформации
1. Какой из облачных финансовых сервисов S/4HANA помогает сопоставить счета и поступившую оплату?
a. SAP S/4HANA Cloud for customer payments
b. SAP S/4HANA Cloud for credit integration
c. SAP S/4HANA Invoice Matching
d. SAP Cash Application
2. Что из ниже перечисленного является характеристикой ERP-системы нового поколения S/4HANA?
a. Тесная интеграция с бизнес-сетями контрагентов
b. Возможности по реализации новых бизнес-моделей
c. Возможности корректировки произведенных финансовых проводок без отражения в базе данных
d. Сочетание транзакционной и аналитической систем
3.Что входит в функциональность SAP Ariba – облачного решения SAP по управлению взаимоотношениями с поставщиками?
a. обмена электронными документами и выставления счетов
b. просмотра данных о поставщиках и общения с ними до проведения тендеров
c. создание электронно-цифровой подписи организации для взаимодействия с контрагентами
d. выбора товара или услуги из каталогов
4. Что НЕ относится к основным HR-функциям, автоматизацию которых обеспечивает SAP SuccessFactors?
a. управление карьерой и преемственностью
b. анализ профилей кандидатов в соцсетях
d. управление вознаграждениями
5. Благодаря интегрированному подходу к планированию на базе SAP IBP компании достигают существенных выгод (укажите все верные варианты):
а. Сокращение затрат на логистику
b. Увеличение выручки
c. Снижение штрафов за нарушение правил безопасности на производстве
d. Сокращение запасов
6. Какая из составляющих SAP IBP позволяет сформировать оптимальные планы по всей цепочке поставок (максимизация прибыли или минимизация затрат) и быстро корректировать их, чтобы вовремя реагировать на постоянно меняющийся современный мир?
Supply Chain Control Tower (Центр управления цепочкой поставок на основе КПЭ)
b. IBP for Response and Supply (IBP для управления реагированием и поставками)
c. IBP for Demand (IBP для управления спросом)
d. IBP for Inventory (IBP для управления запасами)
7. Что из ниже перечисленного НЕ является характеристикой ERP-системы нового поколения S/4HANA?
а. Работа по огромному массиву данных в режиме реального времени
b. Переключение фокуса работы с крупных поставщиков или клиентов компании на конечного потребителя продукции или услуги
c. Возможности по реализации новых бизнес-моделей
d. Возможности корректировки произведенных финансовых проводок без отражения в базе данных
8. В чем состоит особенность облачных финансовых сервисом S/4HANA?
а. могут заменить финансовую функциональность ядра S/4HANA
b. гарантируют получение экономического эффекта от внедрения S/4HANA
c. точечно встраиваются в те функции, которые необходимо автоматизировать, не оказывая воздействия на весь сквозной процесс управления финансами
d. точечно встраиваются в те функции, которые необходимо автоматизировать и при этом дополняют и улучшают весь сквозной процесс управления финансами
9. В чем состоят преимущества использования SAP Ariba?
a. Увеличение объема закупок контрагентов
b. Сокращение сроков поставок
c. Сокращение запасов готовой продукции
d. Сокращение затрат на обслуживание поставщиков
10. Какая из составляющих SAP IBP позволяет поддерживать поддерживает процесс планирования продаж и операций, делая его легким, быстрым и точным?
a. IBP for Demand (IBP для управления спросом)
b. IBP for Response and Supply (IBP для управления реагированием и поставками)
c. IBP for Sales & Operation Planning (IBP для планирования продаж и операций)
d. IBP for Inventory (IBP для управления запасами)
11. Преимущества использования облачных технологий:
a. Перевод капитальных затрат на ИТ в операционные
c. Облачные технологии помогают перейти к новым бизнес-моделям
d. Возможность отдать непрофильные активности и сконцентрироваться на ключевой деятельности
12. Какая из составляющих SAP IBP обеспечивает глобальную прозрачность цепочки поставок на основе КПЭ?
a. Supply Chain Control Tower (Центр управления цепочкой поставок на основе КПЭ)
b. IBP for Demand (IBP для управления спросом)
c. IBP for Inventory (IBP для управления запасами)
d. IBP for Response and Supply (IBP для управления реагированием и поставками)
13. Какая функциональность обеспечивается ядром, а не облачными микро-сервисами S/4HANA?
a. Управление контрактами
b. Обеспечение доступа клиентов к своим счетам
c. Управление оборотным капиталом
d. Проверка кредитного лимита
14. Какие два блока представлены в бимодальной архитектуре интеллектуального предприятия, предлагаемого компанией SAP?
a. MES-cистема и CAD-система
b. Транзакционная система и платформа создания инноваций
c. Облачная платформа и хранилище данных
d. Транзакционная и аналитическая система
15. Что из нижеперечисленного не является преимуществом облачной модели:
a. сокращение издержек, капитальных и операционных затрат на ИТ
b. рост выручки компании
c. гибкость, масштабируемость ИТ-инфраструктуры
d. экономия на сроках внедрения ИТ-решения
Выберите один ответ:
Тема 8. Инструменты управления цифровой компанией
8. Системы управления цифровой компанией.
1. Что из перечисленного определение наиболее верно определяет понятие MRP (ППМ)?
a. Планирование всех ресурсов предприятия
b. Планирование потребностей в материалах
c. Управление закупками
2. Какие системы можно отнести к цифровому ядру компании?
b. Системы для разработки
d. MES
3. Какие процессы поддерживает модуль Сбыт?
a. Закупка товаров и услуг
b. Отгрузка и транспортировка
c. Создание и отслеживание заказа клиента
d. Планирование производства
4. Какие из приведенных ниже элементов являются организационными уровнями?
a. Балансовая единица
d. Заказ на закупку
5. Какое утверждение верно относительно MRP-II?
a. Это система планирования всех ресурсов и процессов предприятия
b. Это система планирования производственных ресурсов
6. Что из перечисленного ниже может является типом ППМ?
a. Укрупнение планирование сбыта
b. Регулируемое расходом планирование
c. Детерминированное планирование
d. Планирование определимое как результат ППМ
7. Какой интерфейс выглядит одинаково на всех устройствах (компьютер, планшет, смартфон)?
c. Web интерфейс
8. Верно ли следующее утверждение: Организационные элементы определяют структуру предприятия в SAP ERP
Неверно
9. В каких основных данных перечислены этапы и последовательность этапов, необходимых для производства материала?
b. Основная запись материала
d. Технологическая карта
10. Что является ключевым объектом управления в ERP системах?
c. Люди
11. Верно ли следующее утверждение: В SAP ERP возможно ведение бухгалтерского учета параллельно по нескольким стандартам.
Неверно
12. Что из перечисленного является ключевыми особенностями S/4 HANA?
a. Техзвенная архитектура
b. Наличие сервера баз данных
c. Вычисление бизнес задач на уровне базы данных
d. Встроенный искусственный интеллект
13. Что верно относительно создания заказа клиента?
a. Данные клиента автоматически копируются из основных данных клиента, нужно только ввести номер (код) клиента
b. При вводе заказа клиента нужно вводить все данные клиента
14. Какая техническая причина заставляет производителей ИТ систем переходить на базы данных в памяти?
a. Низкая скорость доступа к данным на дисках
c. Низкая скорость доступа к данным в кэш-памяти
15. Какой организационный уровень в SAP ERP является самым верхним?
c. Завод
16. Что такое Балансовая единица?
a. Это организационный уровень определяющий зону ответственности в сбыте
b. Это отдельная отчетная единица соответствующая юридическому лицу
c. Это единица оборудования, поставленная на баланс
17. С чем из перечисленного может быть связно возникновение первичных потребностей?
a. С заказом клиента
b. С возможностями закупок
c. С мощностью производства
18. Какие операции поддерживает процесс закупок?
a. Отгрузка получателю
c. Создание и отслеживание заказов на поставку
e. Транспортировка товаров
19. В SAP ERP ведется планирование мощностей, где содержится информация об имеющихся мощностях?
b. Таблица планирования
c. Завод
20. Ниже указан последовательность событий, связанная с планированием производства, какая верная?
a. ППМ- Потребность- Плановый заказ – Заказ клиента
b. Заказ клиента – Потребность – ППМ – Плановый заказ
c. Потребность – Плановые заказ – ППМ – Заказ клиента
21. Какое утверждение верно описывает Плановые первичные потребности?
a. Потребности в сырье и полуфабрикатах для производства конкретного изделия
b. Потребности связанные с планирование производства
c. Потребности, возникшие в результате прогона ППМ
22. Ниже указана последовательность процесса закупки, какая из них верная?
a. Заявка – поступление фактуры – заказ на закупку- поступление материала- платеж поставщику
a. НСИ содержит в себе данные, которые нужно хранить централизованно с целью многократного повторного использования
b. НСИ содержит сгруппированные по смыслу данные для разового использования
c. НСИ фиксирует в себе факты проводок
24. В чем из нижеперечисленного содержится информация о компонентах из которых состоит материал?
Анализ неструктурированных данных и оптимизация их хранения
Тема анализа неструктурированных данных сама по себе не нова. Однако в последнее время в эпоху «больших данных» этот вопрос встаёт перед организациями гораздо острее. Многократный рост объёмов хранимых данных в последние годы, его постоянно увеличивающиеся темпы и нарастающее разнообразие хранимой и обрабатываемой информации существенно усложняют задачу управления корпоративными данными. С одной стороны, проблема имеет инфраструктурный характер. Так, по данным IDC, до 60% корпоративных хранилищ занимает информация, не приносящая организации никакой пользы (многочисленные копии одного и того же, разбросанные по разным участкам инфраструктуры хранения данных; информация, к которой никто не обращался несколько нет и уже вряд ли когда-нибудь обратится; прочий «корпоративный мусор»).

С другой стороны, неэффективное управление информацией ведёт к увеличению рисков для бизнеса: хранение персональных данных и прочей конфиденциальной информации на общедоступных информационных ресурсах, появление подозрительных пользовательских зашифрованных архивов, нарушения политик доступа к важной информации и т.д.
В этих обстоятельствах умение качественно анализировать корпоративную информацию и оперативно реагировать на любые несоответствия её хранения политикам и требованиям бизнеса является ключевым показателем зрелости информационной стратегии организации.
Теме аналитики файловых данных посвящён отдельный документ Gartner, вышедший в сентябре 2014 г. под названием «Market Guide for File Analysis Software». В данном документе приводятся следующие типовые сценарии использования аналитического ПО:
В данной статье будет сделан технический обзор обоих продуктов.
HP Storage Optimizer: анализ данных с целью оптимизации их хранения
HP Storage Optimizer объединяет в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения.

Архитектура HP Storage Optimizer
Источники анализируемой информации в терминологии HP Storage Optimizer называются репозиториями. В качестве репозиториев поддерживаются различные файловые системы, а также MS Exchange, MS SharePoint, Hadoop, Lotus Notes, Documentum и многие другие. Есть также возможность заказать разработку коннектора к репозиторию, который в настоящее время не поддерживается продуктом.
HP Storage Optimizer использует собственные соответствующие коннекторы для обращения к анализируемым репозиториям. Информация с коннекторов поступает в компонент под названием Connector Framework Server (обозначенный как «CFS» на картинке), который, в свою очередь, обогащает её дополнительными метаданными и направляет получившиеся данные на индексирование. Для повышения отказоустойчивости и балансировки нагрузки при взаимодействии приложения с коннекторами используется компонент Distributed Connector.
Метаданные индексируются «движком» HP Storage Optimizer Engine («SO Engine» на первой картинке) и помещаются в БД MS SQL. Для доступа к результатам анализа и назначения политик управления используется веб-приложение HP Storage Optimizer.
Для наглядного отображения информации, потенциально подлежащей оптимизации, в HP Storage Optimizer используются круговые диаграммы (ниже), показывающие дубликаты данных, редковостребованные и «ненужные» данные (ROT analysis: Redundant, Obsolete, Trivial). Критерии «редковостребованности» и «ненужности» можно гибко настроить, в том числе индивидуально для каждого репозитория. Кроме круговых диаграмм, доступны графики, иллюстрирующие разбивку данных по типам, времени и частоте добавления и др. Все элементы визуализации интерактивны, т.е. позволяют переходить в какую-либо категорию диаграммы (или столбец) и получать доступ к соответствующим данным.
Графический анализ данных в HP Storage Optimizer
Перечень метаданных, по которым может быть проведён анализ, необычайно широк и даёт возможность осуществлять высокоточные тематические выборки.
Пример работы с метаданными в HP Storage Optimizer
Хотелось бы заметить, что в состав продуктов HP Storage Optimizer и HP Control Point входит «движок» индексирования и визуализации, позволяющий просматривать более 400 различных форматов данных без установки на сервер соответствующих приложений для предпросмотра. Это значительно упрощает и ускоряет процесс анализа большого количества разноплановой информации.
После того как анализ данных проведён, администратору системы предоставляется возможность назначить политики удаления или перемещения данных. Политики на те или иные выборки данных возможно назначать как вручную, так и автоматически. Мощная ролевая модель управления, реализованная в HP Storage Optimizer и в HP Control Point, даёт возможность выдавать полномочия по работе с репозиториями, анализу данных в них, а также по назначению политик, максимально гибко.
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.
Продукт позволяет проводить анализ информации не только по метаданным, но и по её содержимому. Кроме того, в нём реализованы дополнительные механизмы анализа данных и назначения политик по работе с ними.
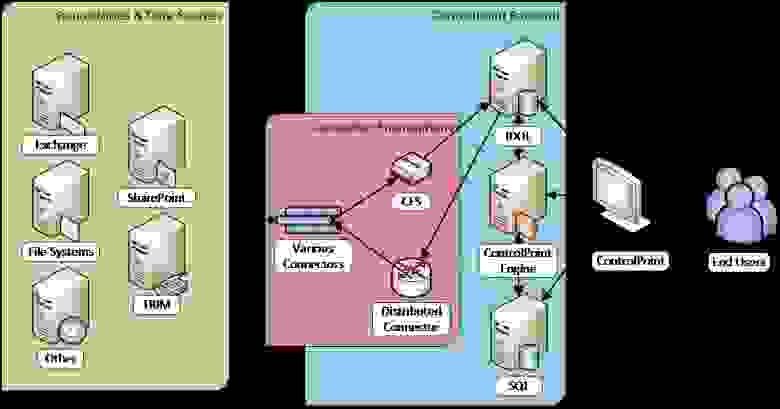
Архитектура HP Control Point
В отличие от HP Storage Optimizer, в HP Control Point широко используются возможности индексирования и смысловой категоризации информации «движка» HP IDOL (Intelligent Data Operating Layer): визуализация, категоризация, тэгирование и др. В его основе лежит возможность определять «смысл» набора анализируемой информации независимо от её формата, языка и т.д.
В частности, в HP Control Point дополнительно доступны два типа визуализации информации: кластерная карта и спектрограф. Кластерная карта представляет собой двухмерное изображение информационных «кластеров». Один кластер объединяет в себе информацию, имеющую схожий смысл. Таким образом, глядя на кластерную карту, можно быстро получить понимание основных смысловых групп этой информации. Кластерные карты интерактивны, т.е. позволяют с помощью кликов на те или иные кластеры получать доступ к информации, содержащейся в них.
Внешний вид кластерной карты в HP Control Point
Спектрограф представляет собой набор информационных кластеров, снятых в различные моменты времени и даёт возможность графически отследить, как менялся смысл информации в анализируемых репозиториях с течением времени.
Внешний вид спектрограммы в HP Control Point
Помимо расширенных возможностей визуализации информации, в HP Control Point доступна возможность категоризации анализируемой информации. Изначально информация категоризируется автоматически – средствами HP IDOL, выдавая пользователю системы массив данных, разбитый на смысловые части. Получив первичное разбиение, аналитик далее может сделать более выверенную категоризацию. Например, использовать какой-либо набор файлов, заведомо для аналитика релевантных той или иной категории, для «тренировки» категории на этот набор файлов, чтобы впоследствии получать более точные результаты категоризации. Для ещё более тонкой настройки можно использовать индивидуальные весовые коэффициенты файлов и даже фраз и отдельных слов внутри файлов, отражающие степень соответствия тех или иных единиц информации «тренируемой» категории. Такая детализация может использоваться, например, для создания подробных правил отнесения анализируемой информации к разряду конфиденциальной.
Что касается политик работы с анализируемой информацией, то в HP Control Point кроме копирования, переноса и удаления доступны также следующие опции:
– «Заморозка» объектов. Позволяет заблокировать доступ к отдельным объектам, не допуская их несанкционированное изменение или удаление.
– Создание рабочего процесса (workflow). Например, информирование или запрос утверждения уполномоченного сотрудника или владельца анализируемых объектов перед их переносом или удалением.
– Безопасный перенос в систему управления корпоративными записями HP Records Manager (например, в случае выявления несанкционированного присутствия конфиденциальных документов на общедоступном файловом сервере). При этом переносимые данные сопровождаются метаданными, которые будут использованы для дальнейшего управления документами в системе HP Records Manager с необходимыми настройками доступа, уровнями секретности и т.п.
Заключение
Как видно из текущего обзора, спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.
Автор статьи – Максим Луганский, технический консультант, Data Protection & Archiving, HP Big Data


